2021-08-31: Robustifying PDF Links - My 2021 Summer Internship at LANL

Amidst the uncertainties of COVID-19, I got the opportunity to work as a Summer Research Intern at Los Alamos National Laboratory (LANL). This was my first internship as a PhD student in the US, and I'm really grateful for this opportunity. Due to the ongoing pandemic, I was offered to work remotely. I was assigned to the Research and Prototyping (Proto) Team of the LANL Research Library, under the supervision of Dr. Martin Klein - an alumnus of the WSDL group of ODU.
 |
| Source: www.lanl.gov |
Los Alamos National Laboratory (LANL) is a Federally Funded Research and Development Center (FFRDC) with a mission to solve national security challenges through cutting-edge scientific research. Its strategic plan reflects U.S. priorities spanning nuclear security, intelligence, defense, emergency response, nonproliferation, counter-terrorism, energy security, emerging threats, and environmental management. Every year, LANL recruits approximately 2000 students to work on various scientific applications. These students are given the flexibility to work on different projects and gain hands on experience in solving various scientific research problems.
The Research and Prototyping (Proto) Team of the LANL Research Library explores various aspects of scholarly communication and open science in the digital age. The team focuses on information infrastructure, information interoperability, and long-term persistence of scholarly records. Recently, the team led the development and standardization of the Memento interoperability framework to access past versions of the Web resources.
The internship program started with a week-long orientation, where I attended training sessions to familiarize with LANL and its processes. In the second week, I began working on my assigned project. Throughout this program, I attended weekly one-on-one meetings with Dr. Klein and bi-weekly meetings with the Proto team. The one-on-one meetings were to discuss my progress, obtain feedback, resolve issues, and plan for the next week. The Proto team meetings were for team-wide announcements and for team members to share what they were working on. These ensured that I had regular communication with Dr. Klein and the entire team.
The Project
A Uniform Resource Locator (or URL) is a reference to a unique resource on the Web. Due to the dynamic nature of the Web, resources referenced by a URL may become inaccessible (link rot) or change (content drift) over time. Previous research by Dr. Klein (1, 2) reveal some interesting facts about URLs in scholarly publications.
- The number of URLs in scholarly publications is growing over time.
- One in five publications suffer from link rot.
- Three in four publications suffer from content drift.
My internship project was proposed as a solution to this problem. The idea was to build a service that proactively archives (i.e., "robustifies") the Web resources referenced by URLs in scholarly PDF documents. Given a PDF document, this service should extract the URLs in that PDF, create snapshots (i.e., Mementos) of their referenced Web resources in Web archives (e.g., archive.org, archive.today), and notify their existence to other systems. Here, the Mementos were to be created via the Robust Links service, and the notifications were to be sent as Linked Data Notifications (LDNs). While this service is primarily intended for use in LANL Research Library systems such as RASSTI (Review and Approval System for Scientific and Technical Information) where users submit scholarly PDF documents that may contain URLs, this idea applies to a broader context, and for this reason, I named it as the "Robust PDFLinks" service.
| Logo for the Robust PDFLinks Service |
I was fully responsible for carrying out this project, and I did so in two stages. First, I researched available tools, built prototypes, evaluated them, and based on the evaluation results, selected the right tools for implementing the Robust PDFLinks service. Second, I implemented the Robust PDFLinks service using the selected tools, tested its functionality, made iterative improvements, and wrote documentation.
Stage 1: Research, Evaluation
With the guidance of Dr. Klein, I first familiarized with the concepts of Web Archives, Linked Data, and Regular Expressions, and explored different ways to extract URLs from PDF documents. This led to a very interesting finding:
URLs in PDF text are not actionable unless they are annotated, or unless the PDF viewer itself detects them as URLs.
URLs in PDF text are (in most cases) just text, meaning they do not magically become actionable in every PDF Viewer. Applications such as Acrobat (PDF Viewer by Adobe), Preview (PDF viewer by Apple), and Chromium (Web Browser by Google) could detect URLs from PDF text and make them actionable, but applications such as Firefox (Web Browser by Mozilla) could not. Interestingly enough, the PDF specification describes a method to add actionable regions to PDF documents; i.e, adding a `Link` annotation for every URL. It lets you mark a region on the PDF document which, upon clicking, opens up a URL.
While extracting URLs from 'Link' annotations seem promising, we could not extract all URLs from this method. In fact, we used a library named PyPDF2 to extract URLs from 'Link' annotations (examples), and tested it on a sample dataset of 8 PDF documents having 67 URLs in total. Here, the PyPDF2 extractor was only able to extract 38/67 URLs. The remaining 29 URLs, as we confirmed, did not have a 'Link' annotation, and were not actionable in Firefox as well. This confirmed our suspicion that Firefox only makes URLs with 'Link' annotations actionable.
As it turns out, certain PDF generators do not create 'Link' annotations for URLs by default. For instance, Microsoft Word (macOS) did not create any 'Link' annotations when exporting into PDF format. Google Docs, however, did create a 'Link' annotation for every hyperlinked text when exporting into PDF format; yet, only the hyperlinked text were annotated.
For this reason, I looked into PDF text extraction frameworks such as GROBID and PDFMINER, hoping to try different ways to extract URLs from text. GROBID (i.e., GeneRation Of BIbliographic Data) is a library for extracting, parsing, and re-structuring PDF documents into structured XML/TEI encoded documents, with a particular focus on technical and scientific publications. PDFMINER, on the other hand, is a tool for extracting text data from PDF documents. I first implemented two PDF-to-Text converters using GROBID and PDFMINER, respectively. Next, using two Regular Expressions found online, I attempted to extract URLs from this text. In this manner, I created four text-based URL extractors (GROBID-R1, GROBID-R2, PDFMINER-R1, and PDFMINER-R2), where R1 and R2 are two regular expressions. Upon evaluating these extractors on the same sample dataset, I found that they extract more URLs than PyPDF2, but also extracts partial/invalid URLs (PyPDF2, in comparison, did not extract partial/invalid URLs). To reduce the number of false positives thus generated, we used two methods of filtering:
- Verifying the Top-Level Domain (TLD) of extracted URLs
- Maintaining a Blacklist of undesirable URLs
|
Description and examples of the two URL filtering methods |

To further reduce the false positives, we decided to combine the strengths of annotation-based and text-based URL extraction and create two-step URL extractors. The idea was to extract URLs from both PDF annotations and PDF text, with URLs from PDF annotations assumed valid, and the URLs from PDF text filtered thoroughly (e.g., verifying TLD of URLs, ignoring blacklisted URLs, and removing duplicate/partial/invalid URLs).
In the meantime, I explored how certain tools such as Chromium make URLs from PDF text actionable, regardless of whether they were annotated. I discovered that the sources for the PDF Library used by Chromium (PDFIUM) and the PDF Library used by Firefox (PDF.js) are publicly available on GitHub. Because Chromium, unlike Firefox, was able to detect URLs from PDF text, I decided to experiment with PDFIUM. As a result, I implemented another URL extractor (PDFIUM) and tested it alongside others.
 |
| Brief summary of different URL extraction tools used |
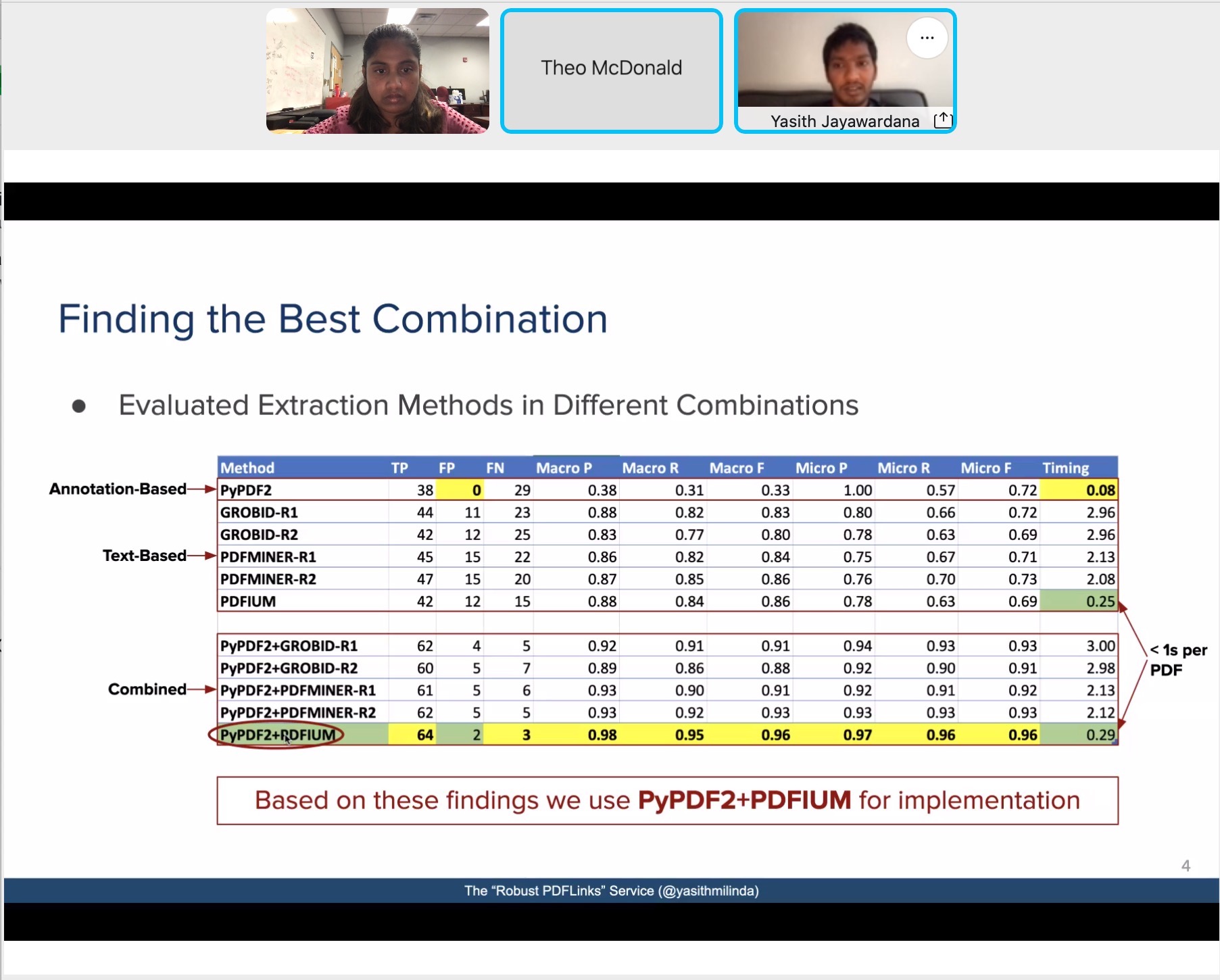
Surprisingly, the PDFIUM extractor only got 42/67 URLs correct, and also got 12 partial/invalid URLs, meaning its performance was on par with the text-based extractors, but worse than the two-step extractors. Upon investigating further, I noticed that all partial/invalid URL extractions from PDFIUM were due to newline characters. Following this, I implemented a two-step extractor using PDFIUM, which performed the best overall (64/67 URLs correct URLs, 2 partial/invalid URLs, and 1 missed URL), and ran the second-fastest (PyPDF2 extractor was the fastest).
|
Summary of Evaluation Results |

Stage 2: Implementation, Documentation
Next, I used the PyPDF2+PDFIUM extractor to building a Web service which provides the following functionality.
- Upload a PDF
- Extract URLs from a PDF
- Robustify a URL using the Robust Links service
A Robust Link is an HTML <a>...</a> tag which links to the original URL (URI-R), the URL of a snapshot of its content (URI-M), and the date-time when that snapshot was created.
A sample Robust Link
- Send a LDN with Robust Link mappings to a LD server
- Preview the PDF and Robust Links in a Web Browser

Next, I used the Flask framework to set up an HTTP API providing the above functionality. I created Web pages using HTML/JS/CSS to use this service through a Web Browser. Based on Dr. Klein’s feedback, I made iterative improvements to this Web service by fixing issues and refining the user experience. This solution can now be integrated into LANL Research Library systems that support Linked Data (LD). Upon receiving an LDN, they could, for instance, display an HTML overview of the PDF, its URI-Rs, and their robust URI-Ms.
Documentation
Initially I used Google Docs to create the project documentation. However, this proved to be difficult, especially because this involved maintaining two documentations:
- An HTML documentation for the Web service that can be viewed on a Web Browser
- A PDF documentation explaining functionality and instructions to set it up locally
Therefore, I thought of creating a unified documentation addressing both needs. I experimented with the Sphinx library, which allows to generate documentation from code comments and text, both written in ReStructuredText (RST). Using Sphinx made it easy to document the project functionality and code in one place, and generate both HTML and PDF versions of it. The project documentation thus generated, was more comprehensible than what I would have otherwise created on Google Docs.
|
The Robust PDFLinks documentation, in HTML Format |

|
The same documentation, in PDF Format |

Things I Learned
Prior to working on the Robust PDFLinks project, my knowledge on Web Archiving, Linked Data, and Regular Expressions was quite limited. Over time, I learned their basics and how to use them within the service. By exploring different tools and technologies to extract URLs from PDF documents, I gained first-hand experience on the challenges and limitations of doing so. This, in turn, helped me to build a 'robust' Robust PDFLinks service. I also learned that most PDF Viewers detect URLs from the PDF text, and they do so reasonably well. Therefore, I would recommend using the PDFIUM library to extract URLs from PDF documents. Also, when generating PDF documents, it's probably a good idea to ensure that URLs are properly annotated. This, in turn, would simplify the process of preserving the web content referenced by scholarly publications.
Events, Workshops, and Symposiums
While I was a teleworking employee, my internship experience at LANL was far from all-work-and-no-play. I never felt overwhelmed by the work; in fact, I took part in several events such as "Student Lecture Series - What's up with LANL Students?" and "Virtual Student Symposium 2021" to acquaint with other students at LANL and learn what they are working on. Moreover, I attended several workshops such as "LANL Career Opportunities Panel Discussion Series", "RASSTI Information Session", and "LANL Research Library Virtual Tour" to discover career opportunities at LANL, and to learn about different tools used at LANL.
On the last week of my internship, I presented what I did during my internship at the Mini Summer Student Symposium (MiSuSup) organized by the LANL Research Library. Here, I provided an overview of what the Robust PDFLinks service does, the technologies used to build it, and a demo of how it could be used on a Web browser.
 |
| A Picture of Me Presenting at MiSuSup 2021 |
Future Projections
Though the Robust PDFLinks service and its code are not publicly available, Dr. Klein and I plan to release an open-source version of it in the future. While this service was primarily aimed at robustfiying URLs in PDF documents submitted to LANL Research Library systems, the benefits of this service apply to any scholarly publication system. At a large scale, publishers can utilize such a service to pro-actively archive Web resources referenced in scholarly PDFs, and thereby retain a robust copy of them for future researchers. Moreover, what if one could embed Robust Links within PDF documents and access them via PDF viewers? I'd leave these ideas for future research.
Final Thoughts
Through this internship, I learned how to extract URLs from PDFs using several PDF processing tools, and how to extract portions of text using Regular Expressions. Furthermore, I learned how to robustify links using the Robust Links Service, and how the Memento protocol works in general. I also learned how to perform semantically-rich communications between Web services via the Linked Data Protocol. Overall, I believe that this experience and the professional network that I built through this internship is invaluable for my career, and I hope to utilize them to strengthen my ongoing and future research.
I would like to thank my PhD advisor, Dr. Sampath Jayarathna, for encouraging me to apply for an internship at LANL. I’m also grateful for my internship supervisor, Dr. Martin Klein, who recommended me for this position and guided me at every step. I am honored and thankful to have worked with him and the diverse, multi-disciplinary team at LANL as a Research Intern.
-- Yasith Jayawardana (@yasithmilinda)
Comments
Post a Comment