2022-12-21: PDFServer - Our Summer Internship at LANL
This summer (summer of 2022), we (Himarsha Jayanetti, Gavindya Jayawardena, and Yasith Jayawardana) got the opportunity to intern at the Los Alamos National Laboratory (LANL) under the Graduate Research Assistant Program. Himarsha and Yasith worked as a part of the Library's Research and Prototyping Team (Proto Team) under the supervision of Drs. Martin Klein and Shawn M. Jones. Gavindya was supervised by Brian Cain on the Institutional Scientific Content (ISC) Team. Each of us was responsible for one of the three main components that make up the "PDFServer".
What is the PDFServer?
PDFServer is a prototype to support LANL's Review and Approval System for Scientific and Technical Information (RASSTI), which is the starting point for collecting LANL’s documented scientific output and it provides workflows for authors and reviewers. The overall architecture of the PDFServer is displayed in Figure 1. We selected Laravel 9.11, which is a PHP web application framework, based on suggestions from the RASSTI development team. We worked independently on our tasks (thanks to the modular architecture of Laravel) and later developed a combined workflow that connects them together. We developed our core functionalities as three back-end services (Metadata Service, Social Card Service, and Robust Links Service) using Python 3 + Flask and integrated them with the Laravel front-end using Docker.
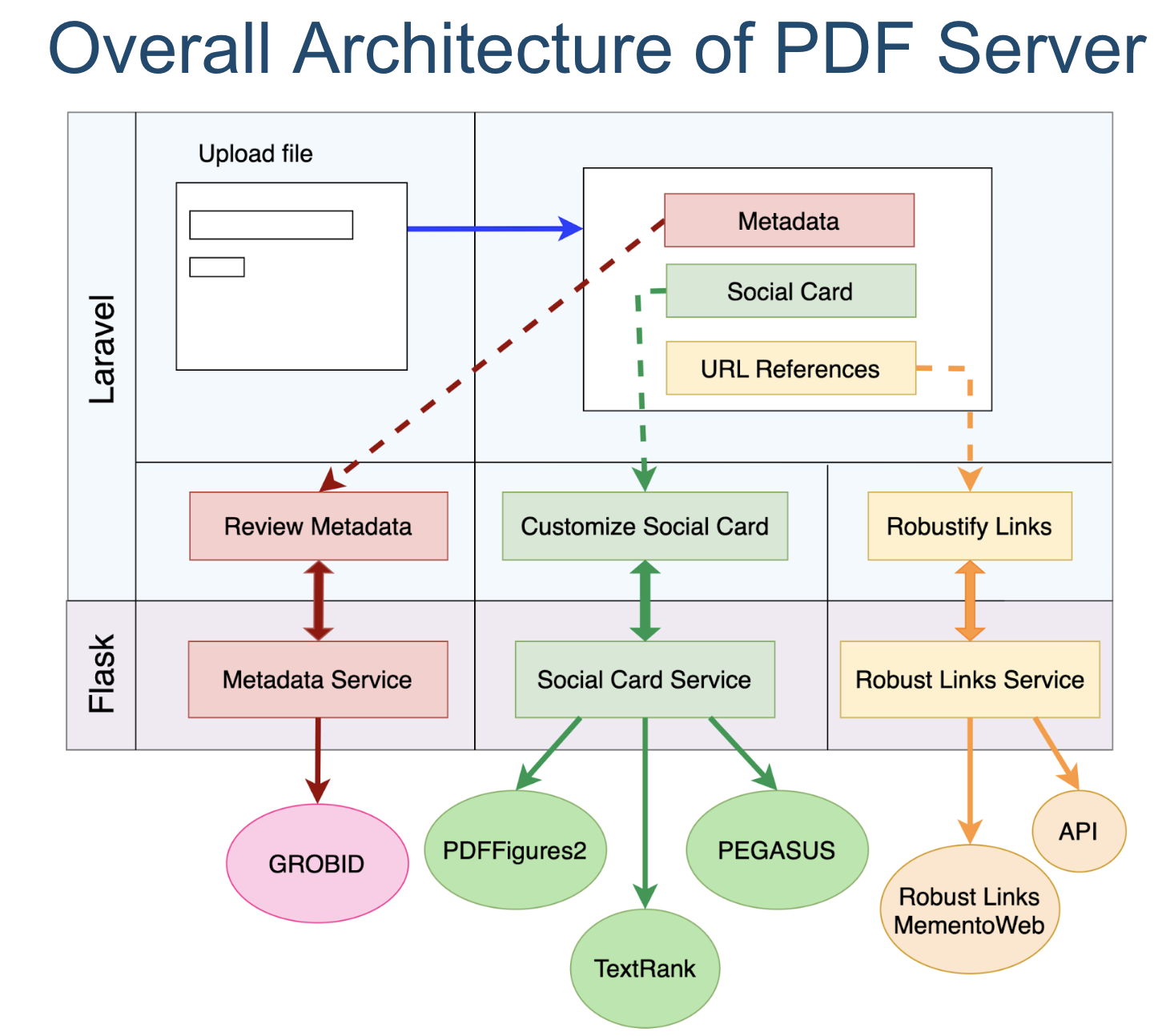
At a high level, a user begins by uploading their PDF document (Figure 2) for review. Next, PDFServer extracts metadata (authors, affiliations, title, abstract, etc.), images, URLs, and text from the uploaded document, and uses them to (a) pre-fill form fields that the user would otherwise fill in manually, (b) generate a social card consisting of a title, a striking image, and a micro-summary, and (c) robustify URL references.
A screenshot of the PDFServer landing page is displayed in Figure 3. It displays, in order, the extracted metadata, the auto-generated social card, and the extracted URL references. The black action buttons allow the user to review the extracted metadata, update the social card, and robustify the URL references.
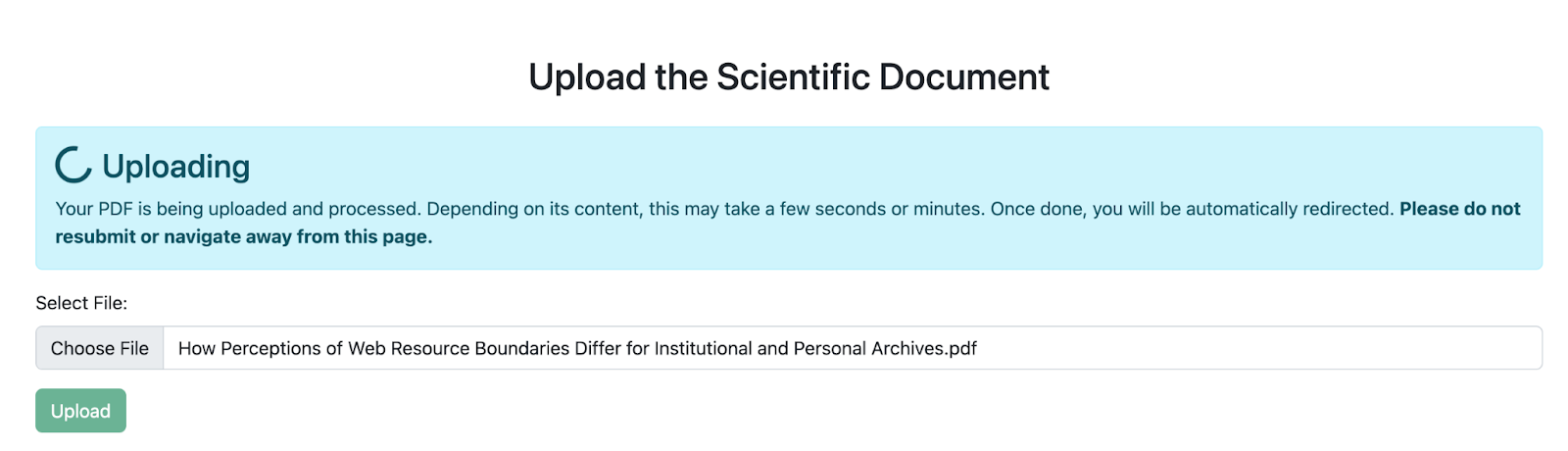
Fig. 2: Upload PDF page of PDFServer

Fig. 3: Landing Page of PDFServer. It displays the extracted metadata, the auto-generated social card, and the URL references. The action buttons (black) allow you to (a) review the metadata, (b) review the social card, and (c) robustify the URL references.
To better comprehend these functionalities, we will describe our individual contributions and development processes in three sections:
Extracting and Reviewing Metadata (Gavindya)
Generating Social Cards (Himarsha)
Robustifying Links (Yasith)
Extracting and Reviewing Metadata (Gavindya)
Consecutively for the second year, I had the opportunity to join the ISC team, a subdivision of the Research Library at LANL, as a Graduate Student intern.
Last Summer, I focused on extracting structured metadata (e.g., title, authors, affiliations, abstract, and keywords) from scientific PDF documents in near real-time. Our goal was to use this metadata to improve the user-friendliness of LANL's Research Library systems like RASSTI by pre-filling form fields where possible. I used an open-source, machine-learning-based tool named GROBID (GeneRation Of Bibliographic Data) to extract metadata and full-text from PDF documents, and a Python framework named Flask to develop two web services around it.
Metadata service
Request - PDF Document (File)
Response - title, abstract, authors, affiliations, keywords (JSON)
Full-text service
Request - PDF Document (File)
Response - paragraphs, section titles (JSON)
A user of this system can upload their PDF document and request either to extract its metadata or its full-text. Internally, the system invokes GROBID to extract what the user requested, and obtains them in XML format. The system then converts this information into JSON format and returns it back to the user.
This Summer, my goal was to create a system for users to review the extracted metadata. Since machine learning systems aren't 100% accurate, their outputs may require verification by visual inspection, text comparison, and standard information retrieval methods, all of which consume a lot of time. Therefore, I implemented user interfaces to review the extracted metadata in PDFServer.
Implementation
The metadata extraction and review system consists of three components:
A REST API (Python 3 + Flask) to extract metadata and store updates
A UI component (Laravel) for users to display extracted metadata
A UI component (Laravel) for users to review and update metadata
Metadata Service
As shown in Figure 4, a user can upload a PDF document from the PDFServer UI. Once uploaded, the UI invokes the Metadata Service to extract metadata and full-text from the uploaded document. Internally, the Metadata Service invokes the GROBID Server to extract this information in XML format. Once extracted, the Metadata Service converts that information from XML to JSON, and responds to the UI. The UI will then display this information, and allow the user to review/modify them as needed. Upon completing the review, the Metadata Service will store the reviewed metadata for future use.

Metadata Display UI
This UI shows the automatically extracted title, author names, affiliations, keywords, and abstract. Also, it displays a banner indicating that this page is loaded with automatically extracted data. Additionally, if GROBID extracts the ORCID of authors, it will be shown next to the author name. There is a button allowing a user to preview the uploaded PDF document as well.

Once the user clicks the “Review Metadata” button, it will load the next UI.
Metadata Review UI
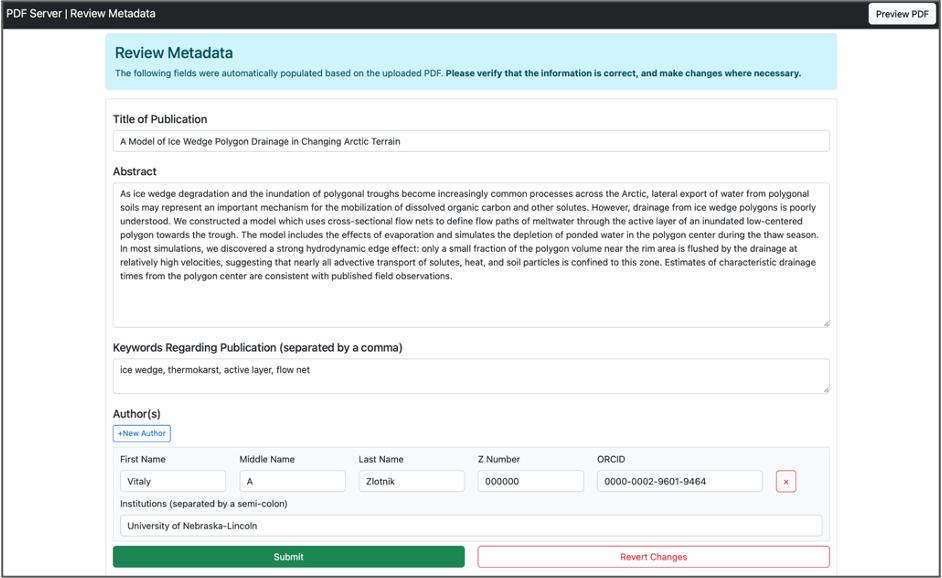
This UI allows a user to review automatically populated metadata based on the PDF that they uploaded. Users can modify the title, abstract, keywords, and authors (first name, middle name, last name, ORCID, Z-Number if a LANL employee, and institutions). This UI also allows a user to delete authors, add new authors, and revert the changes to the automatically extracted metadata.
Future Work
In the future, this functionality can be extended to distinguish between authors internal and external to LANL. This, however, may require access to LANL internal databases to match authors by their name or ORCID. Additionally, GROBID can be retrained to address issues like ORCIDs being extracted as postcodes and improper extraction of subscripts/superscripts.
The slides describing this functionality are available at the Office of Scientific and Technical Information website.Social cards that visually represent URLs are popular in social media. They provide a visual summary of the content behind a URL and consist of different elements like a title and a striking image. Figure 7 shows the social cards generated for the LANL homepage by Twitter (top) and Facebook (bottom). However, these platforms only generate social cards for HTML pages; they either fail to produce social cards for PDF documents or do so poorly. Figure 8 shows the social cards generated for a PDF link by these platforms. Here, Twitter (top) failed to generate a social card at all, while Facebook (bottom) generated a barebones social card with only the domain of the PDF link.


Fig. 8: For a PDF link, Twitter did not generate a social card (top), while Facebook only generated a basic social card (bottom), which contained simply the domain of the URL.
My goal this summer was to create a system that would create social cards for visualizing the content of scientific PDF documents. As a part of PDFServer, my system generates social cards that have three units: a title, a striking image, and a description.
Implementation: Social Card Service
Title Generator
I used the Metadata Service (developed by Gavindya) to extract the title from the PDF document, and used it as the social card title.
Striking Image Picker
This component analyzes all images in a PDF document and selects one image that best represents its content. First, it extracts all figures from the document using PDFFigures 2.0. Next, it computes several features for each image:
Figure number
Figure number (scaled)
Image bytesize
Image width
Image height
Number of columns in the image’s histogram with a value of 0 (negative space)
Image size in pixels
Image aspect ratio
Number of colors in the image
Next, it uses a Random Forest machine learning model to predict the score (probability) of each image being selected by a human author. Next, it picks the image with the highest score as the striking image. Jones et al. developed this technique in “Automatically Selecting Striking Images for Social Cards”.
Micro-Summary Generator
This component generates a small text summary of the PDF document, i.e., a “micro-summary”. It uses the Metadata Service to extract full-text from a PDF document, and provides two modes of summarization.
Extractive summarization using TextRank: TextRank, as developed by Mihalcea et al., is an extractive micro-summary where important sentences/phrases are found, extracted and aggregated into a brief summary.
Abstractive summarization using PEGASUS: PEGASUS, as developed by Zhang et al., is an abstractive summarization mechanism that produces a paraphrasing of the main contents of the given text from the original document. PEGASUS is much like what humans do when summarizing.
Social Card Display UI
This component uses the title, striking image, and micro-summary generated by the Social Card Service to render a social card (HTML) for the uploaded document. A user of this component can copy and embed this social card on their website/blog, similar to how they would embed YouTube videos, tweets, etc.
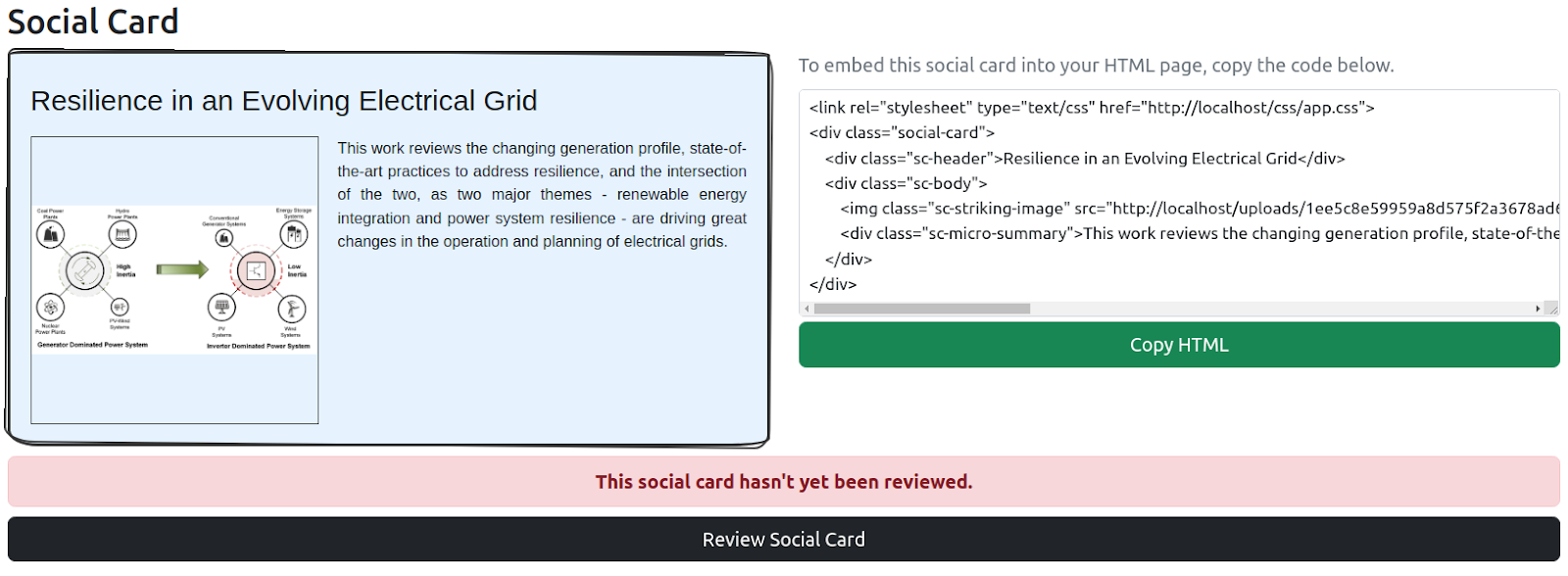
Fig. 9: The generated social card (left) and the HTML to embed this in a website/blog (right) as displayed in the PDFServer UI. The red banner indicates that the social card hasn't been reviewed yet. The user can click the black button to pick a different striking image or edit the micro-summary.
Social Card Review UI
The user is also provided with the ability to review and edit the content of the social card. In Figure 9, the red “This social card hasn’t yet been reviewed” banner indicates that the social card hasn't been reviewed yet by the user and the black “Review Social Card” button can be used to review the social card that was automatically generated. As shown in Figure 10 (top), all the images extracted from the PDF are displayed allowing the user to update or confirm the image chosen by the Random Forest machine learning model as the most striking image. The user can also edit the automatically generated micro-summary (Figure 10, bottom) if desired. Once confirmed, any changes made will be displayed on the social card.

Fig. 10: Update the most striking image (top) and micro-summary (bottom) of the auto-generated social card.

Future Work
Currently, the Social Card Service is tightly coupled with the PDFServer system. In the future, it may be interesting to develop a standalone PDF-to-social-card API that encapsulates full-text extraction, summarization, and image extraction within a single system. Moreover, the PDFFigures 2.0 image extractor we used, performed poorly on certain types of images (e.g., nested figures). Therefore, using an ensemble of image extractors may help to extract as many images as possible. Furthermore, more customization and personalization options can be added to the social card generator, similar to what MementoEmbed and Raintale do for archived web pages.
The slides describing this functionality are available at the Office of Scientific and Technical Information website.
Robustifying Links (Yasith)
Last summer, I explored different tools and frameworks to extract URL references from PDF documents. From this work, I found the combination of PyPDF2 (a Python library to extract annotated URLs) and PyPDFIUM2 (a Python wrapper for PDFIUM, which provides APIs to extract text URLs) to extract most URL forms remarkably well. [Last Year's Blog Post]

Fig. 11: URL Extraction from PDF Documents
I also developed an API around this functionality (i.e., Robust Links Service) using Python/Flask. It performs the following:
Extract URLs from an uploaded PDF document
Generate Robust Links for each URL, using the Robust Links API (MementoWeb)
Save the Robust Links as they are being generated in real-time
Notify other LANL systems about the saved Robust Links via Linked Data Notifications
Extract URLs from an uploaded PDF document
Generate Robust Links for each URL, using the Robust Links API (MementoWeb)
Save the Robust Links as they are being generated in real-time
Notify other LANL systems about the saved Robust Links via Linked Data Notifications
When the Robust Links API is called on a URL, it creates a snapshot of the content referenced by that URL in a public web archive and generates a Robust Link for it. A Robust Link is an HTML <a> tag with additional attributes that point to its archived snapshots.
This summer, I was tasked with integrating the Robust Links Service that I developed last year with the prototype RASSTI submission workflow of PDFServer. I was responsible for (a) developing the front-end elements to robustify URLs, (b) integrating the front-end with the Robust Links Service, and (c) maintaining a consistent design on our front-end components.
Implementation
Fig. 12: URL Robustification Workflow in PDFServer
First, Gavindya, Himarsha, and I discussed potential ways to develop our functionalities independently while making it easy to integrate them later, and opted to use Docker. Next, I prototyped the UI components for URL robustification (see Figures 13-17) in Laravel and went through several rounds of refinement upon discussing with Dr. Klein, Dr. Jones, and Brian Cain. Since the Robust Links service was previously developed as a standalone Python/Flask web application, I simultaneously modified it to be compatible with the UI.
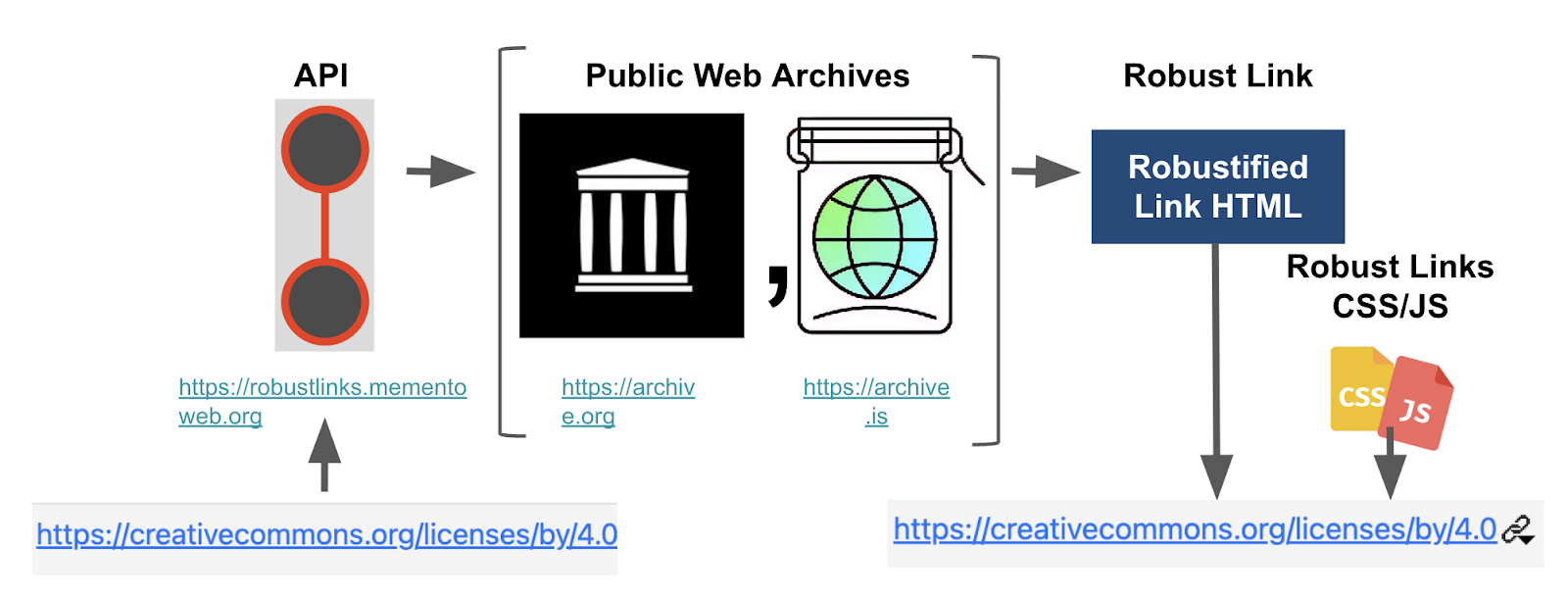

Fig. 13: URL robustification UI (before robustification)
Fig. 13 shows the URL robustification UI. Here, a user clicks on "Robustify URL references" to initiate the process. Upon clicking, the user is shown the URL selection UI (Fig. 14).
Fig. 14: URL Selection UI
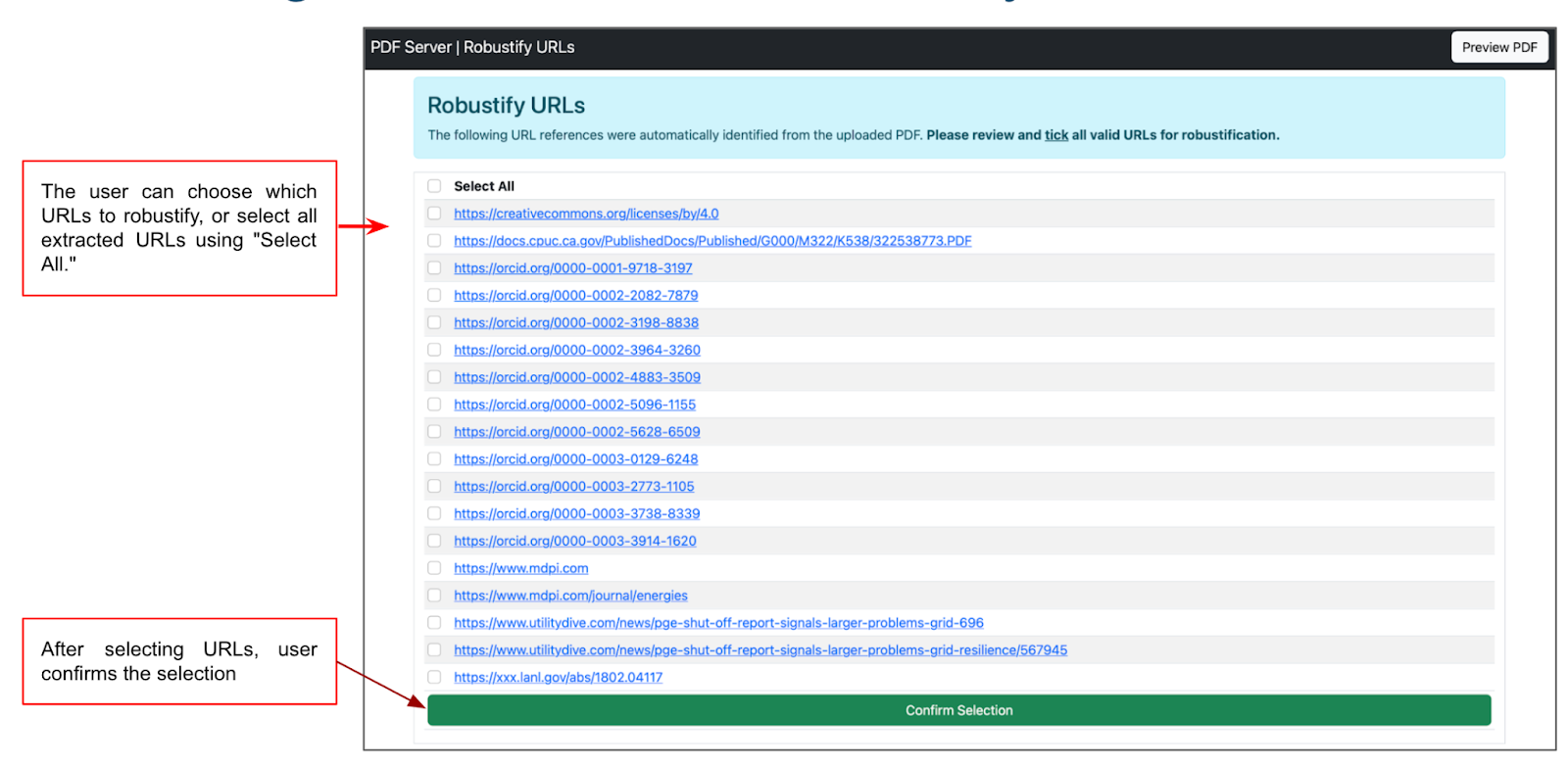
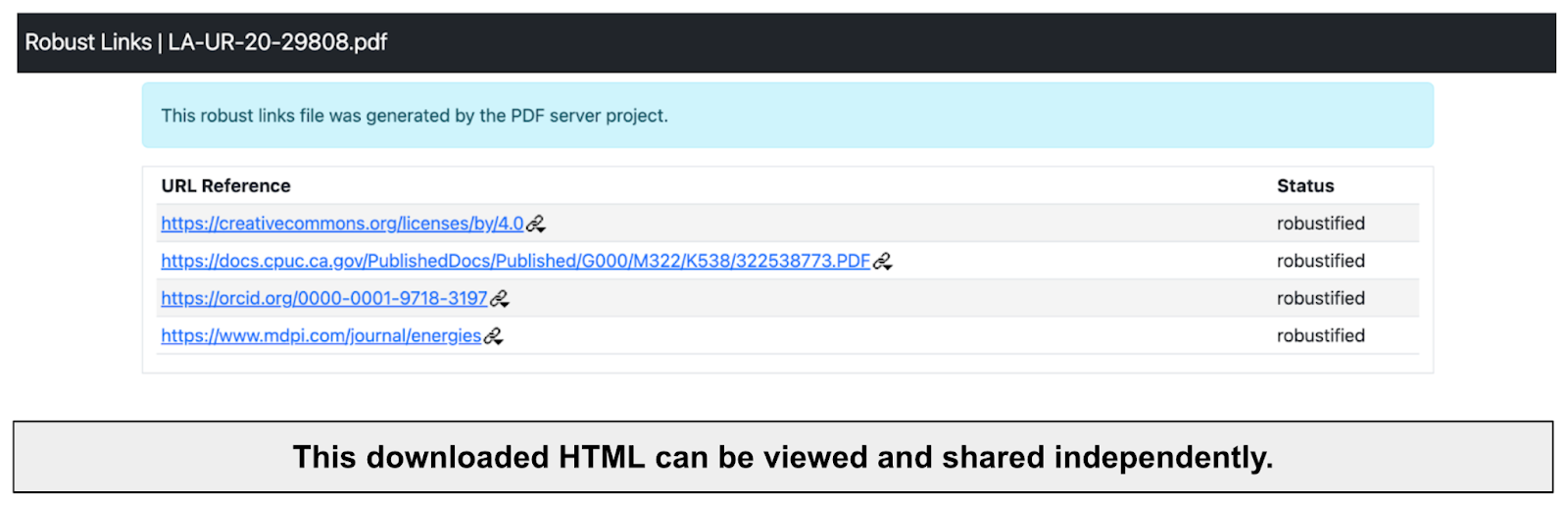
Here, the user chooses which URLs they want to robustify, and clicks on "Confirm Selection". The user is then shown the URL robustification UI, with the selected URLs and their ongoing robustification status (Fig. 15). Here, each URL will be in one of three statuses: (a) Pending, (b) Robustified, or (c) Failed.




Comments
Post a Comment