2023-06-15: A Milestone Achieved: Completing my Master's Degree and Advancing to PhD Candidacy
In the Fall of 2019, I joined the WS-DL (Web Science and Digital Libraries) research group at Old Dominion University as a Master’s student under the supervision of Dr. Michele C. Weigle and Dr. Michael L. Nelson. During my master's degree, I was on the thesis option (24 coursework credits, 6 research credits, a thesis, and a thesis defense). As I progressed through my courses and research, I discovered my passion for studying and research and I realized that I wanted to continue my academic journey and pursue a PhD. I reached out to my MS thesis advisor, Dr. Weigle, to express my strong interest in pursuing a PhD within the exceptional WS-DL group. I applied to the PhD program at ODU and was thrilled to be accepted for the Fall 2020 semester. Since then, I have been a dual-status MS and PhD student, I have been working on completing my Master's thesis while also advancing my PhD studies.

My master’s thesis is titled "Supporting Account-based Queries for Archived Instagram Posts". This topic crossed our path during our preliminary research on Instagram content in web archives, fueled by our interest in the platform. We conducted several early studies, such as "How well is Instagram archived?" which evolved from a class project in Dr. Nelson's Web Archiving Forensics course, and "Creation Time and Published Time Are Not the Same: Estimating the Instagram Epoch" aimed at estimating the Instagram epoch value. Our research on Twitter web archiving had been extensive, and we observed how comparatively under-studied Instagram was. During one of my weekly meetings with Drs. Weigle and Nelson, we discovered that the post owner's username is not included in the post URL on Instagram. Figure 2 illustrates the distinct difference in URL structure among the three social media platforms: Facebook, Twitter, and Instagram. While Facebook and Twitter include the usernames of post owners in their individual post URLs, Instagram does not incorporate usernames in its URLs. This is the root cause of the problem I have explored in the thesis.

Figure 2: While usernames are retained on Facebook and Twitter for individual posts, they are not available on Instagram.
The most popular method for searching for content in web archives like the Internet Archive is to use the URL of a particular web resource as the lookup key in the search bar. An archived web page, or memento (URI-M), is a snapshot of an original resource (URI-R) captured by a web archive at a fixed moment in time (Memento-Datetime). A list of URIs for mementos of the original resource is referred to as the TimeMap (URI-T). As a result of not knowing the URL of the resource (post URL), there is a lot of Instagram web content preserved in web archives that the user is unable to discover. The CDX is a type of index used in the field of web archiving that provides a simple representation of metadata from all records in an archive. CDX files are created as an index of generated WARC files. The CDX server can be used to list every URI-M in the Internet Archive index for a given URI-R. We can use the CDX API to return results matching a specific “prefix”'. For Facebook, a CDX prefix query http://web.archive.org/cdx/?url=facebook.com/{username}/posts/&matchType=prefix would provide the web archive user with all the available Facebook status posts that belong to a particular user (Figure 3). Similarly for Twitter, a simple CDX prefix query http://web.archive.org/cdx/?url=twitter.com/{username}/status/&matchType=prefix would help a web archive user to identify all the available Twitter status posts that belong to a particular user (Figure 4). However, there is no left-to-right hierarchical construction of URLs on Instagram. There is no way to query for URI-Ms of all of the posts associated with a specific Instagram account without knowing their URLs.
$ curl -s "http://web.archive.org/cdx/search/cdx?url=https://www.facebook.com/katyperry/posts/&matchType=prefix" | head -2
com,facebook)/katyperry/posts/10150201275371466 20160305122514 http://www.facebook.com/katyperry/posts/10150201275371466 text/html 302 3I42H3S6NNFQ2MSVX7XZKYAYSCX5QBYJ 492
com,facebook)/katyperry/posts/10150295888246466 20111015052123 http://www.facebook.com/katyperry/posts/10150295888246466 text/html 200 TPOUCAFF7PUU34UHMYJCY42KI66HRPSH 13489
Figure 3: A CDX “Prefix” Query for Facebook Posts
$ curl -s "http://web.archive.org/cdx/search/cdx?url=https://twitter.com/katyperry/status/&matchType=prefix" | head -1944 | tail -2
com,twitter)/katyperry/status/1068587128974524416 20211130163200 https://twitter.com/katyperry/status/1068587128974524416 text/html 200 DDX4LIM5MF5XSEEMLJVZOW4S5TW7DACL 8799
com,twitter)/katyperry/status/1068608473913409536 20181130221008 https://twitter.com/katyperry/status/1068608473913409536 text/html 200 JLB2P6ECZL23CCFCKXLMBGQNCVQ4F3M4 64450
Figure 4: A CDX “Prefix” Query for Twitter Posts (Tweets)
To solve this problem, we proposed two approaches.
1. The first approach uses existing technologies in the Internet Archive by using WARC revisit records to incorporate Instagram usernames into the WARC-Target-URI field in the WARC file header. The process of using revisit records to automatically enable prefix search for discovering Instagram posts belonging to a particular account is illustrated in Figure 5.
2. The second approach involves building an external index that maps Instagram user accounts to their posts. The user can query this index to retrieve all post URLs for a particular user, which they can then use to query web archives for each individual post. The techniques that we are proposing to fill the index are summarized in Figure 6.

Figure 5: Summary of the process involved in demonstrating prefix search for Instagram top-level post queries through the use of revisit records.

Figure 6: The techniques that can be used to populate the proposed secondary index.
Our implementation of various approaches has successfully demonstrated facilitating the discovery of archived Instagram posts belonging to a specific user.
Other interesting findings:
* By analyzing the server access logs of the Internet Archive from 2011 to 2021 (the first Thursday of February each year), we observed a growing trend in the number of requests for the Instagram domain, particularly until 2020 (Figure 7). However, the percentage of the number of requests out of all requests remained below 0.2% each year.

Figure 7: The number of requests for the Instagram domain increased over the years, at least until 2020, but the percentage of requests for Instagram is still less than 0.2% each year compared to the total number of raw access logs.
* The number of requested posts has consistently increased from 2013 to 2021, with a significant surge in 2021 compared to 2020 (Figure 8).
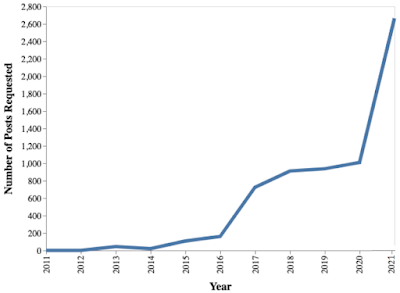
Figure 8: There is a steady increase in the number of posts requested each year from 2013 to 2021, with a notable surge in 2021.
* The majority of web archive users request mementos of Instagram posts that are created recently. For the years 2013 to 2017 (Figure 9 - left), 50% of the requests were for posts created within one year prior to the access logs' datetime. For the years 2018 to 2021 (Figure 9 - right), 50% of requests were for posts created within two years prior to the access logs' datetime.
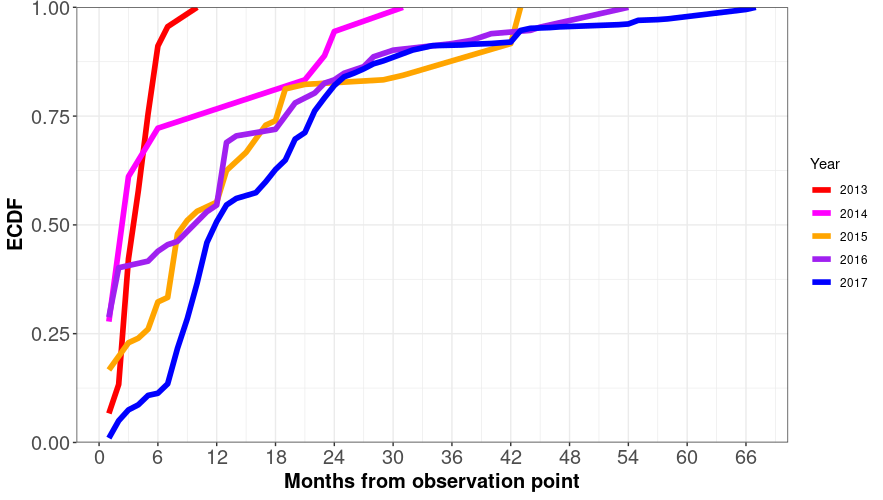

Figure 9: The majority of web archive users request mementos of Instagram posts that are created recently.
I'm thrilled to share that I successfully defended my MS thesis on "Supporting Account-based Queries for Archived Instagram Posts". Check out this thread for a summary.
— Himarsha R. Jayanetti (@HimarshaJ) April 19, 2023
Big thanks to my committee: Drs. @weiglemc, @phonedude_mln, & @Faryane!@WebSciDL @oducs #WebArchiveWednesday pic.twitter.com/uNUm7SBc0S
What lies ahead for me? My next step is to shift my focus toward my doctoral dissertation. The knowledge and skills I have acquired through working on multiple research projects, completing my MS thesis, and publishing papers have only strengthened my desire to further engage in the academic world of learning and research. I am beyond excited to continue my doctoral research with the WS-DL research group, where the perfect blend of excellence, experience, and infectious awesomeness of faculty and students awaits!
-- Himarsha R. Jayanetti
Semester Highlights: Projects, Publications, Blogs, and Awards
Since I enrolled in the MS program in the Fall of 2019, I have accomplished the following academic milestones:

Figure 10: My avatar on the PhD crush board of our group reflecting the progress in WS-DL style ✨
Throughout the period spanning from the Fall of 2019 to the present, I published several research papers. Specifically, I have contributed 7 conference papers, 2 workshop papers, and 2 posters to the scholarly community. Additionally, there are two journal papers that are under review.
I have also produced 12 blog posts in the WS-DL blog:
12. 2022-12-21: PDFServer - Our Summer Internship at LANL - with Yasith Jayawardana and Gavindya Jayawardena
Additionally, our research group acknowledges student callouts by name on the DSHR’s blog while at ODU, and I was honored to receive two mentions alongside Kritika for our work on archiving Twitter.
2. 2021-02-11: More On Archiving Twitter
I would like to express my deepest appreciation to my collaborators, as well as the entire WS-DL group, including both current members and esteemed alumni (WS-DL for life!). I would also like to express my heartfelt gratitude to my advisors, internship supervisors, and all faculty members for their invaluable guidance and the opportunities they extend to students.
Comments
Post a Comment