2020-03-07: At the nexus of the CNI keynote and Rosenthal’s response: “It's not an easy thing to meet your maker.”
Author's note: This document is a public companion to a private document that outlines a number of security vulnerabilities and exploits. Both documents were shared in October, 2019 with the Internet Archive, Rhizome, and other colleagues. This document is being published in January, 2020 at both blog.dshr.org and ws-dl.blogspot.com, but currently there are no plans to publish the private document.
At the nexus of the CNI keynote and Rosenthal’s response: “It's not an easy thing to meet your maker.”
Michael L. Nelson
2019-10-11
One of the high points of my career is the invitation from Cliff Lynch for the Spring 2019 CNI Keynote and his gracious introduction prior to my speaking. Unfortunately, I’ve since discovered that the antidote for a Cliff Lynch “high” is a negative review from David Rosenthal, a revered researcher with a storied career, a valued colleague, and occasional co-author. For example, in our research group our graduate students keep track of “DSHR points”, with a point awarded for each time Rosenthal mentions you or your work by name in his blog (Sawood Alam currently leads with six points, followed by Shawn Jones with three). The areas where Rosenthal and I agree are too numerous to list, so at the risk of sounding like the Emo Philips joke, I provide my response to his three part disquisition about my keynote (slides, video).
I argue that his disquisition has a number of significant misunderstandings of the original message, and it is simultaneously fatalistic regarding not trusting anything on the web as well as uncharacteristically optimistic about the state of the art of web archive security. These perspectives combine to produce an analysis that fails to fully appreciate the as of yet still theoretical possibilities of web archives not simply being the object of an attack (such as censorship or denial-of-service), but rather as the launchpad of a larger disinformation attack. There is precedence: email has given rise to spear phishing; Wikipedia, hoaxes and state-sponsored edit wars; and social media, bots, trolls, and brigades -- attack vectors and real world impacts that designers of the respective systems likely never foresaw. I would like for us to not repeat those mistakes, and thus the web archiving community must consider not just protecting the web archives, but also protecting us from the web archives.
The keynote was a high-level review, targeted for a CNI audience with a familiarity of web archiving, but not indulging in technical detail (though most slides have links for additional information). The blog format of my response allows for greater detail about web archiving (and Blade Runner), and thus will necessarily shrink the applicable audience. Quotes from DSHR’s articles are in courier.
“Memories, you're talking about memories.”
Taken as a whole, Nelson seems to be asking:
Can we take what we see from Web archives at face value?
The talk does not pose a question, it makes an assertion, which is stated after the narrative framing of “Blade Runner” is introduced (slide 13):
Web archives are science fiction.
Web archives are enabling a reality, as foreseen by PKD and other sci-fi authors, where we can insert bespoke fakes into our collective memory.
Nelson is correct that the answer is "No", but there was no need to recount all the detailed problems in his talk to arrive at this conclusion. All he needed to say was:
Web archive interfaces such as the Wayback Machine are Web sites like any other. Nothing that you see on the Web can be taken at face value.
The above statement suggests an important distinction: the talk is not about taking web pages at face value. That would be a talk about methods for detecting disinformation (Maddock et al., 2015), networks for disinformation propagation (Shao et al., 2018), the impact of exposure to disinformation (Starbird, 2019), distinguishing disinformation from satire (Golbeck et al., 2018), etc. My talk is about the role that web archives have in either verifying or subverting the metadata about an archived page. We have so completely accepted the role of web archives, especially the Internet Archive’s Wayback Machine, as a neutral arbiter of the web’s history that we are completely unprepared for the implications resulting from this frame of reference being either wrong or malign.
To illustrate, let’s consider this now-deleted tweet:
It contained the text “U decide - NYPD Blows Whistle on New Hillary Emails: Money Laundering, Sex Crimes w Children, etc...MUST READ!” with an embedded link. The Internet Archive has the tweet archived at:
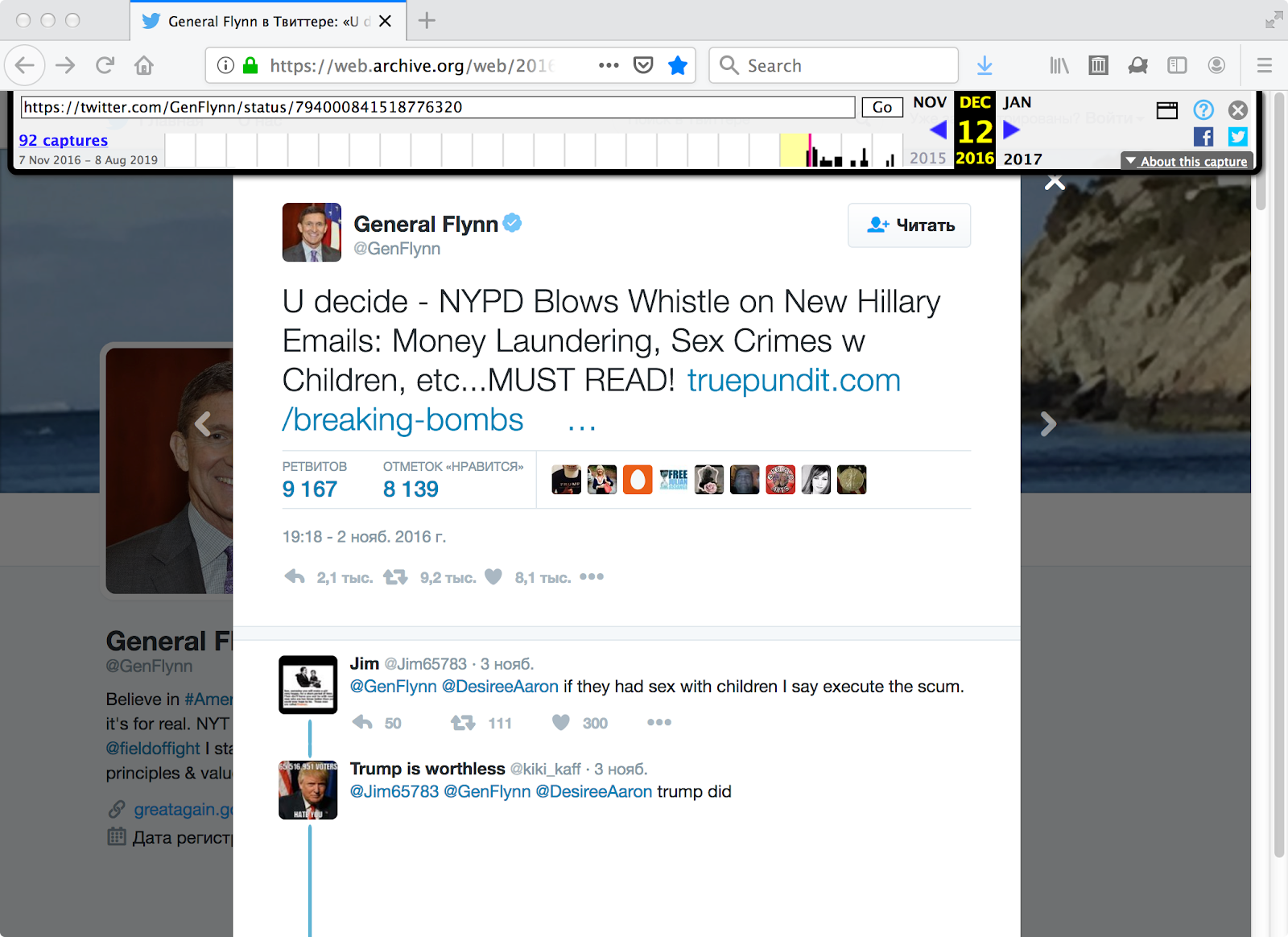
A copy of General Flynn’s tweet in the Internet Archive’s Wayback Machine. Although the user-supplied text is in English, the template text (date, retweets, likes, etc.) are in Russian.
I can immediately know that both the tweet and the page it links to are disinformation and not to be taken at face value, although for those without the necessary cultural context such an assessment might not be as obvious.
However, given the tweet’s existence in the Internet Archive’s Wayback Machine, most people do take at face value that:
- The tweet existed,
- the content (text and link) have not been altered, and
- the metadata (posted 2016-11-02, from the account “@GenFLynn”, with several thousands of retweets, likes, etc.) was not altered, and
- it was still on the live web as of 2016-12-12.
To simply dismiss these four facts with some variation of “web archives are ultimately just web sites like any other, so you shouldn’t trust them”, while true, fundamentally misses how the vast majority of people interact with the Internet Archive’s Wayback Machine. Of course, General Flynn is an admitted liar and should not be trusted, but Rosenthal too easily discounts the great reservoir of trust for information served from the domain of archive.org. I “recount all the detailed problems” not to warn about archiving the absurdity of General Flynn’s message, but to stress that archive.org can be attacked or coerced into faking the tweet’s temporal duration (#4), metadata (#3), contents (#2), and even its very existence (#1).
Web archives present their own branded version of information harvested from other domains, and the process of copying and transformation introduces opportunities for disinformation that are not yet fully understood. To simply dismiss these threats with “[n]othing that you see on the Web can be taken at face value” is unnecessarily pedantic, epistemologically regressive, and ill serves the web archiving community.
Although I am unaware of an academic study that evaluates the public’s trust in the Internet Archive, my intuition is that people expect it to faithfully record pages, including disinformation, but not to be engaged in disinformation itself. I further argue that this wholesale trust is not because web archives are somehow immune to disinformation, but rather they have not yet experienced a high-profile exploit (cf. slides 42--46).
Nelson sees it as a vulnerability that people believe the Wayback Machine is a reliable source for the Web's history. He is right that malign actors can exploit this vulnerability. But people believe what they see on the live Web, and malign actors exploit this too. The reason is that most people's experience of both the live Web and the Wayback Machine is that they are reasonably reliable for everyday use.
Yes, absolutely, there is a vulnerability and we have an obligation to alert those who are responsible and those who could be impacted. And yes, people continually fall for phishing, edited screenshots, fake captions, remixes, and numerous other forms of disinformation on the live web despite the transparency of these attacks. If, for example, military contractors do not know the difference between emails from “navy-mil.us” vs. “navy.mil”, then we should not expect the audience outside of CNI members and the readers of this blog to appreciate the nuances of temporal spread and temporal violations.
The structure I would have used for this talk would have been to ask these questions:
- Is the Wayback Machine more or less trustworthy as to the past than the live web? Answer: more.
- How much more trustworthy? Answer: significantly but not completely.
- How can we make the Wayback Machine, and Web archives generally more trustworthy? Answer: make them more transparent.
Here we get to a fundamental issue: a good portion of the three blog posts are about the talk that he would have given. Rosenthal has given numerous, well-received keynotes and invited talks at CNI and many other venues. There’s room for more than one talk on trust and web archives, and I look forward to his future presentation where he gives the talk he outlines in his three posts.
My first big issue with Nelson's talk is that, unless you pay very close attention, you will think that it is about "web archives" and their problems. But it is actually almost entirely about the problems of replaying archived Web content.
…
Many of my problems with Nelson's talk would have gone away if, instead of saying "web archives" he had said "web archive replay" or, in most cases "Wayback Machine style replay".
You know how when someone uses the term “America” or “Americans”, as in “Many Americans evidently believe that…”, and although it is technically incorrect and/or ambiguous, through convention and context everyone somehow knows what you’re talking about? It’s like that.
“The essence of a web archive is to modify its holdings”
and not:
“The essence of a web archive is to modify its holdings during replay”.
However, in the talk I say (11:24, emphasis added):
“We can see what the web archive -- when it is replayed through the Internet Archive’s Wayback Machine -- it rewrites the links and it also inserts a banner to let you know metadata about the past. It was captured at this date, it is a copy of this URL, there are these additional copies available. It is completely transforming the page to give us a simulation of the past.”
The slides elsewhere mention “replay” eight times and “playback” three times. Furthermore, Rosenthal notes that the slides mention his 2005 paper about transparent content negotiation -- a paper he and I have discussed in the past, as well as noting our two different proposals for standardizing requests for “raw” vs. “rewritten” archived pages.
In summary, I know when and how Wayback Machines modify pages on replay. Rosenthal knows that I know this. The narration and other slides provide ample context to make this distinction clear.
Nelson hardly touches on the problems of ingest that force archives to assemble replayed pages from non-contemporaneous sets of Mementos.
This is by design: the talk explicitly references problems with ingest only three times (slides 34, 40, 53), and implicitly references them five times (slides 30, 31, 35, 36, 39). Our group has extensively investigated the problems of ingest and replay (a sampling, many of which are linked to from the slides: blog 2012, TempWeb 2013, JCDL 2013, blog 2013, JCDL 2014, blog 2014, tech report 2014, HyperText 2015, iPres 2015, IJDL 2016, dissertation 2016, blog 2016, blog 2017a, blog 2017b, JCDL 2017a, JCDL 2017b, blog 2018, thesis 2018, WADL 2019). My assessment is that the nuances of scheduling, intricacies of JavaScript and cookies, and the mechanics of HTTP would make for a rather dry keynote presentation.
His discussion of the threats to the collected Mementos between ingest and dissemination is superficial. The difference between these issues and the problems of replay that Nelson describes in depth is that inadequate collection and damage during storage are irreversible whereas replay can be improved through time (Slide 18).
While not exhaustive, “superficial” is not a fair characterization: slides 47--52 (implicitly trusting web archives to act in good faith), 63 & 64 (individual administrators can be threatened and compromised), 65--67 (public web archives could be created specifically for disinformation purposes), and 68 & 69 (legal coercion).
Furthermore, if “replay can be improved through time” but simultaneously there is “no need to recount all the detailed problems” and my recounting is “misleading and somewhat counter-productive”, how exactly does replay improve? Have I violated the first rule of replay club?
Nelson even mentions a specific recent case of fixed replay problems, "zombies" (Slide 30).
Note that slide 30 says “mostly no longer occur”. The attack John Berlin demonstrated on slide 61 has several components, one of which is the Brian Williams YouTube video is not replayed from the archive, but instead is played from the live web. In a separate, private document shared only with colleagues, I have further demonstrated additional attacks, one specific to the Internet Archive’s Wayback Machine, and one that impacts all Wayback Machine implementations and thus by extension the oldweb.today interface that aggregates those Wayback Machine implementations. At the risk of sounding like a horror movie trope, zombies still exist.
Ingest is vulnerable to two kinds of attack, in which Mementos unrepresentative of the target Web site end up in the archive's holdings at the time of collection: [...]
I agree with these statements. They are also out of scope for my keynote.
Preservation is vulnerable to a number of "Winston Smith" attacks, in which the preserved contents are modified or destroyed after being ingested but before dissemination is requested.
I agree with this statement. This is exactly the point of slides 47--52, 63 & 64, 65--67, and 68 & 69.
Dissemination is vulnerable to a number of disinformation attacks, in which the Mementos disseminated do not match those stored Mementos responsive to the user's request. Nelson uses the case of Joy Reid's blog (Slide 33) to emphasize that "Winston Smith" attacks aren't necessary for successful disinformation campaigns. All that is needed is to sow Fear, Uncertainty and Doubt (FUD) as to the veracity of Web archives (Slide 41). In the case of Joy Reid's blog, all that was needed to do this was to misinterpret the output of the Wayback Machine; an attack wasn't necessary.
There’s a lot to unpack here. First, there is an emerging consensus that the definition of “misinformation” is “false information”, whereas “disinformation” is generally defined “false information with the intent to deceive.” Intentionality is important, because the temporal violations in Reid’s blog (slide 34) are not intentional, they are side effects of the crawling and replay mechanisms of Wayback-Machine-based archives. The Lester Holt example of slides 38 & 39 are similarly the result of crawling and replay errors.
To cite slide 41 in support of the Joy Reid example is to miss an important point: web archives, or at least Wayback Machine style archives, produce misinformation as a result of their regular operation. As slide 40 states “Errors in crawling and playback are hard to distinguish from tampering”. Slides 40 & 41 are specifically about disinformation, as it is enabled by misinformation. The misinformation generated by crawling and replay errors opens the door for disinformation attacks.
Finally, characterizing the Joy Reid blog post example in slide 34 as “misinterpret[ing] the output” undersells the nuance and complexity of what happened in the convergence of the HTML, JavaScript, and replay: the JavaScript does not anticipate being out of sync with the corresponding HTML and interprets the missing array elements as the blog posts have zero comments. The JavaScript modifies the HTML output accordingly, and its silent failure does not leave the tell-tale signs of a missing image or iframe, nor the janky placement of page elements one would expect with a missing stylesheet.
Although the “correct interpretation” is clear in retrospect, to the best of my knowledge I was the only person, of the many people inspecting Reid’s archived pages at that time, to discern the reason for the lack of comments for the blog posts. And why should they have dug deeper in the HTML and JavaScript? Other than underreporting the comment count, the rendered page met our expectations, with no visible signs of error; they in fact took this page “at face value”, which is not the same as “misinterpret[ing] the output”.
Below is a screenshot of the Joy Reid blog post in question. At the time, the version at archive.org was blocked and the copy at loc.gov was used instead, but this screenshot shows IA’s “about this capture” tab expanded. Note that 1) there is significant spread of resources required to replay the page, and 2) the temporally violative resource with a semantic impact (haloscan.com) is only 8th in the list and is not flagged in red. While surfacing the temporal spread information in the replay banner is a welcome UI advancement, temporal spread itself is not the problem; temporal violations are the problem and they are more difficult to compute.
Since the spread is a function of a particular replay session, the spread will be different on every replay and thus difficult to provide in a stable and machine-readable manner. For example, the second replay of the same memento at IA shows a new embedded resource, erroneously claiming to be archived 36 years before capture date of the HTML page.

The temporally violative resources from haloscan.com are not marked in red.

After a reload (relative to the rendering in the previous figure) of http://web.archive.org/web/20060111221738/http://blog.reidreport.com/, a new embedded resource is included claiming to be archived at the Unix epoch (January 1, 1970).
For reference, below is the same Reid blog post replayed in oldweb.today. The HTML page is captured in 2006, but the embedded resources span from 2005 to 2018. The violative resource from haloscan.com is subsumed in the 13 year spread.
Although an argument can be made that the current tools actually do more harm than good in presenting a web archiving form of false precision, I present these examples not as criticisms of the Internet Archive’s Wayback Machine or oldweb.today. Instead, I want to stress that much research and development remains to be done regarding temporal transparency and that the solutions are not just a matter of incremental improvements in the UI.
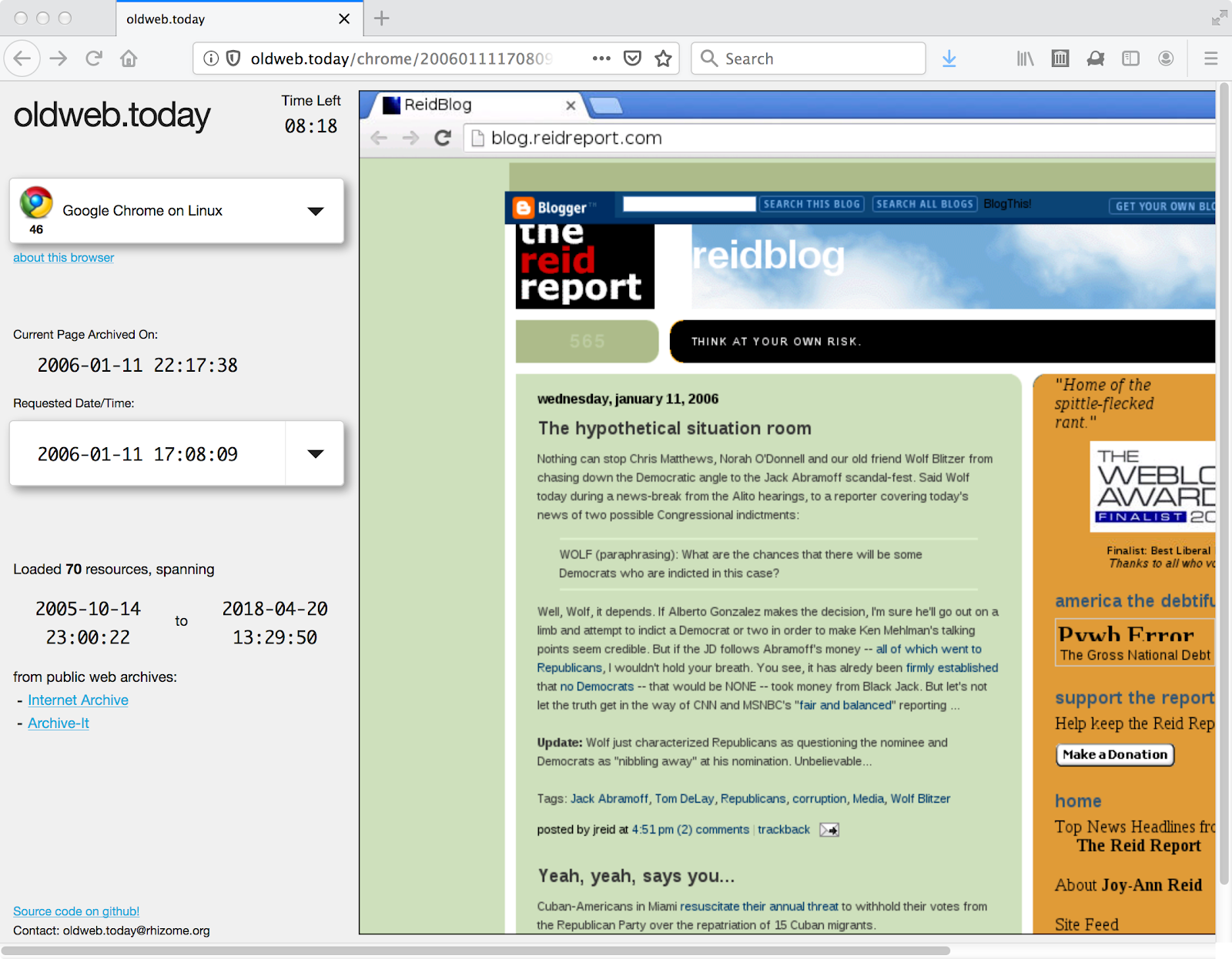
The temporal spread for http://oldweb.today/chrome/20060111170809/http://blog.reidreport.com/ is approximately 13 years. Resources from two archives, the Internet Archive and Archive-It, are aggregated to replay this page.
Insider attacks (Slide 51, Slide 64),which can in principle perform "Winston Smith" rewriting attacks. But because of the way preserved content is stored in WARC files with hashes, this is tricky to do undetectably. An easier insider attack is to tamper with the indexes that feed the replay pipeline so they point to spurious added content instead.
Slides 47--52, 63 & 64, 65--67, and 68 & 69 are about insider attacks in general; nothing about them is limited to rewriting attacks. Indeed, Winston Smith need not limit himself to rewriting; this statement “...because of the way preserved content is stored in WARC files with hashes, this is tricky to do undetectably” is far too optimistic about our current ability to verify the integrity of resources in web archives.
First, WARC files have hash values themselves, but WARC files are not accessible from the Internet Archive (nor other web archives) for regular users (by “regular users” I mean “not researchers or developers” and “unlikely to use APIs”). Furthermore, in general there is not a 1-1 relationship between web pages and WARC files. For example, to render this archived cnn.com page requires 102 embedded archived resources plus the base HTML, and those 103 archived resources are distributed across 20 different WARC files:
The hash values (calculated at crawl time) for the 103 archived resources are available via the Internet Archive’s Wayback Machine CDX API (note: of the 20+ public web archives, currently only the Internet Archive’s Wayback Machine (plus their subsidiary, Archive-It), and Aquivo.pt support and/or publicly expose this API). Currently there is no UI that takes advantage of these hash values -- they are only revealed via the API.
Furthermore, in general the hash values for archived resources are not stored with an independent, third party, so there is no ability for a meaningful audit. Presumably the Internet Archive has internal procedures in place to prohibit insider attacks, but I am unaware of any public description of them. Lacking such knowledge, “trivial” -- not “tricky” -- is the better word to describe the susceptibility to insider attacks.
Finally, conventional fixity techniques are not generally suitable for web-based audit of archived resources (even when using “raw” mode). Slides 76--85 show some of the results of our ongoing work in this area. The experiment details are beyond the scope of the keynote (and this blog post); the CNI Fall 2018 presentation “Blockchain Can Not Be Used To Verify Replayed Archived Web Pages” gives further information about our work that is being prepared for submission.
Using Javascript to tamper with the replay UI to disguise the source of fake content (Slide 59). Although Nelson shows a proof-of-concept (Slide 61), this attack is highly specific to the replay technology. Using an alternate replay technology, for example oldweb.today, it would be an embarrassing failure.
It is true that the attack demonstrated in slide 61 is “highly specific to the replay technology”, it is even more accurate to say that it is highly specific to the particular web archive, namely the Internet Archive’s Wayback Machine. However, as Rosenthal writes in part 3 of his response:
“...archive.org is the 232-nd most visited site on the Internet, far outranking national libraries such as the Library of Congress (#4,587) or the British Library (#13,278).”
Considering these numbers, attacks that are specific to the Internet Archive Wayback Machine are still going to be highly successful.
A reminder, as noted above, slide 61 actually demonstrates two attacks: faking the UI, and loading content from the live web. Replaying the page through oldweb.today successfully mitigates both attacks. However, this is security whack-a-mole: without divulging the details here, while oldweb.today (not just the current service, but the modality it demonstrates) mitigates certain attacks, it is susceptible to other attacks. With additional attention to detail, a hybrid attack in a single page can detect the replay system in which it is active and effect the same illusion with different techniques, or cloak itself as a transient replay error (e.g., HTTP 503) if it is active in a replay environment for which it has no convincing illusion. In other words, the next generation of web archive attacks will likely have no “embarrassing failure[s]” because those attacks will be carefully instrumented to check if they have the ability to be successful, and if not return a cryptic, faux-error page instead of a failed, incomplete illusion.
Let me be very clear: replaying archived JavaScript, combined with other Wayback Machine design considerations, will always be a security hole. Because archived pages will continue to be able to access the live web, pages legitimately archived yesterday will be able to load custom illusions tailored for tomorrow’s replay system. Replaying JavaScript is the web archiving equivalent of the gets() buffer overflow: a known vulnerability that we are hesitant to address, and we are counting down to its first widespread exploit.
Deepfakes (Slide 56). This is a misdirection on Nelson's part, because deepfakes are an attack on the trustworthiness of the Web, not specifically on Web archives. It is true that they could be used as the content for attacks on Web archives, but there is nothing that Web archives can do to specifically address attacks with deepfake content as opposed to other forms of manipulated content. In Slide 58 Nelson emphasizes that it isn't the archive's job to detect or suppress fake content from the live Web.
First, and perhaps because, as he makes clear in Part 2, he’s not a particular fan of “Blade Runner”, the point of slide 58 is not even close to what Rosenthal states. The point is that “eliminating” or “preventing” of deepfakes (for example, as promised by the products and stories on slides 71 & 72) is not going to happen. Although primarily discussed in the context of disinformation, revenge porn, and other unsavory applications, audio and video deepfakes are the latest technological iteration of capabilities that we, as a society, have always pursued (e.g., slides 54 & 55). For example, armed with both the present cultural context and the skepticism informed by living 30+ years in a post-Photoshop world, we immediately recognize the various altered images in “#unwantedivanka”, some of them quite well-executed, as fake and satire. Although audio and video are far more persuasive than still images, it is not hard to imagine that in the years to come we will acquire similar inoculation to deepfakes as we have for altered images. I, as a Blade Runner super fan, look forward to inserting myself via a deepfake into the “Tears in Rain” monologue (slide 102), but those familiar with the film will immediately recognize that I am not Rutger Hauer.
The larger point is that web archives will be used to increase the disinformation impact of deepfakes; slide 59 literally gives a step-by-step approach on how to do this. Drawing from the example in slides 38 & 39, a deepfake of the Lester Holt interview shared on social media will have a significant capacity for disinformation, a hypothetical deepfake of the Lester Holt interview shared on social media that convincingly appears to have been archived from nbcnews.com in May, 2017 will have an even greater capacity for disinformation. The public has trust in Lester Holt and nbcnews.com and the public also has trust in archive.org, but the combination currently yields misinformation. I am hard pressed to think of a more attractive deepfake / disinformation vector regarding NBC’s May 2017 interview than the Internet Archive’s current archived page.
Let me restate, to make clear there is no “misdirection”: deepfakes, in combination with known attacks on web archive replay, will exploit the existing trust in web archives -- especially pages served from web.archive.org -- to further the reach of their disinformation campaigns.
In Slide 62, Nelson points to a group of resources from two years ago including Jack Cushman and Ilya Kreymer's Thinking like a hacker: Security Considerations for High-Fidelity Web Archives and my post about it. He says "fixing this, preventing web archives being an attack vector, is going to be a great deal of work". It isn't "going to be", it is a ongoing effort. At least some of the attacks identified two years ago have already been addressed; for example the Wayback Machine uses the Content-Security-Policy header. Clearly, like all Web technologies, vulnerabilities in Web archiving technologies will emerge through time and need to be addressed.
This section reveals a surprising and undeserved level of optimism. Yes, the Internet Archive’s Wayback Machine now includes a Content-Security-Policy header, as a result of Lerner’s 2017 paper (Lerner’s paper also resulted in the “about this capture” functionality discussed above), which blocks the easiest method for injecting live web resources into archived web pages but does not block all methods. And, as of this writing, only Archive-It (also run by the Internet Archive) and the Icelandic Web Archive have also implemented this header but all the other public web archives using Wayback Machines are still at risk, despite the simplicity of including the Content-Security-Policy header in all HTTP responses.
Furthermore, as mentioned in slide 30 (which Rosenthal explicitly calls out in an earlier section), live web leakage (AKA “Zombies”) is only partially addressed by the Content-Security-Policy header. Rosenthal doesn’t mention John Berlin’s MS Thesis, also on slide 62, in which a zombie attack is demonstrated even after implementing the Content-Security-Policy header. In a separate document I have also shared with Rosenthal and others a suite of additional attacks that also effectively allow live web resources to be included in replayed pages.
The Cushman & Kreymer presentation (also from 2017) highlights seven classes of threats, and the Lerner et al. paper introduces three broad classes of threats. Their terminology and granularity differ, but in both descriptions the Content-Security-Policy header only (partially) addresses a single class. Some recommendations, such as from Cushman and Kreymer of running the archiving application and the archived pages in different domains, are going to be difficult to implement for a legacy archive than simply adding a single HTTP response header. For example, the threat class Lerner et al. names “Never-Archived Resources and Nearest-Neighbor Timestamp Matching”, is so intrinsic to the Wayback Machine idiom that it is not clear how it could be mitigated: it simultaneously provides great utility and a gaping security hole. This is an example of why I say “[t]he Heritrix / Wayback Machine technology stack, while successful, has limited our thinking.”
Let me reiterate for clarity: "fixing this, preventing web archives being an attack vector, is going to be a great deal of work".
Slide 69 provides an example of the one of two most credible ways Web archives can be attacked, by their own governments. This is a threat about which we have been writing for at least five years in the context of academic journals. Nelson underplays the threat, because it is far more serious than simply disinformation.
Governments, for example the Harper administration in Canada and the Trump administration, have been censoring scientific reports and the data on which they depend wholesale. [...]
The examples Rosenthal cites are serious, important, immediate, and numerous enough to warrant their own keynote. However, Rosenthal misses an important distinction: he recounts examples of attacks on web archives, while the focus of my presentation is attacks launched from within web archives.
The example in slide 69 provides an analogy for this distinction: the US Government launched a disinformation campaign from within the DNS registry. Their disinformation campaign would likely have been successful even with “universityoffarmington.com”, but the ability to register “universityoffarmington.edu” surely increased their capacity for deception. Many TLDs no longer have meaningful semantics (e.g., .com, .net., .org), but some still do: not just anyone can register a .gov, .mil, or .edu domain. There are examples of diploma mills and visa mills with “.edu” domains, but they are clearly a different kind of “fake” than the University of Farmington. Perhaps the US Government deceived EDUCAUSE while registering “universityoffarmington.edu”, but my guess is they arrived with a court order (or the threat of one) and convinced them to waive their criteria for eligibility.
As the public awareness of web archives grows, it’s not hard to imagine that future sting operations will procure court orders for web archives to fabricate back-dated web pages, complete with the web aesthetics of the era, to establish that “universityoffarmington.edu” has been archived since 1996 and not just since 2016.
Justin Littman described in 2017 the framework for a related version of this kind of attack. Using deleted and re-registered accounts (similar to dropped domains, but with account names) an attacker leverages the legitimately archived mementos of Twitter accounts (in his description, those of official government accounts) to increase the appearance of authenticity of the mementos of the subsequent “fake” accounts.
The other most credible way Web archives can be attacked is, as the Joy Reid case illustrates, by the target Web site abusing copyright or robots.txt. I wrote a detailed post about this last December entitled Selective Amnesia. The TL;DR is that if sites don't want to be archived they can easily prevent it, and if they subsquently regret it they can easily render the preserved content inaccessible via robots.txt, or via a DMCA takedown.
As per the previous section, these arguments are out of scope since both robots.txt and DMCA are external attacks with goal of limiting web archives from disseminating information, and not attacks launched from within the archive.
Furthermore, Rosenthal’s understanding of the Internet Archive’s treatment of robots.txt is stale. Shortly after the 2016 election, the Internet Archive announced they would no longer honor robots.txt for .gov and .mil sites. A few months afterwards, they announced that based on experiences with .gov and .mil, they were “...looking to do this more broadly”. There were many factors that allowed the forensics of the Joy Reid blog, including it being archived in multiple web archives, but the final arbiter was the Internet Archive choosing to no longer enforce robots.txt for her blog. A restrictive robots.txt still exists on the live web, but archived pages with evidence in question are now replayable by all.
To the best of my knowledge there is no official statement of where the Internet Archive’s Wayback Machine is in the spectrum of “looking to do this more broadly”, but the Wayback Machine has many possible error messages, makes a distinction between “Blocked By Robots” and “Blocked Site Error”, with the latter being the one you are most likely to encounter.
“Have you ever retired a human by mistake?”
But Nelson doesn't address the fundamental issue that Web archive replay interfaces are just Web pages. Thus expecting Web archive replay to be more reliable than the medium from which it is constructed is unrealistic.
Although I regret omitting the slide I’ve used many times elsewhere that explicitly states “Archives aren’t magic web sites -- They’re just web sites”, slides 78--85 illustrate multiple examples of replay not being reliable. It is an overreach to say this issue is not addressed.
Especially since, unlike most other Web sites, the function of a Web archive is to hold and disseminate any and all externally generated content.
The archive has no control over its content in the sense that platforms do. Despite being massively resourced, control over content or "content moderation" doesn't work at scale for Facebook, YouTube or Twitter. For web archives it would not merely be technically and economically infeasible, it would be counter to their mission. As Nelson shows, they are thus vulnerable to additional attacks from which "content moderation" and similar policies would protect sites like Facebook, if they worked.
While “Universal Access to All Knowledge” is the mission of the Internet Archive, this is clearly not true for all web archives. For example, the majority (approximately 40 of 57) of IIPC members are national libraries or national archives with collection development policies more restrictive than “any and all externally generated content”. Instead, these archives area aligned with a language, region, or country code top-level domain (e.g., Arquivo.pt – the Portuguese web-archive). This is to say nothing of the many universities, libraries, and other levels of government performing web archiving, either internally (e.g., the Stanford Web Archive Portal (SWAP) and its collection development page) or through contract crawling via services such as Archive-It, archiefweb.eu, and MirrorWeb (e.g., the 31 collections in Archive-It managed by the Utah State Archives and Records Service). The very purpose of these archives is to exercise control over the content they ingest. For example, the Internet Archive did yeoman’s work archiving the NSFW Tumblr blogs before they were marked private and effectively removed from the live web. However, no one expects to find these Tumblrs in Aquivo.pt, SWAP, or the Utah State Archives because they do not fit the collection development policies of these archives.
The issue of what we should and should not archive is far from a settled issue (cf. the 2018 National Forum on Ethics and Archiving the Web) and is beyond the scope of what we can address here, but I’ll note that there is evidence that the Internet Archive does perform content moderation, even when not legally required to do so. Their current approach is nothing like the scale of YouTube, Facebook, etc., but to borrow from slide 42 “...web archives are not immune. It’s just the theater of conflict has yet to expand to include web archives.”
Diversity in Web archiving is a double-edged sword because:
- The ability to compare content archived using different crawlers, stored in independent archives using different storage technologies in varying jurisdictions, and replayed using different technologies is fundamental to the credibility of society's memory of the Web.
- But the presence of multiple Web archives, of varying trustworthiness (Slide 52) in itself can cause FUD, opens the door for malign archives (Slide 66), and plays against the Web's "increasing returns to scale" economics.
In other presentations, I have presented a web archiving version Segal’s Law (“A person with a watch knows what time it is. A person with two watches is never sure.”)
In Slide 67, Nelson asks "What if we start out with > (n/2) + 1 archives compromised?" and cites our Requirements for Digital Preservation Systems: A Bottom-Up Approach. This illustrates two things:
- Web archives are just Web sites. Just as it is a bad idea to treat all Web sites as equally trustworthy, it is a bad idea to treat all Web archives as equally trustworthy (Slide 52). This places the onus on operators of Memento aggregators to decide on an archive's trustworthiness.
This is true, of course. It’s also a good opportunity to revisit the lesson of slides 43--46: collectively, we’ve never sufficiently considered a new, web-based information system with the proper skepticism of “I wonder how this useful tool I’ve come to depend on will eventually be used against me?”, in part because of the assumption that the initial high-cost of entry has discouraged bad actors (slides 48--50). Yes, this 1980s trust model works for the small community of archives and aggregators now, but for how much longer? Aside from informed intuition, how shall these “roots” assess an archive’s trustworthiness, especially since, as Rosenthal says, the “state of Web archive interoperability leaves much to be desired”? Furthermore, the history of Facebook, Gmail, Alexa, etc. suggests that if people are forced to choose between convenience and trustworthiness, convenience will eventually win.
It is also a good time to revisit slide 52, and consider the halo effect that the Internet Archive’s Wayback Machine has on all other projects that share the terms “Archive” and “Wayback Machine”. Regular users (e.g., those outside the audience of CNI and this blog) are not likely to distinguish between archive.org, archive.is, and archive.st -- all legitimate web archives. Now imagine the domain internet-archive.org or web-archive.org that looks and feels like archive.org, and proxies archive.org’s holdings for all but a few select pages. This is a standard attack in other domains, but one not yet executed in the web archiving community.
- The "> (n/2) + 1 archives compromised" situation is a type of Sybil attack. Ways to defend against Sybil attacks have been researched since the early 90s. We applied them to Web archiving in the LOCKSS protocol, albeit in a way that wouldn't work at Internet Archive scale. But at that scale n=1.
Nelson claims that LOCKSS assumes all nodes are initially trustworthy (video 43:30) , but this is not the case. He is correct that the LOCKSS technology is not directly applicable to general Web content, for two reasons: [...]
That was a misstatement on my part. But the point remains, as per slide 67, “What if we start off with > (n/2)+1 archives compromised?”. Not only is LOCKSS not suitable for general web content, the web archiving community is nowhere near ready to implement this level of interoperability (slide 87). For example, even accessing raw Mementos in web archives remains ad-hoc, with the Internet Archive’s Wayback Machine and OpenWayback implementing the first set of modifiers, pywb creating a superset of those modifiers, perma.cc effectively making raw Mementos undiscoverable from the UI (e.g., you cannot just add “id_” in the URL https://perma.cc/3HMS-TB59 to arrive at the corresponding raw Memento), and (the now defunct) Internet Memory supporting a different syntax altogether.
Of course, to the extent to which Web archiving technology is a monoculture, a zero-day vulnerability could in principle compromise all of the archives simultaneously, not a recoverable situation.
It turns out that the Web's "increasing returns to scale" are particularly powerful in Web archiving. It is important, but only one of many Internet Archive activities:
Adding hardware and staff, the Internet Archive spends each year on Web archiving $3,400,000, or 21% of the total.
It isn't clear what proportion of the global total spend on Web archiving $3.4M is, but it appears to preserve vastly more content that all other Web archives combined. Each dollar spent supporting another archive is a dollar that would preserve more content if spent at the Internet Archive.
This is true, and an update on the old saw “Nobody ever got fired for buying IBM”. If I were a library director charged with web archiving, I would choose an Archive-It subscription as well -- it’s an excellent service, and the economies of scale are undeniable.
At the same time, I applaud the directors at Harvard’s Library Innovation Lab and Rhizome for not spending their dollars with the Internet Archive, and instead risking the investment in public services and open source technology stacks. Not because the Internet Archive does not deserve our financial support (I’ve been a monthly donor since 2014), but because the web archiving community benefits from technological diversity.
What Is This "Page" Of Which You Speak?
[...]
Because of the way Nelson talks about the problems, implicit throughout is the idea that the goal of Web archiving is to accurately reproduce "the page" or "the past". But even were the crawler technology perfect, there could be no canonical "the page" or "the past". "The page" is in the mind of the beholder. All that the crawler can record is that, when this URL was requested from this IP address with this set of request headers and this set of cookies, this Memento is the bitstream that was returned. [...]
This section reveals a significant misunderstanding. Of course a general page on the live web is going to vary, even if accessed simultaneously, depending on who is viewing, from where, and with what user-agent and HTTP request headers, resulting in the pathological upper limit of “6.8*1011 possible versions of every Web page for each browser and device combination” as Rosenthal computes.
Such variations are well-known within the community. My talk is not about the variations of the live web page, it’s about the variations of the replayed archived page, even when discounting the banners, rewritten links, and other content injected by an archive on conventional replay.
Indeed, the situation is much worse than Rosenthal initially states: Web archives can not reliably give the same answer for the question “what was returned on this date, for this combination of IP addresses, request headers, and cookies?”, thus even a single version of a page with “6.8*1011 possible versions” continues to fluctuate even after it has been archived. Slide 83 shows that approximately one in six archived pages (2,773 of 16,627) are different every time they are replayed (35 times over an 11 month period). This includes “raw” mode, where the archive should perform no modification on the page.
This is probably a good time to revisit the assertion that “archives aren’t magic web sites, they’re just web sites”, and indeed most of the reasons for the large number of failures to replay the “same page” have to do with common, well-known issues with Wayback Machines, HTTP, and even TCP/IP. But the inability to replay the same archived page over time runs counter to what most people believe web archives do, I suspect even within a CNI audience.
Unlike the replayed version of Reid’s blog that never existed, the archived version of General Flynn’s tweet is one of the “6.8*1011 possible versions” available at that Original URI at 2016-12-12T08:53:55. Although it is likely that this incomplete reconstruction represents a version that was visible only to the Internet Archive, in part because of how Heritrix and Twitter interact, at least the page is not temporally violative. Furthermore, roughly speaking, there is a one in six chance that the 2016-12-12T08:53:55 archived version will be slightly different every time you replay it. The resources to better synthesize this archived page might exist in the Internet Archive’s Wayback Machine, or perhaps in other archives. With additional investment in replay systems, in the future it may be possible to better approximate the 2016-12-12T08:53:55 version (cf. Webrecorder’s “patch” function). That’s the page of which I speak.
"The essence of a web archive is ...
... to modify its holdings" (Slide 16).
I find this a very odd thing for Nelson to say, and the oddity is compounded on the next slide when he cites our 2005 paper Transparent Format Migration of Preserved Web Content.
[...]
As stated above, I know how and when Wayback Machines rewrite pages on replay, and Rosenthal knows that I know this. Even if slide 16 was not clear, the accompanying narration and the later context make this clear enough.
I believe that what Nelson intended to say is "The essence of web archive replay is to modify the requested content". But even if oldweb.today were merely a proof of concept, it proves that this statement applies only to the Wayback Machine and similar replay technologies.
To borrow from Monty Python… it’s got some rewriting in it. For example, “raw” HTTP redirects remain problematic and oldweb.today has to be prepared to unrewrite some redirects.
Although the details are outside the scope of this document, the current Wayback Machine “raw” approach is a bit of a white lie and will always be problematic since HTTP is not well-suited for combining historical and current headers (e.g., headers from cnn.com in 2013-05-30 vs. “current” headers from archive.org). A better “raw” method of replay would set the MIME type to “message/http” or “application/http” (or perhaps MHTML, or the evolving web packages and HAR formats) and the delineation between the live and archived responses would be unambiguous. Unfortunately, this would make the response unrenderable in typical user-agents and would thus require a proxy like oldweb.today to effect the rendering.
Furthermore, currently oldweb.today can only function with Wayback Machines since it relies on “raw” replay, which, at least among public web archives, is implemented only with Wayback Machine variants, and is still responsible for modifying the responses it receives from them. oldweb.today is an integrative replay interface, layered on top of multiple Wayback Machines, that performs modifications on the requested content; modifications that, while less intrusive than standard Wayback Machine replay, are modifications nonetheless.
In my view the essential requirement for a site to be classified as a Web archive is that it provide access to the raw Mementos. There are two reasons for this. First, my approach to the problems Nelson describes is to enhance the transparency of Web archives. An archive unable to report the bitstream it received from the target Web site is essentially saying "trust me". It cannot provide the necessary transparency.
Providing access to raw Mementos is desirable, but there are many issues with claiming it as an essential requirement for being a web archive.
This definition would preclude the Internet Archive’s Wayback Machine from being classified as a web archive until December, 2010, when the “beta” Wayback replaced the “classic” Wayback. I believe the Internet Archive’s Wayback Machine did not support access to raw Mementos until late 2010, and if it did support this functionality it was at best an undocumented feature since the November 2010 administrator’s manual does not mention it, but the March 2011 administrator’s manual does. Perhaps one could argue that until late 2010, (proto-)web archives had an unrealized/unimplemented potential to provide raw Mementos, but that seems as tortuous and unsatisfying as a definition that excludes or ignores the first ten years (2001--2010) of the Internet Archive’s Wayback Machine.
Similarly, until May 2018 the Canadian Web Archive used an older version of Open Wayback that did not support access to raw Mementos. A definition that denies their pre-upgrade activities (crawling with Heritrix, storing in WARC files, replaying through Open Wayback) as a web archive is not a useful definition. Furthermore, this definition would exclude other popular, public sites that most would consider web archives, such as archive.is and the partially defunct webcitation.org, both of which transform pages on ingest and store only the transformed version (or at least that is what we infer from their operation, but they’re not open source so we cannot be sure). For example, they dedup embedded images by rewriting them with URIs derived from their content hash, not their original URIs, and discarding the mappings and datestamps. Also, archive.is does not store JavaScript at all, but rather executes it at crawl time and stores only the resulting DOM. This design decision means that archive.is cannot replay the original or “raw” version of the page, but it does have the benefit of easily deduping images and eliminating the myriad of security holes associated with replaying JavaScript.
Rosenthal’s definition would also preclude content management systems, such as MediaWiki, that can serve as their own archive for at least most of their own content (e.g., MediaWiki does not have uniform version control across all of its embedded resources).
Furthermore, this requirement would likely exclude all web archives other than Wayback Machine variants. To the best of my knowledge, there are neither human- nor machine-readable methods for third-party/public exporting of raw Mementos from PageFreezer (example), Megalodon (example, the “ref” version removes the banner but the HTML is still re-written), or Archive.st (example; no banner but the HTML is rewritten). I believe the now defunct Peeep.us, Mummify.it, and PastPages.org lacked the ability to export raw Mementos. While these non-Wayback Machine archives surely comprise only a tiny fraction of all archived web pages, absent community consensus on a definition, it is not for Rosenthal to unilaterally deny them the label “web archives”.
Finally, since general web pages are unlikely to be trivially comparable between different web archives (not having the same of the “6.8*1011 possible versions”), and hashes of archived resources are not routinely stored at independent sites, the web archiving community currently has little transparency at all. Thus, all current web archives are saying “trust me”. As a community, we would prefer that raw Mementos be available, but 1) they’re not always going to be available, 2) they’re not independently verifiable, and 3) in some cases they might not even be defined; to borrow a phrase from Rosenthal: “You get what you get and you don't get upset.”
The second and more important one is that Web archives serve two completely different audiences. The replay UI addresses human readers. But increasingly researchers want to access Web archives programmatically, and for this they need an API providing access to raw Mementos, either individually or by querying the archive's holdings with a search, and receiving the Mementos that satisfy the query in bulk as a WARC file. Suitable APIs were developed in the WASAPI project, a 2015 IMLS-funded project involving the Internet Archive, Stanford Libraries, UNT and Rutgers.
Clearly access to raw Mementos is desirable and facilitates additional applications, but it is not a requirement for programmatic access, nor is a requirement for research purposes. For example, although it does not support access to raw Mementos, archive.is supports programmatic access (submission, discovery, navigation) and has surely been used for research purposes in the last 6+ years. Similarly, the Internet Archive’s Wayback Machine was accessed programmatically and for research purposes from 2001--2010, prior to raw access (and note WASAPI is available only for Archive-It and not the Internet Archive’s Wayback Machine).
I agree with Nelson that the state of Web archive interoperablity leaves much to be desired. But he vastly exaggerates the problem using a highly misleading strawman demonstration. His "generational loss" demo (Slides 88-93) is a game of telephone tag involving pushing the replay UI of one archive into another, then pushing the resulting replay UI into another, and so on.
Transferring content in this way cannot possibly work. One of the major themes of Nelson's entire talk is that the "essence of Web archive [replay] is to modify its holdings". Thus it is hard to see why the fact that successive modifications lose information is relevant to Web archive interoperation.
[...]
The generational loss demonstration illustrates a number of significant issues and deserves careful consideration. Indeed, it is at the very foundation of transparency for web archives.
Perhaps most importantly, the generational loss demonstration reflects how people are actually using web archives today. As Rosenthal notes, the Internet Archive’s Wayback Machine is responsive to, among other things, DMCA takedown requests and robots.txt, though the scope of the latter is no longer as clear as it once was. People regularly make “copies of copies” from one archive to another; archive.is is currently the leader in providing this functionality. For example, it wasn’t just the Library of Congress web archives that assisted in analysis of Joy Reid’s blog, but archive.is’s Mementos of the Internet Archive’s Mementos, uploaded by motivated third parties during one of the interludes where the Internet Archive was not enforcing robots.txt. During the periods when the Internet Archive was enforcing robots.txt, these copies were the only Mementos available. For example, this Memento of her blog was archived by the Internet Archive on 2006-06-15:
But a copy of that copy is available at archive.is:
archive.is did not make that copy on 2006-06-15 (archive.is did not exist until 2013), but the archive.is Memento was created on 2017-12-03. Both dates, 2006-06-15 and 2017-12-03, are communicated in the archive.is banner as well as stating both the Original URI (blog.reidreport.com) and the Memento URI (at web.archive.org).
We can use this functionality to preserve mementos at archives that have now ceased operation. For example, the National Library of Ireland (NLI) hosted their archive at europarchive.org (now spam), and then switched to internetmemory.org (connection times out), and then to Archive-It. Fortunately, we can revisit at least some of the original NLI interface:
at:
Similarly, before Facebook started blocking the Internet Archive with robots.txt, users pushed Mementos from the Internet Archive to archive.is, allowing us to see, for example, the host facebook.com when it was still owned by the directory software company “AboutFace” on 2005-04-08, which was pushed to archive.is on 2013-11-12. After Facebook started blocking the Internet Archive, archive.is was the only place to see this Memento. Now that the Internet Archive no longer enforces robots.txt for facebook.com, we can now view their 2005-04-08 Memento as well.
There are far more examples than those shown above; savvy users understand that even pages in the Internet Archive are at risk and proactively make additional copies elsewhere, even if they are unaware of the nuances of replay UI vs. raw. The point being that as long as web archives have a form that says “input URL to archive”, users are going to purposefully submit Mementos in order to make copies of copies, and whatever URL is in their browser’s address bar is the one they’re going to copy and paste (cf. confusion regarding the different URLs in AMP, DOIs, and Semantic Web URIs). Researchers might have better tools available to them, but researchers are not why “archive.org is the 232-nd most visited site on the Internet” -- public-facing web archives must anticipate that the public will ask them to make copies of copies.
So archive.is can make copies of copies, even through the playback interface, and correctly track the archival metadata. Furthermore, Webrecorder can “extract” resources from other web archives and use them to “patch” a user’s personal archive, although the provenance metadata is not clear in the UI, for example compare this patched version of rhizome.org with the original archived version from arquivo.pt. So while there are promising examples of archives that can interoperate with other web archives, in both cases I believe the archives can handle only one level of redirection; in other words, it’s unlikely that either archive could make a copy of a copy of a copy and retain the provenance information. The question then becomes: why are there only two such examples?
The answer is the woeful state of archive interoperability and the Ptolemaic assumptions web archives make about who is the web archive and who is the live web. After all, if “Web archive interfaces such as the Wayback Machine are Web sites like any other”, what is it about their output that is so impossible for another web archive to ingest and replay? We can’t simply look at the disappointing results and be satisfied with the conclusion that “[t]ransferring content in this way cannot possibly work.” We’ve had the ability to track the provenance of messages moving from system to system since the earliest days of NNTP and SMTP, so why should we expect less for HTTP and web archiving? Indeed, the inability of web archives to correctly ingest the replay output of other web archives can be seen as a violation of Postel’s Law.
There’s also a question of which point of view are we archiving? If I only want to have a 2006-06-15 Memento of reidreport.com in archive.is and perma.cc, then raw access to the Internet Archive’s Wayback Machine is the appropriate modality. But right now, archive.is also archives the fact that the Internet Archive had this Memento on 2017-12-03. That’s not data we want to lose, and if we also want to archive, via perma.cc, that on 2019-07-08 archive.is had a 2017-12-03 Memento of the Internet Archive’s Memento from 2006-06-15, then archiving the HTML from the replay UI is the best way to preserve this provenance. In simple terms, not only do we want to archive what Reid said in 2006, we also want to archive what IA said in 2017 that Reid said in 2006.
For General Flynn’s tweet archived on 2016-12-12, Russian is the language in the Twitter template (i.e., “<html lang="ru"...”). This is almost surely a humorous coincidence and the result of a now-understood crawling side-effect and not a subtle political comment. If the Internet Archive were to improve its playback (or perhaps remove the wry commentary from Winston Smith), other than a screenshot how shall we preserve that it once presaged his fall? Of course the answer is to capture the Internet Archive’s replay in another web archive. The figure below shows the replay of the 2016-12-12 memento from the Internet Archive, complete with the Russian language template, as archived in Perma.cc. In this case, Perma.cc correctly captures IA’s banner and its rewritten version of the Twitter page, but unlike archive.is, Perma.cc does not keep track of the 2016-12-12 Memento-Datetime.

https://perma.cc/CZZ6-R9QH is a memento of https://web.archive.org/web/20161212085355/https://twitter.com/GenFlynn/status/794000841518776320
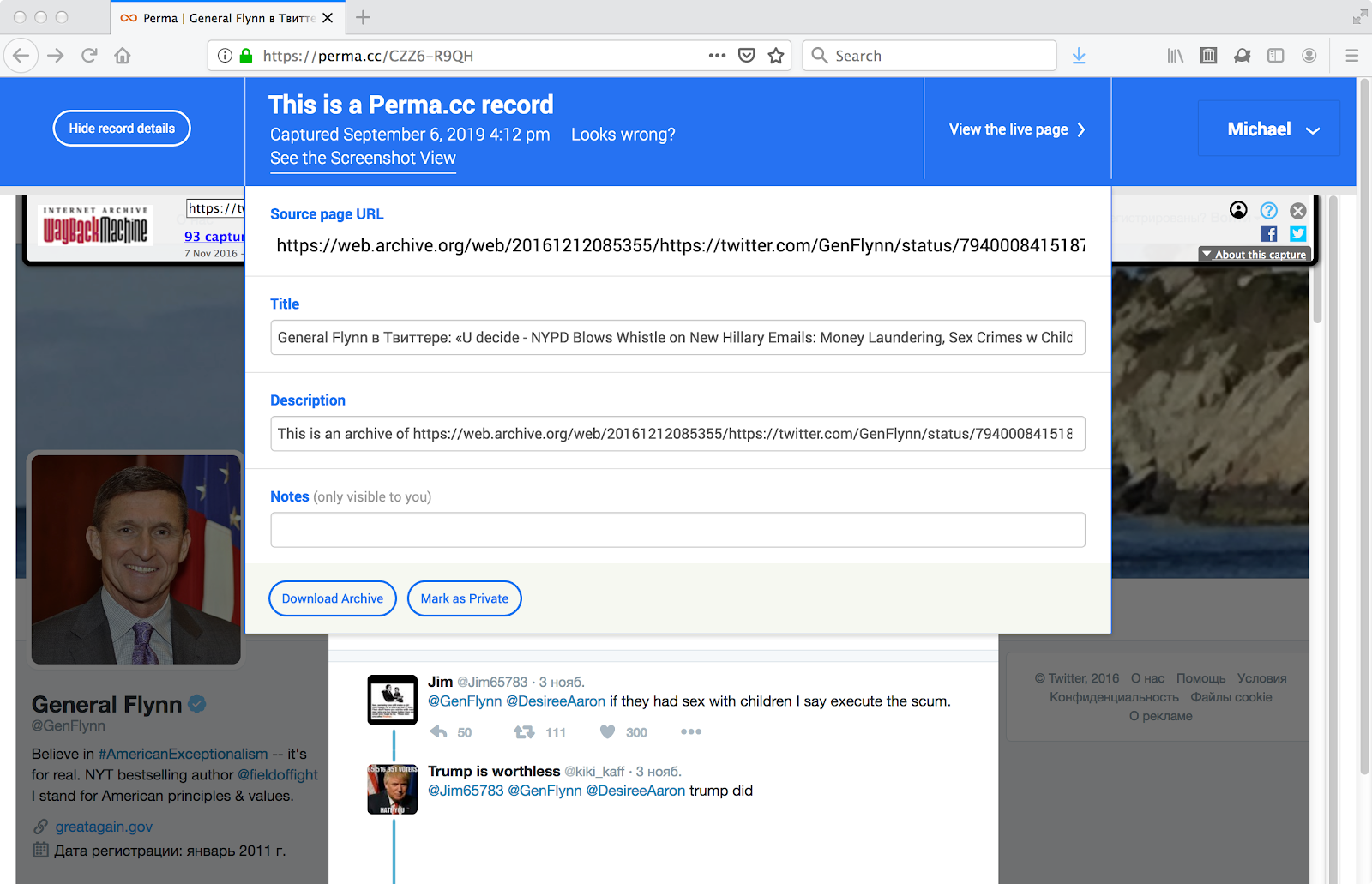
“Show record details” makes it clear that perma.cc does not recognize this is a copy of archive.org’s copy of twitter.com.
Attempting to archive IA’s 2016-12-12 version of the tweet in archive.is now results in a page that eventually times out after trying to load all the embedded resources, at least three of which are loaded from the live web despite IA’s URL rewriting and Content-Security-Policy header:

http://archive.is/Jq1Ec never finishes loading and will produce a 404 when dereferenced. Near the bottom of the image is one of three live web JavaScript files that archive.is loads from abs.twimg.com, despite the Wayback Machine’s URL rewriting and Content-Security-Policy header.
The image below shows archive.is successfully archiving a 2016-11-07 memento on 2016-12-16, and properly maintaining the correct dates and URL values.
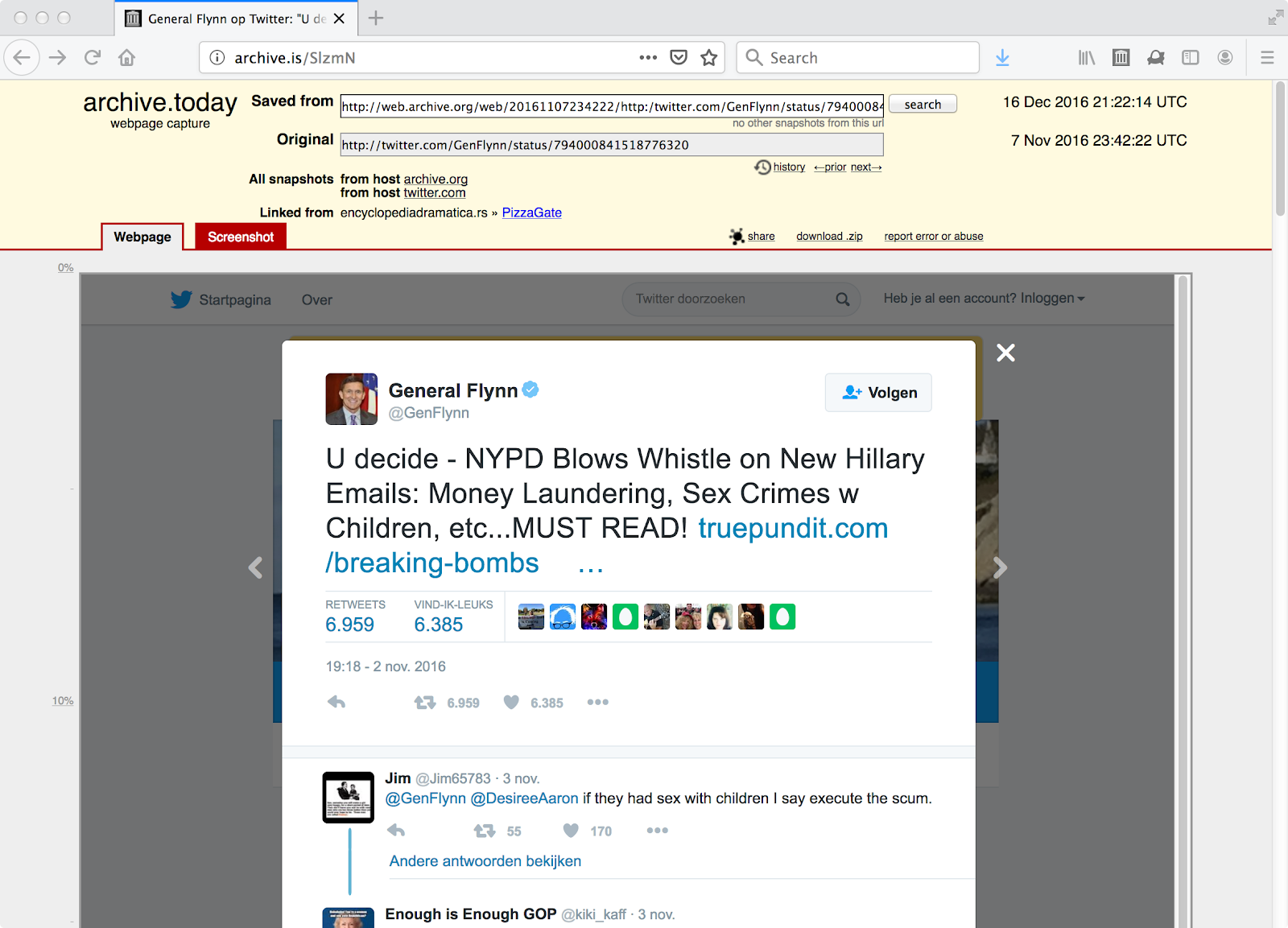
http://archive.is/SlzmN is a memento of http://web.archive.org/web/20161107234222/http:/twitter.com/GenFlynn/status/794000841518776320, but also retains the correct Memento-Datetime (2016-11-07) and URI-R (twitter.com) values. Note that in this 2016-11-07 version the template language is Dutch and not Russian.
Note that archive.is has a copy of General Flynn’s tweet (archived on 2016-11-03) archived directly from Twitter, with the correct English language templates. However, archive.is cleverly combines its direct copies along with copies of copies, and maintains the metadata that distinguishes them. This is how regular users (i.e., not researchers or developers) will use the web archives. Archives must be prepared to ingest rewritten replay from other web archives, and they must recognize mementos from machine readable response headers and not simply maintaining a white list of known web archives and using regular expressions on URLs. Though it is outside the scope of this discussion, we have proposed using custom elements to build more flexible archival banners that could reflect the provenance and metadata associated with multi-archive reconstruction and copies-of-copies.
Web archives, such as those Nelson used in his telephone tag pipeline, that modify their content on replay must interoperate using raw Mementos. That is why for a long time I have been active in promoting ways to do so. [...]
The projects Rosenthal lists are commendable. However, it is important to note that these projects have at their core a number of assumptions about both the content being exchanged and the parties involved. These projects provide no immediate path forward for enabling the kind of general user, anonymous, third-party, “copies-of-copies” scenarios depicted in slides 88-93 or the Flynn tweet example above.
Despite the upside-down tortoise joke, Nelson's references to LOCKSS in this context are also misleading. LOCKSS boxes interoperate among themselves and with other Web archives not on the replayed Web content but on the raw Mementos (see CLOCKSS: Ingest Pipeline and LOCKSS: Polling and Repair Protocol).
The purpose of slide 86 is to inform the listener that LOCKSS is not applicable for this purpose; a point Rosenthal himself makes earlier in Part 2 (“He is correct that the LOCKSS technology is not directly applicable to general Web content…”). Furthermore, slide 86 is the second of two (the other being slide 84) anticipated questions to the statement in slide 78: “That’s never going to happen. (at least not 3rd party through the playback interface).”
Unlike Nelson, I'm not obsessed with Do Androids Dream Of Electric Sheep? and Blade Runner. One thing that puzzled me was the need for the Voight-Kampff machine. It is clearly essential to the story that humans can write to replicant brains, to implant the fake memories. So why isn't this a read/write interface, like the one Mary Lou Jepsen's Openwater is now working on in real life? If the replicant brain could be read, its software could be verified.
Casual readers might see this as an unimportant detail regarding the science fiction that motivated the talk, but it reveals a misunderstanding of a subtle but important point: replicants do not have a read/write interface; their memories are implanted at the time of their physical creation as fully formed adults. Although the book and the film differ slightly in the details, it’s generally accepted that replicants are biologically indistinguishable from humans and would thus respond in the same manner as humans to any imaging technology (“We're not computers Sebastian, we're physical.”); the corollary of which is that the true test for humanity involves measuring empathetic response. Although it is beyond the scope of the CNI keynote, it is worth noting that replicants eventually being able to biologically reproduce is the premise of the sequel, Blade Runner 2049.
This is to say that the utility of Blade Runner metaphor runs deeper than Rosenthal considers. Only 18% of Mementos are both temporally coherent and complete, so under a strict version of an archival Voight-Kampff test 82% of Mementos would not be “authentic” for our cultural, scholarly, or legal interests. In practice, we employ a far more relaxed definition because many of the resources that are missing or temporally violative have limited semantic impact; they are “authentic enough” even though we know them to not be authentic. The character of Roy Batty is a not an “authentic” human, yet exhibits empathy and even humanity (“more human than human”) in his “death” (i.e., shutdown). The archived tweet from General Flynn is not an authentic replay of the page as it existed on 2016-12-12, yet we overlook its flaws and it remains suitable for our political and cultural discourse.
Unlike replicants, Web archives have a read interface, ideally the one specified by Nelson and his co-authors. So the raw collected Mementos can be examined; we don't need a Web Voight-Kampff machine questioning what we see via the replay interface to decide if it correctly describes "the past". As I understand it, examining raw Mementos is part of the Old Dominion group's research methodology for answering this question.
The point of slides 79-83 is to emphasize that even with raw mode, repeated replays of an individual page are likely to be different over time. If things differ, we need to understand why, and that will require methods for discovery, measurement, and evaluation, which if stated poetically could be called a Voight-Kampff test. Indeed, most of Part 3 of Rosenthal’s response, with its four transparency criteria, are the building blocks of an archival Voight-Kampff test.
The broader question of whether the content an archive receives from a Web site is "real" or "fake" isn't the archive's job to resolve (Slide 58). The reason is the same as the reason archives should not remove malware from the content they ingest. Just as malware is an important field of study, so is disinformation. Precautions need to be taken in these studies, but depriving them of the data they need is not the answer.
Just for clarity: reading only this paragraph from Part 2, a reader might infer that slide 58 supports archival detection and removal of deepfakes. It does not support that, as Rosenthal acknowledges in Part 1 (“In Slide 58 Nelson emphasizes that it isn't the archive's job to detect or suppress fake content from the live Web.”).
“I'm Deckard. Blade Runner. Two sixty-three fifty-four. I'm filed and monitored.”
As I've repeatedly pointed out, the resources available for Web archiving are completely inadequate to the task. Jefferson Bailey shows that this is especially true of Web archiving programs in University libraries. Nelson's research program depends upon Web archiving programs for its material. His audience was composed of the foundations that fund Web archiving research, and the University librarians who should (but generally don't) fund Web archiving programs.
Thus for him to present such an unremittingly negative view of (a part of) the field was to say the least politically inept.
...but I am surprised by his conclusion. Enumerating threats and speaking truth to power seemed the most Rosenthal-like thing I could do. I assumed no one at CNI needs reassurance that “the live Web and the Wayback Machine [...] are reasonably reliable for everyday use”, and hopefully Lynch’s introduction established my web archiving bona fides to the audience. Instead, I assessed that foundations and libraries would prefer to be alerted that the infrastructure they value is vulnerable to free riders, decreasing diversity, targeted hacking, and an expanding theatre of conflict for disinformation.
What does Nelson propose we do to address the risks of Web archives being used as a vector for disinformation? He isn't very specific, saying: [...]
There’s additional explanatory material in the video that Rosenthal has not included. At 56:45, in response to the question "what is the thing you're trying to archive?":
“I think we need to reexamine what does it mean to have an archived version. So the Heritrix/Wayback Machine gives us the HTML, it gives us the JavaScript, it renders client-side, everything's copy-n-pastable, and that makes a lot of sense most of the time.
“The archive.is web archive has actually a slightly different model; it gives you HTML, but server-side, at crawl-time, it flattens out all the JavaScript, so it removes all the interactivity. Which is both good and bad. The good part is that it freezes that page in time and it doesn't screw up any more. We could also do screen shots, we kind of have that, and then I think adding the game walkthrough, the video component, the robotic witnesses, and sort of filming/recording people "playing the game". So Google Maps -- what does it mean to archive Google Maps? We're not going to archive all of it, but maybe we can archive a walkthrough through Google Maps. And that maybe helps us establish later the page that I'm getting back, maybe with or without JavaScript, it establishes a baseline of what we can expect from that page. Now, the flipside is the footprint to "archive a page" just ballooned. But on the other hand, once we get to real-world implications for incorrectly playing back a page, like governments making decisions, militaries making decisions, political outcomes, maybe that's a level of investment that we have to have. But I admit I don't have all the answers on that,
other than to say "read Cliff's paper" -- it has a lot of good ideas.”
And at 59:34, in response to the question about "getting more archives, more archiving activity?":
“What I would like to see is more interoperability from independent archives. So, there's pywb, there's OpenWayback -- that's a good start. I'm concerned that some universities are closing down their archiving efforts. I understand that -- it's easier to just pay a subscription to Archive-It. I would like to see multiple, independent web archiving efforts, with variation in the technology stack. So I mentioned archive.is/archive.today, webcitation.org is sort of interesting
-- archiving solutions that come from different communities have different presuppositions. Some things they get "wrong", some things they get surprisingly right. I think setting up more Wayback Machines is a good start, but we need to investigate something beyond just Heritrix and Wayback Machines. I know we're moving towards headless browsing and so forth, but the Wayback playback paradigm is still constricting our way of thinking. Part of this is what does it mean for images, what does it mean for video, and how do we interoperate and say "I observed this, you observed that, let's measure the difference between them"? Also, having the semantics to express "some of my content I observed independently, some of it I got from a seed from the Internet Archive because I didn't exist in 2005 so I just got a bunch of their stuff and loaded it up and played it."
“So I'd like to see more of a move towards standards and a focus on interoperability and I welcome more people participating even though it comes at the security and authenticity risk associated... I also admit that's completely self-serving because I do web archiving research, so obviously the answer is "we need to have a lot more web archives!" -- so I get that, but on the other hand, I think it's important that we move in that direction.”
As I understand this, he is proposing we somehow build a stack more credible than the Wayback Machine.
This is a strawman; I did not propose a “more credible” stack, I proposed more independent archives that interoperate through protocols and standards.
Given some specifics about this stack would actually do, implementing it would not take huge resources. Kreymer has shown the feasibility of implementing an alternate stack.
My issue with this idea is that it simply isn't a practical solution to the problem of disinformation campaigns using Web archives. The only reason they can do so is that the Wayback Machine's two-decade history and its vast scale have led people to overestimate its credibility. [...] The only way I can see to displace the Wayback Machine's dominant mindshare involves: [...] It would be possible for a government to do this, but very hard to do in a deniable way. For anyone else to attempt it would be a profoundly destructive waste of time and resources, which would likely fail.
Fortunately Kreymer and his colleagues did not heed the advice “[e]ach dollar spent supporting another archive is a dollar that would preserve more content if spent at the Internet Archive”, and the web archiving community is richer as a result.
Webrecorder gave us a completely different model for crawling than Heritrix (and even slightly different from Brozzler). The pywb replay software hews close to the modalities of the Internet Archive’s Wayback Machine and Open Wayback, but it is a ground-up rewrite with new features and many of the security improvements listed in the Cushman & Kreymer presentation. Together, webrecorder and pywb form the foundation of an entirely new archive, Harvard’s perma.cc.
oldweb.today pushes the state of the art further, combining web archive aggregation with emulating the browsers of yesterday. Released after Rosenthal’s blog posts, Kreymer’s prototype Web Archive Browsing Advanced Client (wab.ac) removes the need for a server-based replay system altogether, even while introducing new interactions between server-side and client-side replay. wab.ac is also innovating by accepting HAR files as input and not just WARC files.
To briefly mention some of the projects not already mentioned here, my colleagues and I have investigated combining web archiving approaches with content-addressable distributed filesystems, web packaging, different models for client-side rewriting (ServiceWorkers, Web IDL), collaborative archival banners, transactional web archives, and crowdsourced template-based archiving.
Innovations have come from other, non-Wayback Machine web archives as well. WebCite was the first to offer on-demand archiving of individual pages (ca. 2003). archive.is offered on-demand archiving of individual pages in late 2012, nearly a year before the Internet Archive offered the same functionality. Because archive.is archives pages using a headless browser (I believe it was the first to exclusively do so), its ability to incorporate screenshots of archived pages is probably at least contemporaneous with the Internet Archive (i.e., late 2012 or early 2013). Both WebCite and archive.is were innovative in addressing the deduplication problem by rewriting the URLs for embedded resources (e.g., images) based on a hash of the contents and not the original URL itself, predating the solution from within the WARC-based community. In 2007, Zoetrope prototyped powerful UI features to support version comparison and exploration, features not unlike what the Internet Archive has recently started providing.
As is the case with prototypes and demos, the projects listed above have had varying levels of success, adoption, and longevity. And while only some are (as of yet) common place in the web archiving community, presumably Rosenthal does not think of them as being an attempt to “displace the Wayback Machine's dominant mindshare” or a “profoundly destructive waste of time and resources.” It is not consistent for Rosenthal to praise the innovations of Rhizome et al. but then criticize my call for “more interoperability from independent archives” and “new models for web archiving and verifying authenticity”.
When I say the “Heritrix / Wayback Machine technology stack, while successful, has limited our thinking”, Rosenthal responds with a strawman involving replacing and even attacking the Internet Archive’s Wayback Machine. Yet Rosenthal goes on to echo a viewpoint similar to mine with statements like “The Wayback Machine and similar UIs mislead the user…”, “The Wayback Machine and similar replay technologies mislead the user in another way”, and “The indexing and UI for these screenshots needs more work...”. His transparency recommendations include capabilities that Wayback Machines are unlikely to provide in the immediate future (“Source Transparency”), capabilities first explored by our research group in 2012 (“Temporal Transparency”), a prototype of replay in emulated browsers and aggregated archives that represents a radical break from the Wayback Machine UI (“Fidelity Transparency 1”), and capabilities that after almost seven years still remain separate and apart from the default Wayback Machine UI (“Fidelity Transparency 2”). I am not opposed to these transparency recommendations; our research group is, in varying degrees, active in all of them. However, I do not consider them the source of an engaging CNI keynote.
Rosenthal is correct in that my suggestions for moving forward are not very specific; since this is a keynote and not a funding proposal nor a formal publication, I chose not to indulgence in details and mechanics (though links for further reading are provided). Still, Rosenthal gives only cursory consideration to what I did propose, the most important of which is to leverage the engagement economy for auditing archives. For example, thanks to captchas, the quality of OCR has improved and map applications rarely send you to the wrong street address. Given the R&D that goes into generating and solving captchas, inflating engagement (slide 98), and creating bots that perform for each other in spaces created exclusively for humans -- surely some of this effort can be applied to auditing archives. Robots already outnumber humans in web archives, but as of yet we have not learned how to harness their activities to our benefit.
Addressing the problem of excess credibility of the Wayback Machine by competing with it just isn't a sensible approach.
I’m unaware of anyone who has ever suggested “competing” with the Internet Archive’s Wayback Machine.
What is needed is some way to adjust perceptions of the Wayback Machine, and other Web archives, closer to reality. Since we cannot have perfection in collection, preservation and replay, what we need is increased transparency, so that the limitations of our necessarily imperfect Web archives are immediately evident to users. Off the top of my head, I can think of a number of existing technologies whose wider adoption would serve this end.
The list that Rosenthal provides after this paragraph are all good ideas, and readers should not infer that I am in opposition to them. As Rosenthal himself notes in several places, my research group has been active in many of these areas, some of which are linked to from the keynotes slides. I’ll restrict my comments here to points of clarity and correction.
Temporal Transparency
Nelson is correct to point out that replayed Web pages frequently lack temporal integrity. [...]
Yes, we need more temporal transparency, and its consideration from IA and oldweb.today are welcome. However, the issue is far more nuanced than Rosenthal describes and his optimism regarding its current utility is misplaced. As implemented now, it is at best of limited help because it is not machine readable (in the sense that it’s not reusable and is tightly coupled to this particular replay) and it is difficult for humans to make sense of the output as the number of embedded resources grows. At worst, the legitimate temporal spread of archived resources can be used to hide the malicious temporal violations. Some of the issues are at the core of how the Heritrix/Wayback Machine stack operates, and it is not clear how to address the situations where they give the wrong answer without trading away their desirable properties where they frequently give the right answer.
Putting aside the unresolved UI issues for how to meaningfully communicate temporal spread for the potentially hundreds (median = 74) of embedded resources that occur in modern pages, it is important to note that temporal spread is inevitable in the live web: images, stylesheets, JavaScript -- in fact most non-HTML formats -- are typically static files and frequently shared between multiple web pages (such as navigation banners and support libraries). The live web spread will be reflected in archives as well, and a large temporal spread does not necessarily mean there is a temporal violation. The interplay between the Memento-Datetime (i.e., the crawl date) and the resource’s Last-Modified HTTP headers needs to be considered, as well as accounting for cases where Last-Modified has been falsified. For example, Twitter correctly maintains Last-Modified on images, but not on the HTML that embeds them. Contrast these four responses, the first for an image and the next three for the tweet in which the image is embedded:
$ curl -Is "https://pbs.twimg.com/media/B4WGRmrIAAAt6mT?format=png&name=900x900" | grep -i "last-modified"
Last-Modified: Mon, 08 Dec 2014 16:03:37 GMT
$ curl -Is https://twitter.com/phonedude_mln/status/541986967932895232 | grep -i "last-modified"
last-modified: Mon, 29 Jul 2019 17:14:32 GMT
$ curl -Is https://twitter.com/phonedude_mln/status/541986967932895232 | grep -i "last-modified"
last-modified: Mon, 29 Jul 2019 17:14:34 GMT
$ curl -Is https://twitter.com/phonedude_mln/status/541986967932895232 | grep -i "last-modified"
last-modified: Mon, 29 Jul 2019 17:14:36 GMT
In this case, Twitter’s concern is about preventing caching of the HTML and not disinformation, but at scale this will be hard to distinguish. There has been some research in site-level archival quality (e.g., Denev et al., 2009; Ben Saad & Gançarski, 2012), but I am unaware if these algorithms have been adopted by web archives, or if they have been adapted for servers that purposefully send incorrect information, as Twitter does.
The issue of temporal transparency is then one of two questions:
Did this replayed page ever exist on the live web?
If the answer is yes, then we can rest easy knowing we have captured one of the “6.8*1011 possible versions” observed by at least one user agent at some point in the past. For tools such as webrecorder.io, this will be easy to answer: the WARC file contents are created from a single user agent session. Similarly with page-at-a-time services, such as archive.is, perma.cc, and the Internet Archive’s “Save Page Now”. For long-running, site-level crawls (e.g., the bulk of the Internet Archive’s Wayback Machine), this question is harder to answer, and thus we turn to a slightly weaker version of the question:
Could this replayed page have ever existed on the live web?
In other words, even if we cannot prove this archived page was observed by a user agent within the spread of the Memento-Datetime of the embedding HTML to the embedded resource with the latest Memento-Datetime, can we at least prove that this page does not lie outside of the “6.8*1011 possible versions”? In at least 5% of the cases we sampled (ca. 2014), we found provable temporal violations: the replayed page was, in fact, not one of the “6.8*1011 possible versions”. Note: at the time of that study, we had not considered attacks on the archive; we assumed both the pages and the archives are telling the truth.
Fidelity Transparency 1
The Wayback Machine and similar replay technologies mislead the user in another way. There's no indication that the 2016 browser uses different fonts and background colors from those an original visitor would have seen.
Kreymer has shown how to replay pages using a nearly contemporaneous browser, in a way that could be transparent to the user and does not involve modifying the replayed content in any way. The difficulty is that doing so is expensive for the archive, an important consideration when it is serving around four million unique IPs each day on a very limited budget, as the Internet Archive does.
Nevertheless, it would be possible for the UI of replay technologies like the Wayback Machine, after displaying their rendering of the preserved page, to offer the option of seeing an oldweb.today style rendering. Since users would be unlikely to choose the option, the cost would probably be manageable.
oldweb.today is an exciting proof-of-concept of an alternative way to replay web pages, and if the Internet Archive would offer something similar as an option, it would be welcome. However, there are a number of reasons why I suspect that will not happen.
First, as Rosenthal acknowledges, the current method of booting a new Docker container for every session to emulate an operating system and a browser (which then uses a proxy to mediate access to multiple web archives) is a heavy-weight approach that is unlikely to scale.
Second, it assumes, or at least encourages, a session-centric view of interacting with the archived web that is not supported by our research. Our research (TPDL 2013, JCDL 2013a, JCDL2013b) indicates users do not come to “browse like it’s 1999”, but rather access individual missing pages (e.g., links from Wikipedia). It is possible that tools like oldweb.today will spur more interest in archival browsing sessions, but for current access patterns the session start-up costs will not be amortized over a long-running session.
Third, if this were to be broadly adopted, we would have to seriously consider the security implications introduced by various generations of browsers: browsers that still support kiosk mode would be vulnerable to UI hacking, as are browsers that allow pop-ups with the address bar hidden and/or spoofed. Browsers that do not support CORS or CSP would be vulnerable to targeted attacks across orchestrated pages, not to mention the innumerable version- and library-specific security holes closed by later releases. The version-specific flaws and limited security profiles of older browsers may not be exploitable in the original sense, but there is no reason to think these flaws will not uncover unforeseen attack vectors for disinformation campaigns of today’s pages rendered through yesterday’s browsers, even when emulated in today’s browsers.
Fidelity Transparency 2
A second way to provide transparency for replay technologies is for the archive to create and preserve a screenshot of the rendered page at ingest time along with the bitstreams that it received. [...]
Capturing screenshots like this, especially complete page screenshots, is the obvious way to expose most of the confusion caused by executing Javascript during replay of Mementos. Unfortunately, it significantly increases both the compute cost of ingest, and the storage cost of preservation.
I agree that screenshots, although expensive, are a likely path forward for assessing the validity of archived pages. This is in line with slide 96: “The Heritrix / Wayback Machine technology stack, while successful, has limited our thinking”; screenshots are not generated by Heritrix, nor are they currently integrated in any Wayback Machine. This is not because the web archiving community does not know how to generate them -- as Rosenthal demonstrates, archives have been generating them for seven years. This is because we have assumed, via Heritrix / Wayback hegemony, that the replayed MIME type should be the same (or similar) as the ingested MIME type. Converting “image/gif” to “image/png” is straight-forward and largely unobserved by regular users, but converting HTML/CSS/JS to “image/png” or “video/mp4” is not. This tension is evident in the Internet Archive’s URL for the screenshot of Rosenthal’s blog:
Which also nicely illustrates the importance of standards-based interoperability, since the HTTP response contains the correct value to indicate what this URL is a copy of:
$ curl -I https://web.archive.org/web/20130202005324/http://web.archive.org/screenshot/http://blog.dshr.org/
HTTP/1.1 200 OK
Server: nginx/1.15.8
Date: Tue, 30 Jul 2019 16:42:35 GMT
Content-Type: image/png
Connection: keep-alive
Cache-Control: max-age=1800
X-Archive-Guessed-Content-Type: image/png
Memento-Datetime: Sat, 02 Feb 2013 00:53:24 GMT
Link: <http://blog.dshr.org/> rel="original", [...]
Whereas the applications that eschew standards-based interoperability and violate URI opacity would likely extract an incorrect value of the original URI as:
http://web.archive.org/screenshot/http://blog.dshr.org/
To further illustrate this point, PastPages, the proof-of-concept web archive that created hourly screenshots of the homepages of prominent newspapers, ceased operation in 2018. Its holdings were then transferred to the Internet Archive, but as a collection and not part of IA’s Wayback Machine, presumably because there is currently no good way to integrate the screenshot of a web page alongside its HTML replay.
“Fiery the angels fell. Deep thunder rode around their shores, burning with the fires of Orc.”
I'm not saying that the problems Nelson illustrates aren't significant, and worthy of attention. But the way they are presented seems misleading and somewhat counter-productive. Nelson sees it as a vulnerability that people believe the Wayback Machine is a reliable source for the Web's history. He is right that malign actors can exploit this vulnerability. But people believe what they see on the live Web, and malign actors exploit this too. The reason is that most people's experience of both the live Web and the Wayback Machine is that they are reasonably reliable for everyday use.
The title of Cushman and Kreymer’s 2017 presentation begins with “Thinking like a hacker: ...”, and therein probably lies at least a portion of the disconnect between my keynote and Rosenthal’s posts. Roenthal is simultaneously fatalistic (“Nothing that you see on the Web can be taken at face value”, “...excess credibility of the Wayback Machine…”) and surprisingly optimistic about the effectiveness of current security measures (“Using an alternate replay technology [...] it would be an embarrassing failure”, “At least some of the attacks identified two years ago have already been addressed...”, “...this is tricky to do undetectably”).
The subtle distinction of the web archive being the object of the attack vs. the web archive being the vector of the attack would explain at least some of the discrepancy between our positions. Although the Internet Archive has weathered more than their share of DDoS attacks and censorship (not to mention force majeure), web archives are becoming more and more like open SMTP relays or open HTTP proxies in that they will be used as launch points for attacks and not simply something to be knocked off-line. Rosenthal has built a distinguished career of conceiving of and protecting against digital preservation threats, but anyone who reads Cushman & Kreymer, Lerner et al., and Berlin, and then is not alarmed by the current state of web archives as an attack vector is not thinking like a hacker. If one sees the “University of Farmington” example in slide 69 (and by extension, the web archiving possibilities it represents) as an attack by the government on EDUCAUSE & DNS instead of an attack by the government using EDUCAUSE & DNS, they are not thinking like a hacker. If one reads Rosenthal’s “Temporal Transparency” section and sees a solution instead of method for a hacker to cover their tracks, they are not thinking like a hacker. If you view my keynote and think “...malign actors exploit [the live Web] too”, you’re not thinking like a hacker.
Rosenthal has regularly sounded the alarm on a variety of threats, from esoteric and theoretical to current or imminent, on topics such as certificates and certificate authorities, software authenticity, hardware implants and compromised firmware, governments and corporations generating fake content and fake metadata about the content, co-opting browsers for mining, surveillance, and malware distribution, and the impending collapse of bitcoin; all positions with which I wholeheartedly agree. Yet, when the topic turns to the unique role web archives can play in disinformation, there is a dramatic retreat to a position of “Web archive interfaces such as the Wayback Machine are Web sites like any other” and “...both the live Web and the Wayback Machine [...] are reasonably reliable for everyday use.”
We can’t have it both ways: the only way slide 46 stays incomplete is if web archiving is not important enough to attract attention. If web archiving is important -- culturally, scholarly, legally, historically -- not only will it be attacked (e.g., DDoS, censoring), it will be used against us (e.g., disinformation). For years my research group and our many colleagues have devoted our energies to forestalling the completion of slide 46, but on April 9, 2019 I used the platform CNI gave me to “recount all the detailed problems” and sound the alarm. Was it “misleading and somewhat counter-productive”? I don’t think so. Was it “unremittingly negative”? Perhaps, but in one version of the future it rains all the time in Los Angeles.
Acknowledgements
This work has greatly benefited from the feedback of Sawood Alam, Danette Allen, Shawn Jones, Martin Klein, Herbert Van de Sompel, and Michele Weigle. I am grateful for their contributions, but I am responsible for any errors that may be present.
Comments
Post a Comment