2021-01-22 Twitter rewrites your URLs, but assumes you’ll never rewrite theirs: more problems replaying archived Twitter

Figure 1: The tweet replayed in Internet Archives’s Wayback Machine has the t.co URI-M (“/web/20210106213519/https://t.co/Pm2PKV0Fp3”) displayed in the memento.
URLs shared on Twitter are automatically shortened to t.co links. Twitter does this to track its engagements and also protect its users from sites with malicious content. Twitter replaces these t.co URLs with HTML that suggests the original URL so that the end-user does not see the t.co URLs while browsing. When these t.co URLs are replayed through web archives, they are rewritten to an archived URL (URI-M) and should be rendered in the web archives as in the live web, without displaying these t.co URI-Ms to the end-user. However, as shown in Figure 1, the tweet replayed in Internet Archive’s Wayback Machine has the t.co URI-Ms (or at least the relative URL, “/web/20210106213519/https://t.co/Pm2PKV0Fp3”) displayed in the tweet itself.
We first noticed the t.co URL displayed in the memento while exploring the archived Twitter pages for one of our previous blog posts (“New Twitter UI: Replaying Archived Twitter Pages That Never Existed”). Figure 2 shows where “/web/20200916204940/https://t.co/qZ1OCJznjL" is displayed in one of the tweets itself. Note that the content of the memento from 2020-09-17T22:31:49Z varies depending on when it is replayed. Hence, you might see content different from what’s shown in the figure below, or more likely, you will see a failed memento with a Twitter error message. The reason for this issue is explored in detail in the aforementioned blog post.
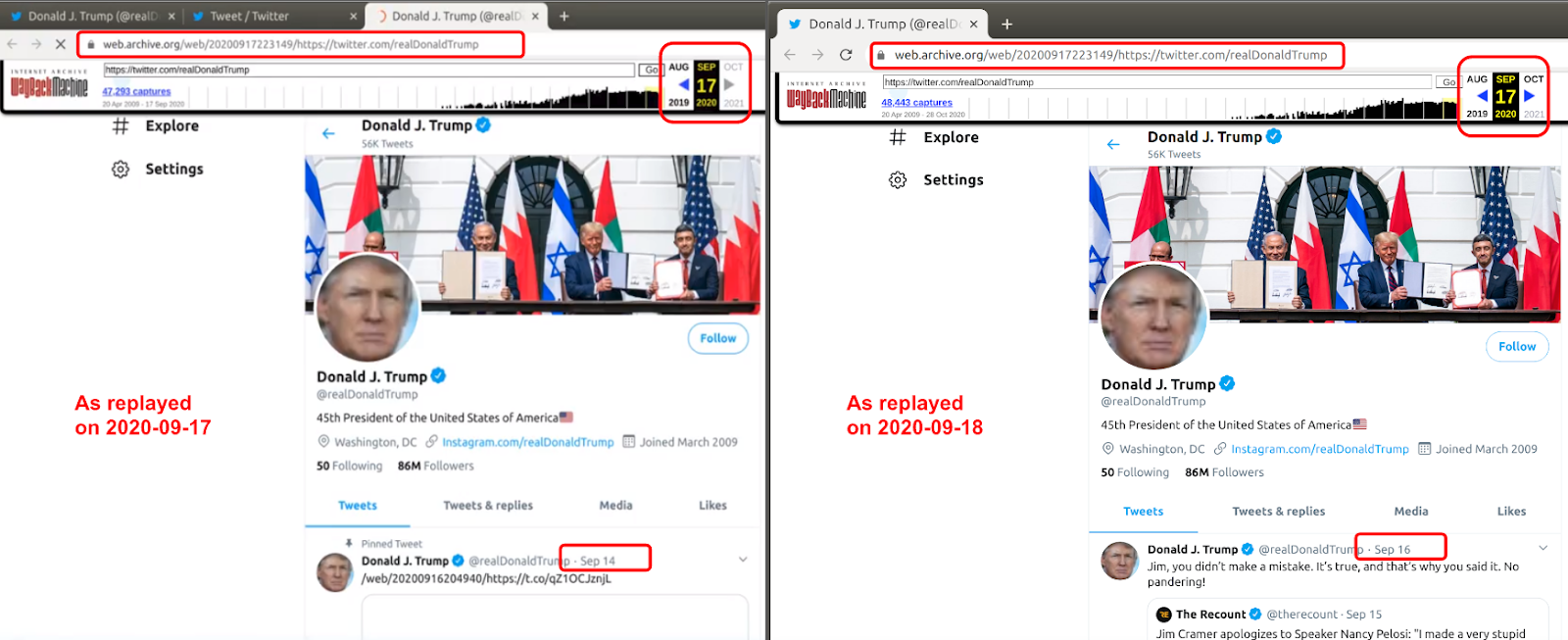
Figure 2: The memento with top tweet displaying t.co link when replayed on 2020-09-17 (left). Content on memento from 2020-09-17T22:31:49Z varies depending on when it was replayed. The same memento was displaying tweets from 2020-09-14T06:27:08Z when replayed on 2020-09-17 (left), and tweets from 2020-09-16T20:49:40Z when replayed on 2020-09-18 (right)
Looking at more archived Twitter pages, we uncovered additional examples of displaying the t.co URI-M. We believe that the cause of this issue lies in the server-side rewriting rules for JSON files. The t.co URL in the tweet JSON is rewritten to an archived URL on the server-side. Twitter's JavaScript expects URLs to be 23 characters long "t.co" links and is therefore unable to remove the complete archived URL from the text during the replay.
Different Cases
We explored the different scenarios of how this issue is triggered. We noticed that the t.co URI-Ms show up only in Twitter’s new UI mementos when a URL is shared as the tweet content.
Twitter stopped supporting its legacy user interface on June 1, 2020. The new structure of Twitter UI provides a template HTML and then the page is built with various JSON responses, as opposed to the old UI where most of the content was embedded in the root HTML. Since the structure of Twitter pages changed, it impacted the process of archival replay. Shown below are the different cases of this issue where the media URL is included in the tweet.
Shared Video
The following example illustrates this issue when a video is shared. Figure 3 shows two examples: the first tweet (left) shows a video shared with text, while in the second tweet (right) only the video is shared. As we can see, the archived t.co URL is displayed on top of the right tweet. This shows that if the text content of the archived tweet starts with a URL (whether it is a tweet or a retweet), then that rewritten t.co URI-M is displayed with the tweet.

Figure 3: Shared video with text in the tweet content (left tweet), which is also an RT does not display the t.co URI-M. The shared video without any other text as the tweet content (right tweet) displays the t.co URI-M.
Shared Image
A similar case can be seen when images are shared with no additional text. In Figure 4, the left image shows the tweet on the live web while the right image shows the replay of that tweet in the Wayback Machine. The left image shows how Twitter's JavaScript has rendered the t.co URL so that the URL itself is not displayed. The right image displays the new UI memento of the particular tweet with the rewritten t.co URI-M.
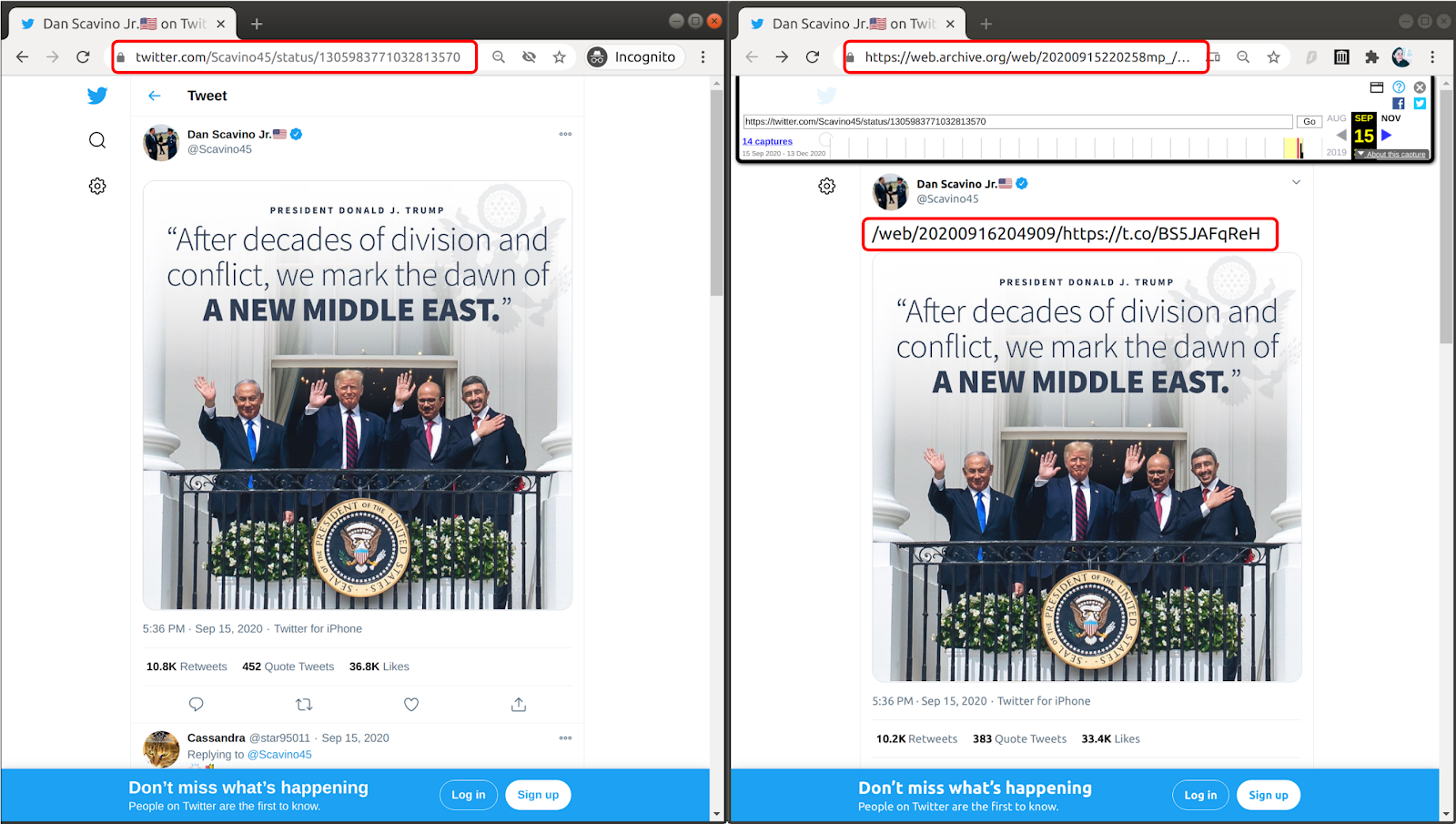
Figure 4: The tweet on the live web (left) and the replay of that tweet in the Wayback Machine (right).
The problem of t.co URI-M displaying in the memento persists in the case of the retweet as well. If the tweet with a shared image is retweeted, that retweet will have the t.co URL as well (Figure 5).

Figure 5: The t.co URI-M is displayed in the memento where a tweet with a shared image is retweeted.
Tweet JSON Example
We further looked into the JSON responses of the archived tweets to understand the root cause of the issue. Below, we compare the JSON responses of two types of tweets:
Tweet with only a URL
Tweet with text followed by a URL
A snippet of the JSON response for the first type of tweet with only a URL as the tweet body is shown below (Figure 6). We noticed that the full-text key in the JSON response of the tweet contains the rewritten t.co URL as its value.
$ jq .globalObjects."tweets"['"1305983771032813570"'] Tweet_onlyURL.json | head -50
{
"created_at": "Tue Sep 15 21:36:09 +0000 2020",
"id_str": "1305983771032813570",
"full_text": "https://web.archive.org/web/20200916204909/https://t.co/BS5JAFqReH",
"display_text_range": [
0,
0
],
"entities": {
"media": [
{
"id_str": "1305983691840200707",
"indices": [
0,
23
],
"media_url": "https://web.archive.org/web/20200916204909/http://pbs.twimg.com/media/Eh_JP5KWoAMvjKx.jpg",
"media_url_https": "https://web.archive.org/web/20200916204909/https://pbs.twimg.com/media/Eh_JP5KWoAMvjKx.jpg",
"url": "https://web.archive.org/web/20200916204909/https://t.co/BS5JAFqReH",
"display_url": "pic.twitter.com/BS5JAFqReH",
"expanded_url": "https://web.archive.org/web/20200916204909/https://twitter.com/Scavino45/status/1305983771032813570/photo/1",
"type": "photo",
"original_info": {
"width": 2048,
"height": 2048,
"focus_rects": [
{
"x": 0,
"y": 0,
"h": 1147,
"w": 2048
},
{
"x": 0,
"y": 0,
"h": 2048,
"w": 2048
},
{
"x": 126,
"y": 0,
"h": 2048,
"w": 1796
},
{
"x": 512,
"y": 0,
"h": 2048,
"w": 1024
},
Figure 6: A snippet of the JSON response for a tweet with only a URL as the tweet body in the new Twitter UI. The jq command used for exploring this JSON is also listed above.
A snippet of the JSON response for the second type of tweet with text followed by a URL as the tweet body is shown below (Figure 7). The full_text key in the JSON response of the tweet contains the unrewritten t.co URL. In this case, the t.co URL is treated as a string at the server-side by the Wayback Machine and not as a URL to be rewritten.
$ jq .globalObjects."tweets"['"1305975008750194688"'] Tweet_textURL.json | head -50
{
"created_at": "Tue Sep 15 21:01:20 +0000 2020",
"id_str": "1305975008750194688",
"full_text": "After decades of division and conflict, we mark the dawn of a new Middle East. Congratulations to the people of Israel, the people of the United Arab Emirates, and the people of the Kingdom of Bahrain. God Bless You All! https://t.co/gpeqFDtr0S",
"display_text_range": [
0,
220
],
"entities": {
"media": [
{
"id_str": "1305974882103169026",
"indices": [
221,
244
],
"media_url": "https://web.archive.org/web/20200916204935/http://pbs.twimg.com/ext_tw_video_thumb/1305974882103169026/pu/img/9-7rUjOEtbcfpXU1.jpg",
"media_url_https": "https://web.archive.org/web/20200916204935/https://pbs.twimg.com/ext_tw_video_thumb/1305974882103169026/pu/img/9-7rUjOEtbcfpXU1.jpg",
"url": "https://web.archive.org/web/20200916204935/https://t.co/gpeqFDtr0S",
"display_url": "pic.twitter.com/gpeqFDtr0S",
"expanded_url": "https://web.archive.org/web/20200916204935/https://twitter.com/realDonaldTrump/status/1305975008750194688/video/1",
"type": "photo",
"original_info": {
"width": 1280,
"height": 720
},
"sizes": {
"thumb": {
"w": 150,
"h": 150,
"resize": "crop"
},
"medium": {
"w": 1200,
"h": 675,
"resize": "fit"
},
"small": {
"w": 680,
"h": 383,
"resize": "fit"
},
"large": {
"w": 1280,
"h": 720,
"resize": "fit"
}
}
}
]
Figure 7: A snippet of the JSON response for a tweet with text followed by a URL as the tweet body in the new Twitter UI. The jq command used for exploring this JSON is also listed above.
By looking at both of these cases, we presumed the reason for the t.co URI-M displaying in the memento depends on the value in the full_text field. The URL gets rewritten at the server-side by Wayback Machine when the full-text value contains only a URL. However, note that only “/web/20200916204909/https://t.co/BS5JAFqReH” is displayed in the tweet with "https://web.archive.org" stripped off of the URI-M (Figure 4). The indices object under the media entity is an array of integers that marks the start & end of the t.co URL in the full text. Twitter’s JavaScript makes sure to strip the text within these indices (t.co URL) while rendering the tweet. The length of a t.co URL is 23 characters and is a fixed value that will rarely change. Therefore, Twitter's JavaScript is removing only the first 23 characters from the much longer t.co URI-M. It just happens that the string length of "https://www.archive.org" is also exactly 23 characters.
01234567890123456789012
https://t.co/BS5JAFqReH
https://web.archive.org/web/20200916204909/https://t.co/BS5JAFqReH
We created a simpler test page with different test cases to better understand when and how this re-writing takes place.
Test JSON Example
We created a JSON file (Figure 8) with three different test cases:
Case 1: With only a URL present as the value.
Case 2: With a value starting with a URL followed by text.
Case 3: With a value starting with text followed by a URL.
$ curl https://www.cs.odu.edu/~hjayanet/testJSON/test.json
{
"Case_1": "http://www.cs.odu.edu/",
"Case_2": "http://www.cs.odu.edu This is text",
"Case_3": "This is text https://www.cs.odu.edu/"
}
Figure 8: The live test JSON example page consists of three different cases for field values.
We then archived this test page using the SPN web interface. Figure 9 shows the curl response for the test page memento without the archive banner. We made the following observations:
Case 1: Rewritten URL present as the value.
Case 2: Rewritten URL followed by text.
Case 3: Text followed by a URL (no change).
$ curl https://web.archive.org/web/20210106172027mp_/https://www.cs.odu.edu/~hjayanet/testJSON/test.json
{
"Case_1": "https://web.archive.org/web/20210106172027/http://www.cs.odu.edu/",
"Case_2": "https://web.archive.org/web/20210106172027/http://www.cs.odu.edu This is text",
"Case_3": "This is text https://www.cs.odu.edu/"
}
Figure 9: A memento of the test JSON example page (Figure 8) as captured on 2020-01-06T17:20:27Z shows the rewritten JSON without the banner (via "mp_").
As you can see, if the text content of the archived copy contains only a URL (Case 1) or if it starts with a URL (Case 2), then that URL is rewritten (https://web.archive.org/web/20210103224855/http://www.cs.odu.edu/). However, if the content starts with text (Case 3), the URL is not rewritten.
This is because of the aggressive rewriting of URLs of JSON on the server-side. For example, the archived JSON response in Figure 9 displays how the URLs in the first two cases were rewritten into URI-Ms on the server-side. The not rewritten version (“raw”) of the same JSON can be seen using the “id_” flag in the URI-M. Figure 10 shows the simplest not rewritten JSON (via "id_").
$ curl https://web.archive.org/web/20210106172027id_/https://www.cs.odu.edu/~hjayanet/testJSON/test.json
{
"Case_1": "http://www.cs.odu.edu/",
"Case_2": "http://www.cs.odu.edu This is text",
"Case_3": "This is text https://www.cs.odu.edu/"
}
Figure 10: A memento of the test JSON example page (Figure 8) as archived on 2020-01-06T17:20:27Z showing the un-rewritten version of JSON (via "id_").
We created two simple instances for building a slideshow to illustrate the trade-offs during the rewriting process. In the first case, the data is stored in the HTML page itself (Figure 11 and 12) which is similar to Twitter’s old UI where most of the content is embedded in the root HTML. The HTML <a> tag defines a hyperlink and the “href” attribute indicates the URL. The text enclosed between the <a> tag (anchor text) is what will be visible to the user which is the caption in our example. We have two such hyperlinked captions in the example (Figure 11) where the first caption is “Page 1 Title” and the destination link is “https://example.com/page-1.html”. However, in the second one, the caption is the same as the destination link which is “https://example.com/page-2.html“.
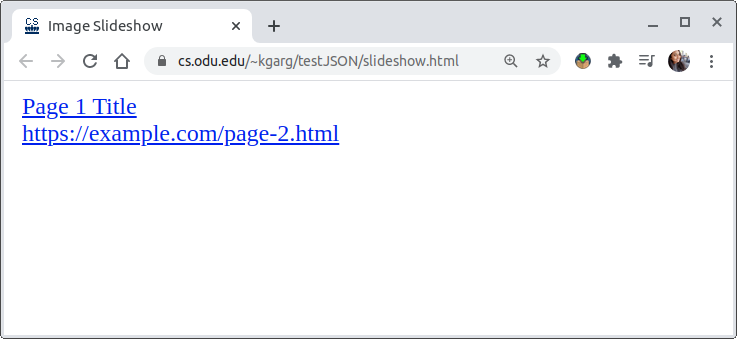
Figure 11: simple slideshow HTML page
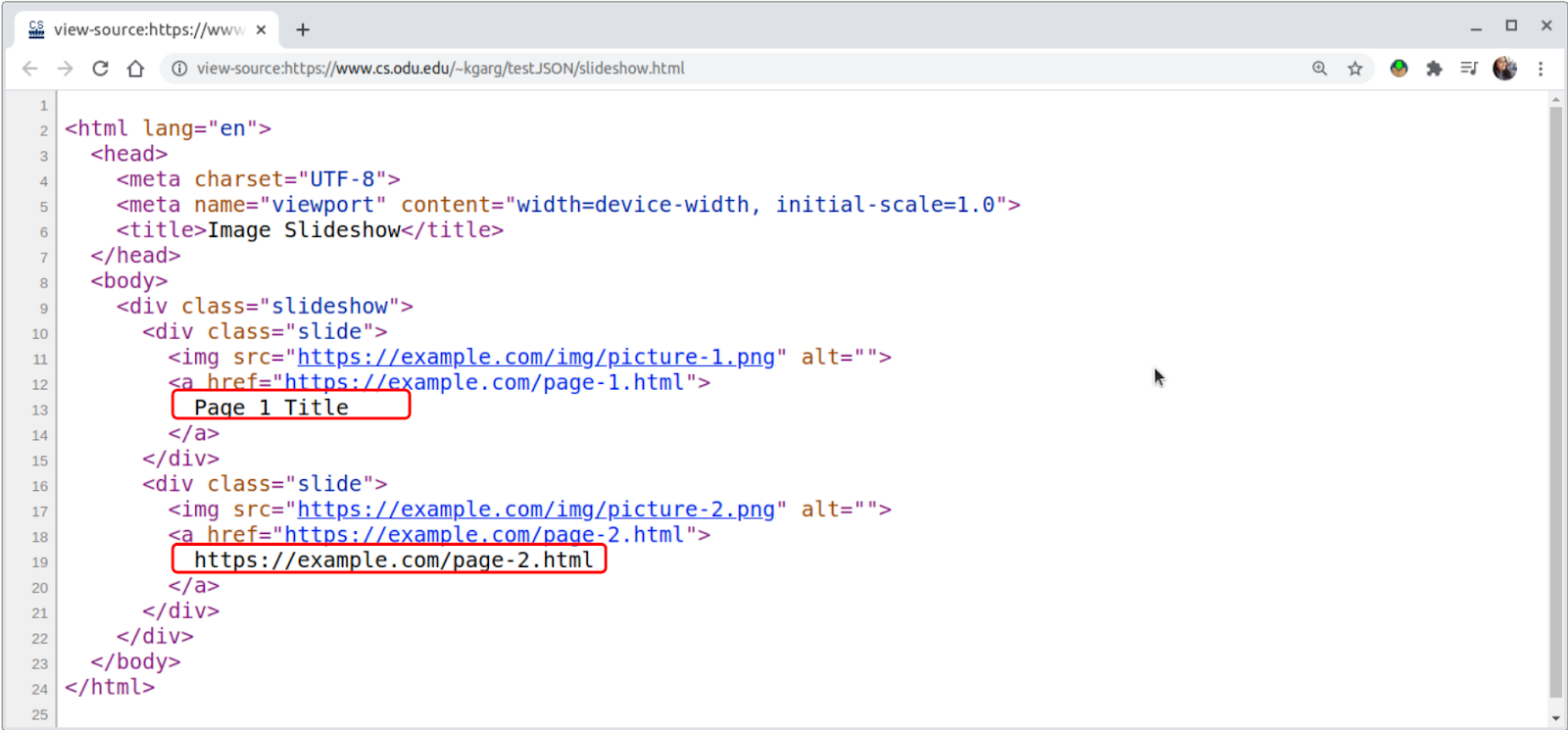
Figure 12: The source code of the simple slideshow HTML page
Let’s say we archive this simple HTML page and take a look at the source code to see how the rewriting has been done (Figure 13). We can see that the URLs are rewritten except for when it’s meant to be displayed as a caption. For example, the URL under the second “href” attribute (“https://example.com/page-2.html”) was rewritten (“http://web.archive.org/web/20210113130609/https://example.com/page-2.html”) whereas the caption under the <a> tag (“https://example.com/page-2.html”) is not rewritten. This is also the reason why this issue is not present in Twitter’s old UI mementos.
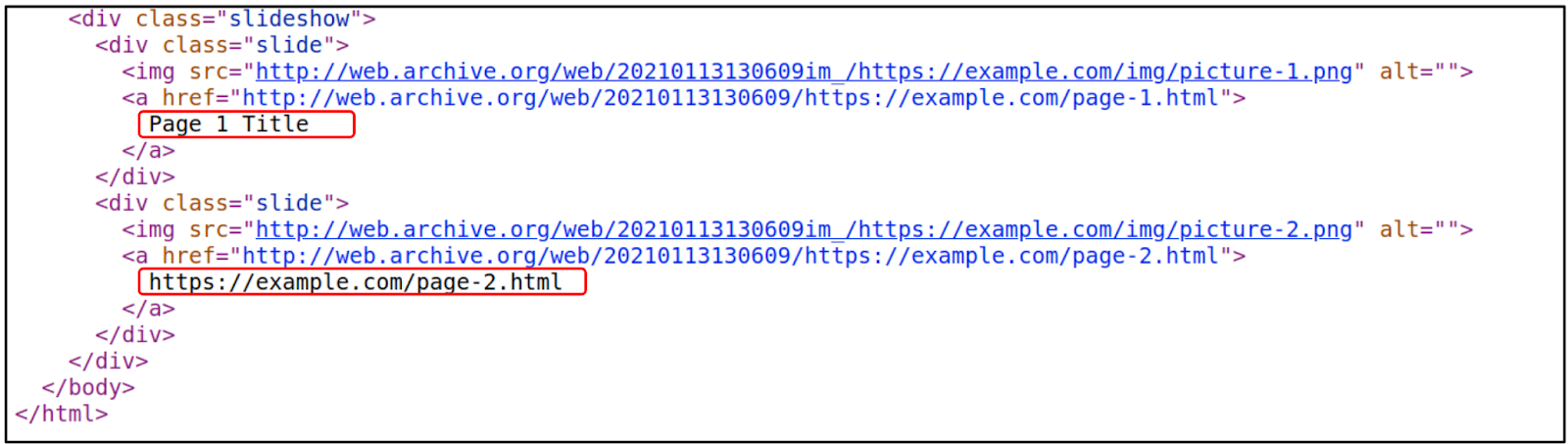
Figure 13: A snippet from the source code of the memento of the simple slideshow HTML page
For the second case, let’s consider a JSON file (Figure 14) that stores the same information as the above HTML page (Figure 12). This is similar to how data is stored as JSON in Twitter’s new UI.

Figure 14: simple JSON file with slideshow information
We used the above file and then archived it using the SPN web interface (Figure 15). The JSON objects are a format where data is stored in simple key-value pairs. As you can see in Figure 15, in the second element, the value for the caption (https://web.archive.org/web/20210113130833/https://example.com/page-2.html) is also rewritten where it is meant to be considered as a string, not an URL. We believe that it is due to this reason that it was decided to rewrite the URLs stored in JSON format if it starts with a URL and not rewrite if it starts with text. In case if the archive is only using server-side rewriting without rewriting the URIs in JSON, it will cause an adverse effect of broken replay. It will lead to embedded resource references and hyperlinks not pointing to their corresponding archived versions, resulting in zombies (leakage from the live web). There is no easy, generalizable solution for this. However in the HTML file, as it is easy to differentiate between what is expected to be a caption and what is expected to be a URL due to known standard HTML notation, rewriting the URLs is much less complicated and such a trade-off is not required.

Figure 15: A memento of the simple JSON slideshow data
Exploring Other Web Archives For Similar Behavior
We archived our test JSON example (Figure 8) using archives other than Internet Archive to test their behavior towards a server-side rewriting of JSON files. We archived the tweet shown in Figure 4 as well using Conifer, Perma.cc, archive.is, and Archive-It.
A. Conifer
We archived the test JSON (Figure 8) and the tweet using Conifer’s web application. We could not obtain the archived test JSON as it is not showing up after the capture finishes. The archived copy of the tweet (Figure 16) shows a failed new UI memento.
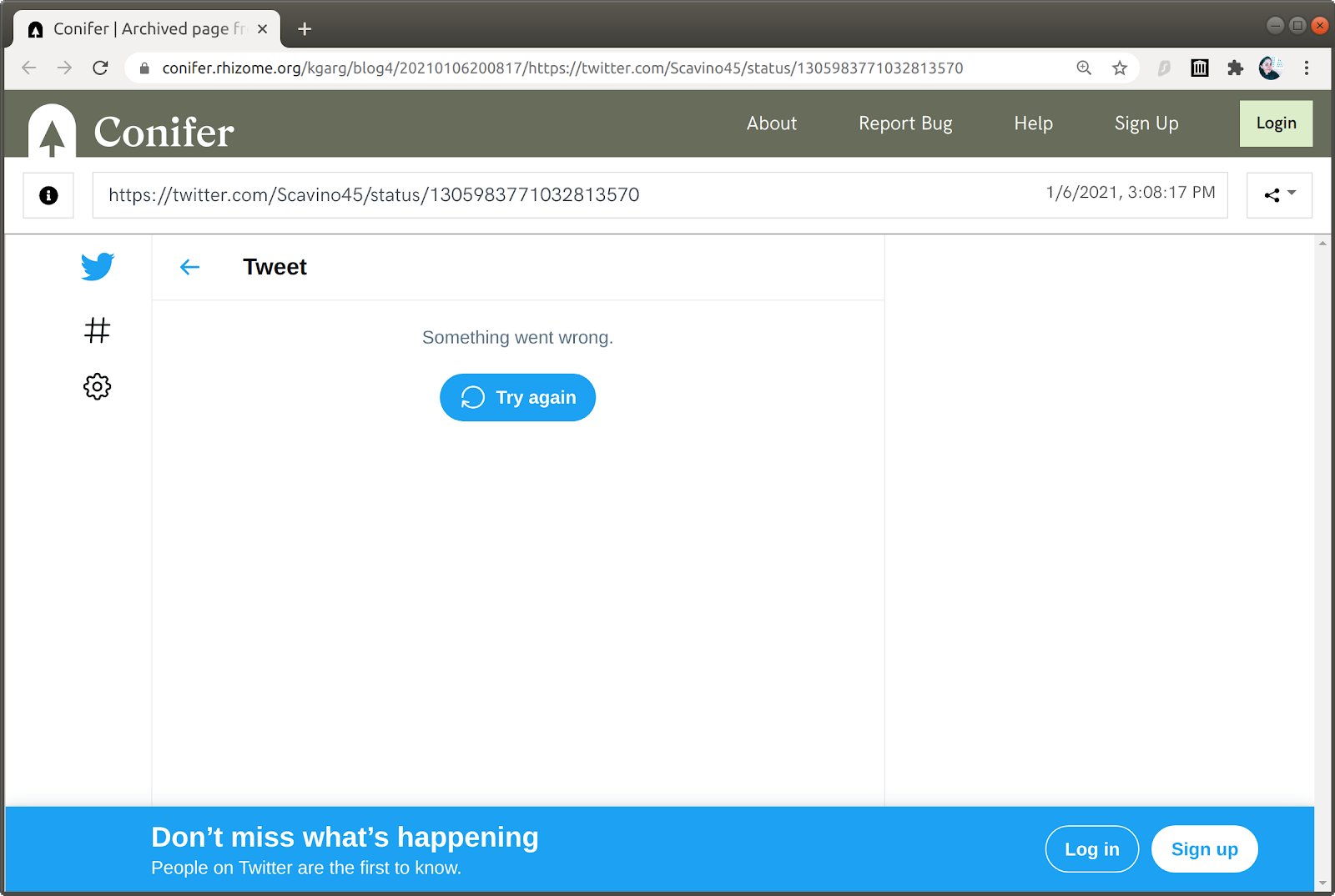
Figure 16: The archived copy of the tweet captured through the Conifer web application displaying a failed memento.
B. Perma.cc
We captured the resources using Perma.cc. The test JSON is not displayed directly as its MIME type is “application/json” (Figure 17 - left), but we can download and view the JSON file. We noticed that the URLs in the archived JSON are not rewritten (Figure 17 - right).
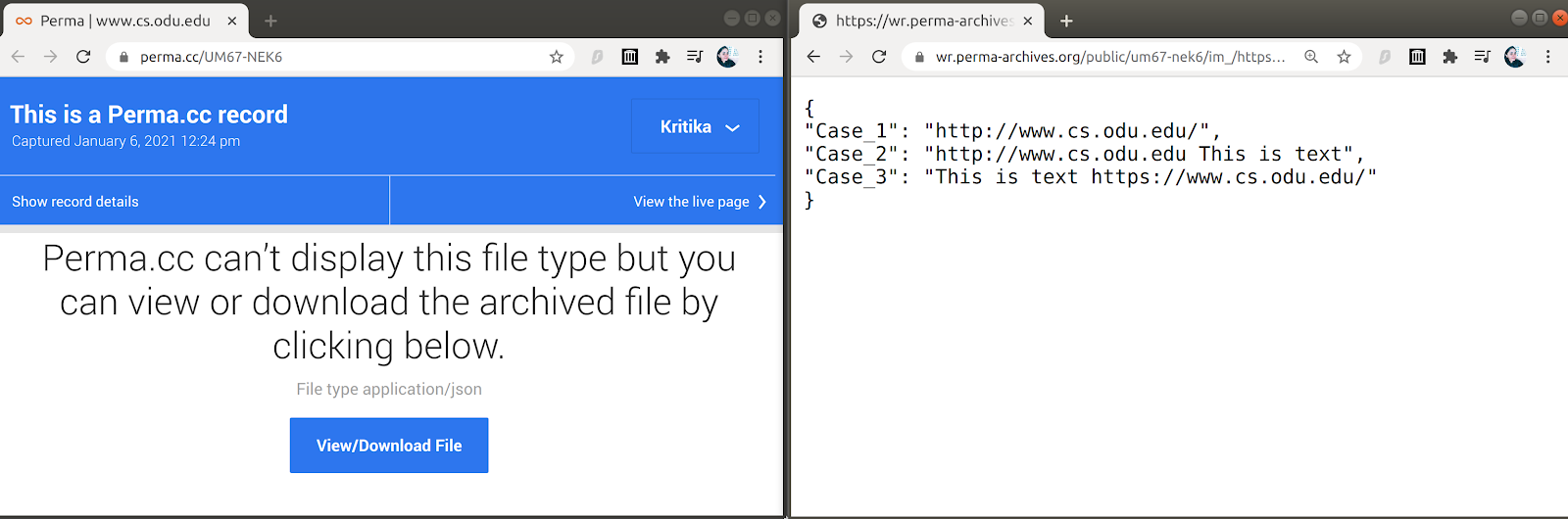
Figure 17: A Perma.cc record of the test JSON file (left) where we can download and view the JSON content (right). The URLs are not rewritten here.
The archived copy of the tweet (Figure 18) captured using Perma.cc shows a failed new UI memento.

Figure 18: The archived copy of the tweet captured using Perma.cc which displays a failed new UI memento.
C. archive.is
archive.is successfully captured both the resources (test JSON and the tweet). The archived test JSON did not have any rewritten URLs, this is because archive.is converts all the files into a static HTML page and provides that as a memento (Figure 19). Similarly, the tweet is also successfully archived with the old Twitter UI (Figure 20).
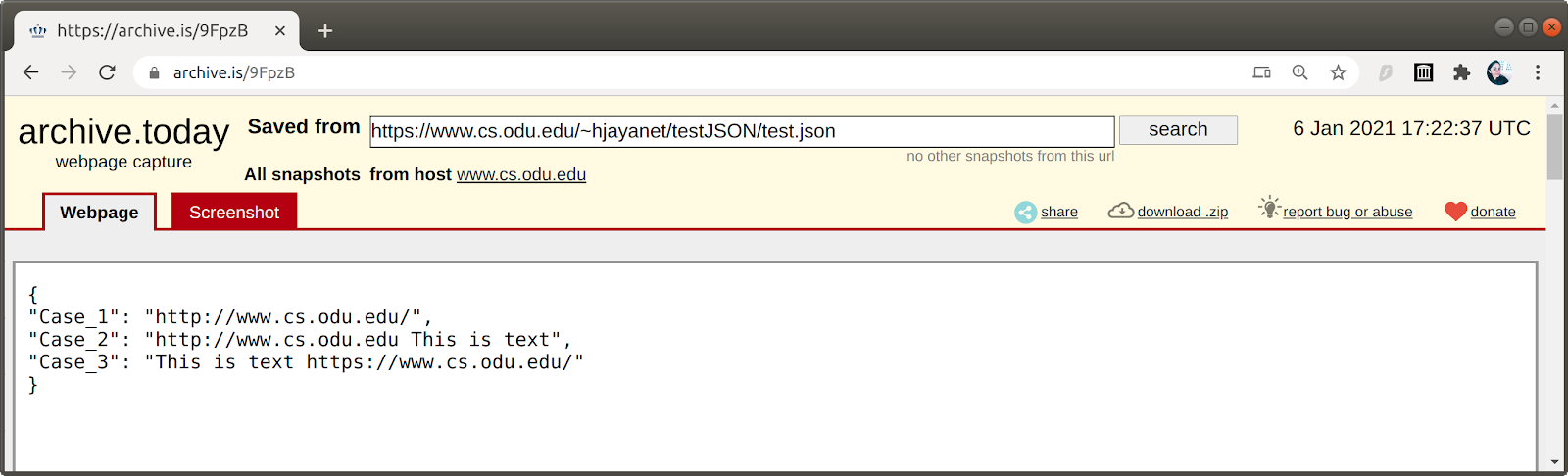
Figure 19: The archived test JSON captured through archive.is did not have any rewritten URLs.
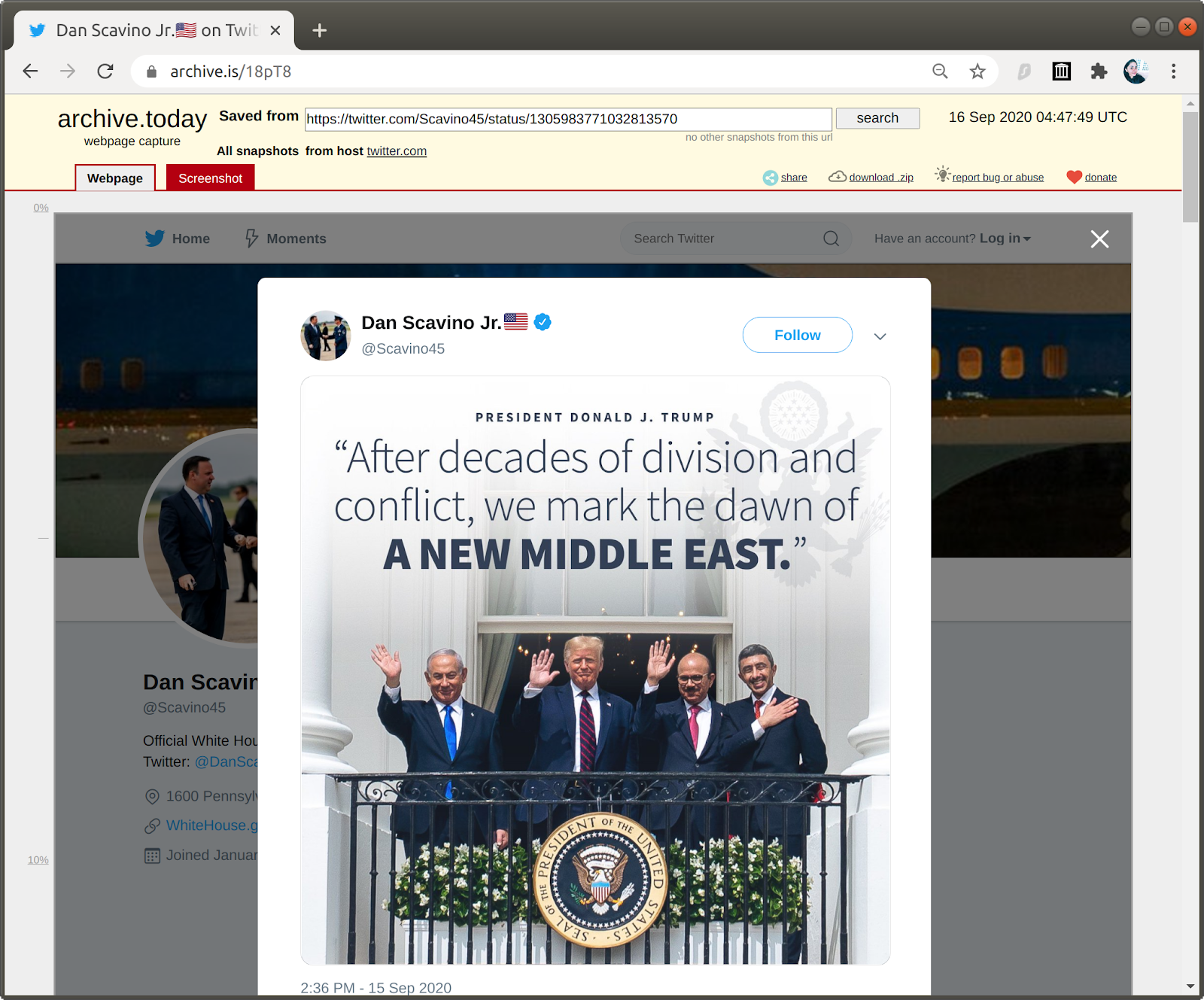
Figure 20: A memento of the tweet which had captured the old Twitter UI.
D. Archive-It
Finally, we archived the test JSON using the Archive-It service via the standard crawler (Figure 21). Similar to the Wayback Machine, if the text content of the archived copy contains only a URL (Case 1) or if it starts with a URL (Case 2), then that URL is rewritten ("https:\/\/wayback.archive-it.org\/15649\/20210106172748\/http:\/\/www.cs.odu.edu/"). However, if the content starts with text (Case 3), the URL is not rewritten. In addition, you may notice how Archive-It adds a heretofore unseen behavior: backslashes, presumably to escape the slashes when rewriting the URLs.
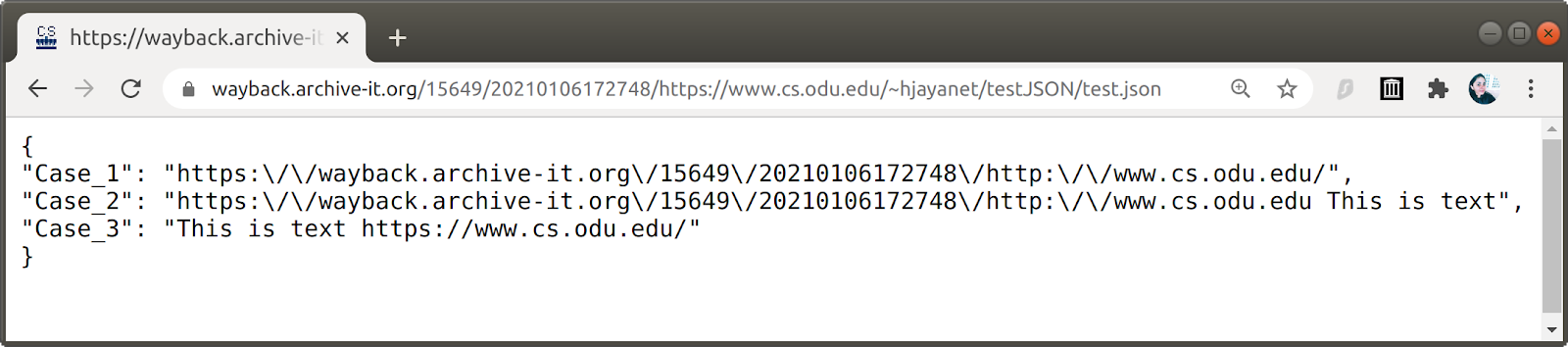
Figure 21: A memento of the test JSON captured using the Archive-It service via standard crawler. The URLs in Case 1 and Case 2 are rewritten whereas the URL in Case 3 is not rewritten.
The archived copy of the tweet done through Archive-It (Figure 22) is of the new UI, and it fails to render.

Figure 22: The archived copy of the tweet captured using Archive-It displays a failed new UI memento.
Conclusion
Twitter shortens all the shared links posted in tweets and rewrites them to a t.co link. New UI tweets that share media (video, images) with no additional text have their t.co links rewritten on the server-side in the JSON. The resulting t.co URI-M is much longer than the usual 23 characters of a t.co URL. This results in Twitter's JavaScript stripping only "https://web.archive.org" (first 23 characters) from the complete URI-M but displaying the rest of the URI-M in the memento. However, Tweets with text and media do not have the t.co links rewritten, so their replay correctly duplicates their live Web behavior.
This issue is a minor impact that most people will disregard, but this will surely confuse some web archive users. This is yet more fall out from Twitter’s UI change over the summer when they stopped supporting the legacy UI. The New Twitter UI is built using various JSON objects whereas, in the previous UI, most of the content was server-side HTML. The structural decisions that are otherwise hidden from people have manifestations in the systems that are downstream, like an archival replay. If the replay system uses client-side rewriting/rerouting (such as Wombat.js or Reconstructive) then server-side rewriting can be turned off for JSON files to potentially mitigate this issue. Assuming this is eventually fixed in future playback software, it then becomes another entry in "replaying the same memento gives different results over time” (cf. Mohamed Aturban’s Ph.D. dissertation, “A Framework for Verifying the Fixity of Archived Web Resources”).
Acknowledgments
We would like to acknowledge Dr. Michael Nelson, Dr. Michele Weigle, and Dr. Sawood Alam for their support in compiling this blog post.
--
Kritika Garg (@kritika_garg) & Himarsha Jayanetti (@HimarshaJ)
Comments
Post a Comment