2020-07-15: Twitter Was Already Difficult To Archive, Now It's Worse!
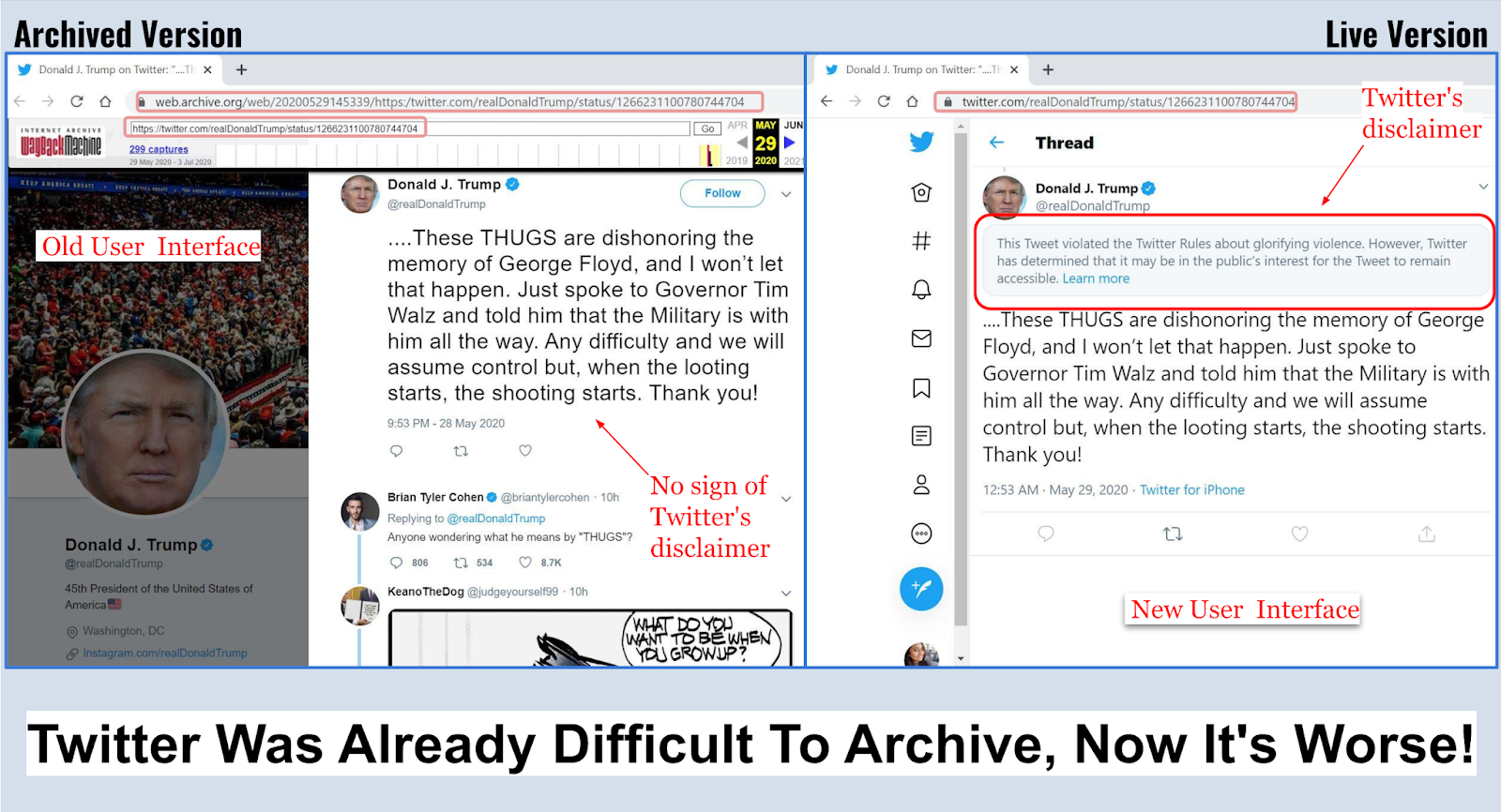 |
| Figure 1: Archived and Live version of Donald Trump's tweet with the attached disclaimer (2020-05-29T14:53:39) |
On May 29, 2020, Twitter attached a disclaimer to one of U.S. President Donald Trump’s tweets on the Minneapolis protests. This disclaimer labeled the tweet as violating Twitter Rules about glorifying violence. A similar case happened on May 26, 2020, when Twitter added a fact-check label to two of the President’s tweets on mail-in voting. On replaying these tweets through web archives, most of the archived pages, or mementos, failed to include the disclaimer and the label. This tweet thread shows how different archiving platforms failed to replay Twitter's disclaimer. Figure 1 shows how the disclaimer is missing in the archived copy in the Internet Archive's Wayback Machine. The other visible difference shown in the above image is the variation in Twitter UI. The memento of the Minneapolis protests tweet has the old Twitter interface, while the live tweet itself has the new Twitter interface. This difference in interface is also the cause of the missing disclaimer. The disclaimer and the label are likely features of Twitter’s new UI. Currently, most of the web archiving services are unable to successfully archive the new UI.
 |
| Figure 2: Memento showing Twitter's warning banner (Archived on 2020-05-08T07:23:15) |
Twitter launched a major redesign to its website in July 2019, but users were still able to access the old version of twitter.com through some workarounds. Twitter shut down the legacy version on June 1st, 2020, necessitating all desktop users to use the new mobile-inspired layout. Starting May 8, 2020, Twitter began warning users still accessing the legacy version to switch to a supported browser (Figure 2). Due to this changeover, archiving services like Internet Archive (IA), Perma.cc, Conifer, etc. started failing to archive Twitter pages. The web archiving services which use Twitter’s legacy interface are no longer able to access Twitter pages. However, throughout the process of compiling this blog post, we identified that Twitter’s legacy interface is still accessible by some bots.
Analyzing Twitter UI's Change: Old live vs. New live
 |
| Figure 3: Old live vs. New live (2020-07-09T12:58:17) |
We further inspected the change from the old to new UI by analyzing the network traffic of the legacy interface and the current interface. For collecting the data for comparison, we needed to access Twitter’s legacy interface. We noticed that unlike the old UI, the new UI issues calls to api.twitter.com to build out the pages (Figure 4). This made us think “well, how does Google still crawl tweets? Google is almost surely not using a headless browser to contact api.twitter.com”. This is what led us to try out the “Googlebot” user agent. We used Chrome's incognito mode with the user agent set as “Googlebot” (Figure 5). The incognito mode helped us avoid cookies and the “Googlebot” caused twitter.com to return the old UI in response to our requests.
 |
| Figure 4: Twitter's new interface (2020-07-09T11:59:24) |
 |
| Figure 5: Accessing Twitter legacy theme using "Googlebot" UA in Chrome's incognito mode (2020-07-09T11:59:24) |
While loading both versions of the page, we captured the network traffic for a duration of two minutes using the Chrome developer tools and exported the data in HTTP Archive (HAR) format. We used Haralyzer to analyze the differences between the two UIs (the data is available in a GitHub repo). We were able to verify that the requests generated by the legacy interface and the new interface are different in many ways. As you can see in Figures 5 and 6, the old Twitter UI is sending “https://twitter.com/i/jot” request through twitter.com and the new UI is making a similar type of request but through api.twitter.com. Based on our analysis, we noticed that the old UI only communicated with the API for authentication and configuration of embedded video. The new interface mostly communicates through api.twitter.com. We have learned that the underlying architecture of the new twitter.com is focused on responsive web design and is built to serve both mobile and desktop users.
The Effect of UI Change on Different Web Archives
We inspected the different web archiving services namely, Internet Archive, Conifer, Perma.cc, and archive.is to see how the change in UI affected them.
A. Internet Archive
We noticed the effect of this transition on the Internet Archive while archiving the Twitter page of Donald Trump through the “Save Page Now” service (SPN) of IA. We observed that Save Page Now can be used in three different ways: 1) We can use the SPN web interface; 2) We can also invoke the SPN service by simply typing the URL as “web.archive.org/save/URI-R” (where URI-R is the URL to archive) in the browser’s address bar; 3) SPN can also be used by specifying this same URL form with the CURL command in the terminal.
1. SPN web interface
Initially, we noticed that the “Save Page Now” service could properly archive mementos (URI-M1, URI-M2, etc.) of Twitter in most instances, but they failed occasionally. However, later on, most of the mementos were not archived properly. To demonstrate this, we used SPN to archive multiple Twitter pages. We noticed these captures resulted in different types of failed mementos.
 | |
|
While archiving the Twitter page through SPN, we observed that the SPN’s crawler was not able to reach the page, instead it received Twitter’s try again error. This led to the “Sorry, that page doesn’t exist!” error memento as shown in Figure 6.
 |
Figure 7: "Browser is no longer supported" popup in archived Twitter (Archived on 2020-07-02T07:30:32)
|
Figure 7 shows that the crawler captured the “Browser is no longer supported” popup on top of “Sorry, that page doesn’t exist!” error instead of the actual page. This popup, generated by Twitter, warned the users to update their browsers or disable the extension that is used to mask their real user agent. We also noticed that the same pop-up appeared sometimes on live Twitter (Figure 8).
 |
| Figure 8: "Browser is no longer supported" popup in live Twitter (2020-06-25T09:48:00) |
Later, we observed that both of the mementos as shown in Figure 6 and Figure 7 are now displaying “Something went wrong, but don’t fret — let’s give it another shot” error (Figure 9).
 |
| Figure 9: The same memento in Figure 7, but now replay shows Twitter's Try again error page (Archived on 2020-07-02T07:30:32) |
As of now, we noticed that the Save Page Now (SPN) interactive interface is working. Perhaps IA has put a temporary fix in place to make sure people can successfully archive Twitter pages. We noticed a change in User-agent and Via HTTP request headers of SPN. We observed this with the help of an echo service hosted by Scooterlabs. We have archived this echo service on 2020-07-02T22:10:24 and noticed that the user-agent was “curl/7.58.0” and Via header was “HTTP/1.0 web.archive.org (Wayback Save Page)”. We archived the same page again on 2020-07-09T19:44:09 and noticed that the User-agent is now set as a web browser and the Via header consists of “archive.org_bot”.
 |
| Figure 10: Change in UA and Via HTTP request headers of SPN - 2020-07-02T22:10:24 (left), 2020-07-09T19:44:09 (right) |
While archiving using the SPN web interface, we spotted an issue where the captured URL was a JSON file instead of the expected memento (Figure 11). However, this seems to be a transient error.
 |
| Figure 11: Captured memento URL (URI-M) is different from what we requested to archive (2020-07-09T19:59:46) |
2. SPN using URL in the browser
We tested this approach of using SPN where we tried to capture Donald Trump's Twitter page by putting a "https://web.archive.org/save/https://twitter.com/realDonaldTrump" URL in Chrome’s address bar. We noticed that this service has been failing ever since the UI change.
The reason for this archival failure is that Twitter recognizes the browser's UA and stops the SPN from accessing the old interface. Twitter displays a try again error and this error is archived instead of the actual page. To confirm this, we changed the Chrome UA to "Googlebot" using the user-agent switcher in default basic browser mode and archived the page again. We were able to successfully archive the page without using the browser’s incognito mode.
3. SPN with CURL
SPN can also be used via CURL command by specifying the URL in the form “web.archive.org/save/URI-R”. We noticed that this service also fails to archive the pages if no specific UA is set. We tried the same approach of setting the UA as “Googlebot” and this also returned a successfully captured memento (Figure 12).
$ curl -iLs -A "googlebot" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/1.1 200 OK
Server: nginx/1.15.8
Date: Thu, 18 Jun 2020 23:21:46 GMT
Content-Type: text/html;charset=utf-8
Content-Length: 581919
Connection: keep-alive
Content-Location: /web/20200618232145/https://twitter.com/WebSciDL |
| Figure 12: Successfully archived memento using curl with "Googlebot" UA (2020-06-18T23:21:45) |
This motivated us to dig deeper into how SPN responds to different user agents. It looked like “Googlebot” is not the only UA that worked. There are some UA with the word "bot" in the string that works, but not all of them do. We tested with user agents such as Bot, Twitterbot, and AhrefsBot which resulted in successful captures. We further tested using the top 10 most popular web crawlers and user agents. Out of those user agents, we found that when the UA was set as Bingbot, Slurp, DuckDuckBot, Baiduspider, YandexBot, or Facebot, we were able to archive Twitter pages as expected.
$ curl -iLs -A "bot" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 11:21:33 GMT
content-type: text/html;charset=utf-8
content-length: 576249
content-location: /web/20200708112132/https://twitter.com/WebSciDL
$ curl -iLs -A "Baiduspider" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 10:31:11 GMT
content-type: text/html;charset=utf-8
content-length: 571959
content-location: /web/20200708103110/https://twitter.com/WebSciDL
$ curl -iLs -A "DuckDuckBot" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 10:40:29 GMT
content-type: text/html;charset=utf-8
content-length: 571959
content-location: /web/20200708104029/https://twitter.com/WebSciDL
$ curl -iLs -A "Mozilla/5.0 (compatible; AhrefsBot/5.2; +http://ahrefs.com/robot/)" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 11:03:42 GMT
content-type: text/html;charset=utf-8
content-length: 571959
content-location: /web/20200708110341/https://twitter.com/WebSciDL
However, using user agents such as Sogou Spider, Exabot, ia_archiver (Alexa crawler), and Dotbot, SPN failed to capture the mementos properly. There seems to be no pattern as to how Twitter responds to different UAs. It does not appear to be as simple as checking for the string "bot" in the user agent request header. As shown in the curl command, we can distinguish between the successfully captured mementos and failed mementos by looking at their content-length. As you can see, the content length of a successfully captured memento is significantly higher in magnitude than that of a failed memento.
$curl -iLs -A "Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:78.0) Gecko/20100101 Firefox/78.0" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 11:50:14 GMT
content-type: text/html;charset=utf-8
content-length: 43974
content-location: /web/20200708115014/https://twitter.com/WebSciDL
$ curl -iLs -A "Sogou Spider" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 12:29:45 GMT
content-type: text/html;charset=utf-8
content-length: 43762
content-location: /web/20200708122941/https://twitter.com/WebSciDL
$ curl -iLs -A "ia_archiver (+http://www.alexa.com/site/help/webmasters; crawler@alexa.com)" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 12:36:49 GMT
content-type: text/html;charset=utf-8
content-length: 43762
content-location: /web/20200708123649/https://twitter.com/WebSciDL
$ curl -iLs -A "Mozilla/5.0 (compatible; Exabot/3.0; +http://www.exabot.com/go/robot)" https://web.archive.org/save/https://twitter.com/WebSciDL
HTTP/2 200
server: nginx/1.15.8
date: Wed, 08 Jul 2020 12:46:23 GMT
content-type: text/html;charset=utf-8
content-length: 43762
content-location: /web/20200708124623/https://twitter.com/WebSciDLB. Conifer
We archived the same page using Conifer (formerly known as Webrecoder). We found that Conifer also failed to replay the Twitter pages (Figure 13). This issue has been reported on the Conifer's GitHub repository. As mentioned in the response, we also noticed that this issue is caused due to exceeding the rate limit. We observed that while archiving using Conifer, Twitter returned an HTTP 429 “Too Many Requests” response error (Figure 14). As suggested in the same response, we were able to successfully archive the page using the Conifer desktop app.
 |
| Figure 13: Conifer not working (Archived on 2020-06-22T09:35:40) |
 |
| Figure 14: Conifer receiving an HTTP 429 response (2020-06-29T14:44:37) |
We tried the same user agent approach with Conifer's web interface that worked with Internet Archive's SPN service. We used the user-agent switcher Chrome extension to set the user agent as “Googlebot” and captured the same page. As shown in Figure 15, the memento was successfully captured.

We archived Trump's Twitter account page with Perma.cc. As you can see, this service has also ceased to function as we expected (Figure 16). We also noticed the familiar "Too Many Requests" error in Perma.cc. We believe that Perma.cc is also experiencing aggressive rate-limiting like Conifer. We could not use a similar approach with Perma.cc as it does not have any functionality where we can specify a different browser/user agent.
 |
| Figure 16: Perma.cc receiving "try again" error. (Archived on 2020-06-08T13:06:00) |
D. archive.is
We also captured Trump's Twitter page using archive.is (also known as archive.today). Among the archiving services we checked, archive.is was the only service that could successfully archive the page. This is because archive.is uses the Chromium browser to record the necessary embedded resources and then creates a static page as the memento. Unlike Conifer and Perma.cc, archive.is is able to avoid 429 “Too Many Requests” responses, probably because it is using a non-headless browser. Figure 17 shows archive.is' switch from the old Twitter design to the new Twitter design. It also shows the difference between the two designs; the old design has the tweet and reply thread whereas, in the new design, Twitter has masked the reply thread to limit the engagements with the disclaimer attached tweet.
 |
| Figure 17: Archive.is successfully replaying the disclaimer - 2020-06-01T10:53:15 (left), 2020-01-02T12:07:48 (right) |
Live Twitter and Archived Twitter Rarely Match
What we see on the live web and how it is replayed in the archive are not always the same. Certain anomalies can occur while capturing and/or replaying an HTML page. One such example is of CNN.com, where CNN became unarchivable due to changes they made in their JavaScript. John Berlin has covered this problem in detail in his blog post from January 2017, “CNN.com has been unarchivable since November 1st, 2016”. Recently, CNN has become re-playable in IA's Wayback Machine.
Another example of this can be experienced while archiving Twitter. Sometimes, an English language page when archived will replay either in a different language or multilingual in IA. This has been identified and discussed in detail by Sawood Alam in his blog posts “Cookies Are Why Your Archived Twitter Page Is Not in English” and “Cookie Violations Cause Archived Twitter Pages to Simultaneously Replay in Multiple Languages”.
The consequences to web archives of Twitter changing their UI can be seen with the example of the recent “white power” video clip retweet by President Donald Trump, which he later decided to delete (Figure 18). Twitter sends a 200 OK response for that particular tweet even though it doesn't exist anymore. Twitter sends a 200 OK response for a tweet that never existed although it sends an actual 404 when accessed by certain bots. We analyzed the TimeMap for that individual tweet on July 8, 2020, using the Wayback CDX Server API. We noticed that there were 18 mementos which received 200 OK status code from Twitter. Among these 18 mementos, 14 are “sorry, the page does not exist” or “browser no longer supported” error captures with only four captures successfully preserved. Since these failed mementos received 200 OK responses, this makes it harder for the crawler to judge the validity of the memento. The interactive user will also have to click through a sea of these soft 404s to find one correctly archived memento.
 |
| Figure 18: The archived copy (left) of President Donald Trump's deleted retweet (right). (Archived on 2020-06-28T12:42:00) |
#Twitter sends a “200 OK” response for a tweet that is no longer available (a soft 404). $ curl -is https://twitter.com/realdonaldtrump/status/1277204969561755649 | grep -v "content-security-policy:" | head -4 HTTP/2 200 cache-control: no-cache, no-store, must-revalidate, pre-check=0, post-check=0 content-type: text/html; charset=utf-8 date: Tue, 14 Jul 2020 16:27:35 GMT #Twitter sends a “200 OK” response for a tweet that never existed (a soft 404). $ curl -is https://twitter.com/realdonaldtrump/status/1234ThisWasNeverAValidTweetID5678 | grep -v "content-security-policy:" | head -4 HTTP/2 200 cache-control: no-cache, no-store, must-revalidate, pre-check=0, post-check=0 content-type: text/html; charset=utf-8 date: Tue, 14 Jul 2020 16:31:06 GMT #Twitter sends a “200 OK” response for a tweet that exists (an actual 200 OK response). $ curl -is https://twitter.com/realDonaldTrump/status/1263981547386011649 | grep -v "content-security-policy:" | head -4 HTTP/2 200 cache-control: no-cache, no-store, must-revalidate, pre-check=0, post-check=0 content-type: text/html; charset=utf-8 date: Tue, 14 Jul 2020 16:33:50 GMT #Twitter sends an actual 404 instead of soft 404 when accessed by certain bots. $ curl -is -A "googlebot" https://twitter.com/realdonaldtrump/status/1277204969561755649 | grep -v "content-security-policy:" | head -5 HTTP/1.1 404 Not Found cache-control: no-cache, no-store, must-revalidate, pre-check=0, post-check=0 content-length: 6333 content-type: text/html;charset=utf-8 date: Wed, 15 Jul 2020 17:02:55 GMT
Conclusions
We looked at how different archiving services acted after Twitter's UI change. We noticed that while the SPN web interface is now working via accessing the old UI, the other two alternative approaches to invoke the SPN are still failing to archive Twitter unless we set a different working UA. Therein lies the issue: Twitter currently responds with the old UI when it thinks it is talking with known bots, and Wayback Machine-based implementations (IA, Conifer, Perma.cc) can only archive the old UI. But interactive users only see the new UI in normal browsing, which would have limited impact if the UI differences were limited to trivial issues such as button shape and placement. However, the labels and disclaimers applied to President Trump's tweets seem to only be present in the new UI, thereby causing a significant contextual gap in what is archived and what users experienced on the live web. Among the web archive initiatives we tested, archive.is is the only service that can successfully archive Twitter’s new UI. From our analysis, we can say that setting a different user agent (“Googlebot”) is a viable workaround at this point. With the idea of a new UI, Twitter aimed to develop an improved architecture which provides the best possible experience to all users. However, Twitter’s change in the user interface has had adverse effects on archiving services. Twitter was already difficult to archive, now it's even worse.
Updates
2020-07-16: Thank you @IlyaKreymer for pointing out regarding Twitter's aggressive rate limiting. It makes much more sense to believe that rate limiting could be what makes the new UI difficult to archive, given the fact that Twitter’s new UI is talking to api.twitter.com that imposes rate limiting.
Based on our results, archive.is has swapped their UA and is now again archiving the legacy UI.
2020-07-16: Thank you @IlyaKreymer for pointing out regarding Twitter's aggressive rate limiting. It makes much more sense to believe that rate limiting could be what makes the new UI difficult to archive, given the fact that Twitter’s new UI is talking to api.twitter.com that imposes rate limiting.
Based on our results, archive.is has swapped their UA and is now again archiving the legacy UI.
Acknowledgments
We would like to acknowledge Dr. Michael Nelson, Dr. Michele Weigle, and Sawood Alam for their guidance and contribution in compiling this blog post.
Kritika Garg (@kritika_garg) and Himarsha Jayanetti (@HimarshaJ)
"Twitter aimed to develop an improved architecture which provides the best possible experience to all users."
ReplyDeleteI dont believe their aim was to create the best possible experience to all users. It was a convenience (maybe cost cutting?) decision. They were tired of having to maintain two separate codebases, one for mobile, one for desktop, and attempted to 'unify' it. Which of course just means turn the entire thing into a phone app that you can open on a large monitor.
I was sad to see that GoodTwitter eventually got 'blocked' by twitter, I'm sure someone there noticed that that extension had several hundreds of thousands of users, all desktop users finding this new 'mobile' version to be an unwelcome change.