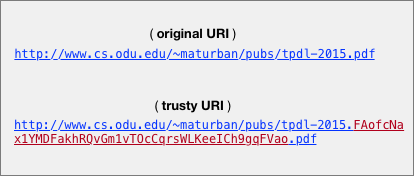
2025-02-11: Getting to the Source of the (Memento) Damage

I've previously written about the Memento Damage project, originally started by Dr. Justin Brunelle , a Web service designed to estimate the amount of damage to a web archive by assessing it's missing resources. Previously, I had been specializating some of the project while working on the Memento Tracer project, funded by the Alfred P. Sloan Foundation , to take special considerations regarding the damage weighting for Web hosted repository pages. I have been making further updates to the Memento Damage project over the course of this year that helps improve this analysis and damage estimation. The most prominent is the implementation of a secondary crawler component for analyzing an archived repository and its source tree. Web-hosted Git repositories are hosted on centralized Web platforms, the largest being GitHub along with other major platforms such as GitLab, Bitbucket, and Sourceforge. The source files for a Git project are hosted "behind the scen...