2025-07-16: Understanding Hallucination in Large Language Models: Challenges and Opportunities
 |
| Fig 1 from Rawte et al. Taxonomy for Hallucination in Large Foundation Model |
The rise of large language models (LLMs) has brought about accelerated advances in natural language processing (NLP), enabling powerful results in text generation, comprehension, and reasoning. However, alongside these advancements comes a persistent and critical issue: hallucination. Defined as the generation of content that deviates from factual accuracy or the provided input, hallucination presents a multifaceted challenge with implications across various domains, from journalism to healthcare. This blog post presents insights from three recent comprehensive surveys on hallucination in natural language generation (NLG) and foundation models to provide an understanding of the problem, its causes, and ongoing mitigation efforts. “Survey of Hallucination in Natural Language Generation” by Ji et al. (2022) provides a foundational exploration of hallucination in various NLG tasks, including abstractive summarization, dialogue generation, and machine translation. It defines key terminologies, identifies contributors to hallucination, and outlines metrics and mitigation strategies, making it an essential reference for understanding the broad implications of hallucination across NLP applications. “A Survey of Hallucination in "Large" Foundation Models” by Rawte et al. (2023) extends the discussion of hallucination into the realm of large foundation models (LFMs), such as GPT-3 and Stable Diffusion. This paper categorizes hallucination phenomena across modalities (text, image, video, audio), evaluates current detection and mitigation efforts, and highlights the challenges posed by the inherent complexity and scale of LFMs. Finally, in “A Survey on Hallucination in Large Language Models”, Huang et al. (2024) offer an in-depth examination of hallucination specific to LLMs, introducing a nuanced taxonomy that includes factuality and faithfulness hallucinations. This work delves into the causes of hallucination during data preparation, training, and inference while also addressing retrieval-augmented generation (RAG) and future directions for research.
Hallucination in Language Models
WSDL member Hussam Hallak recently wrote a three part blog post about LLM hallucinations in the Quran which does an excellent job at illustrating ways that LLM’s can introduce problematic, erroneous information into its responses. Part 1 shows how Google Gemini hallucinates information. Part 2 compares Google Gemini’s hallucinations with ChatGPT’s. Finally, part 3 then reviews DeepSeek and how it performs on the same prompts.
Hallucination in LLMs can be categorized into two primary types:
Intrinsic Hallucination: This occurs when the generated content contradicts the source input. For instance, in machine translation, a model might produce translations that directly conflict with the original text.
Extrinsic Hallucination: This involves the generation of unverifiable or fabricated content not grounded in the input. While such outputs might sometimes provide helpful additional context, they frequently introduce inaccuracies, posing risks in applications demanding high factual fidelity.
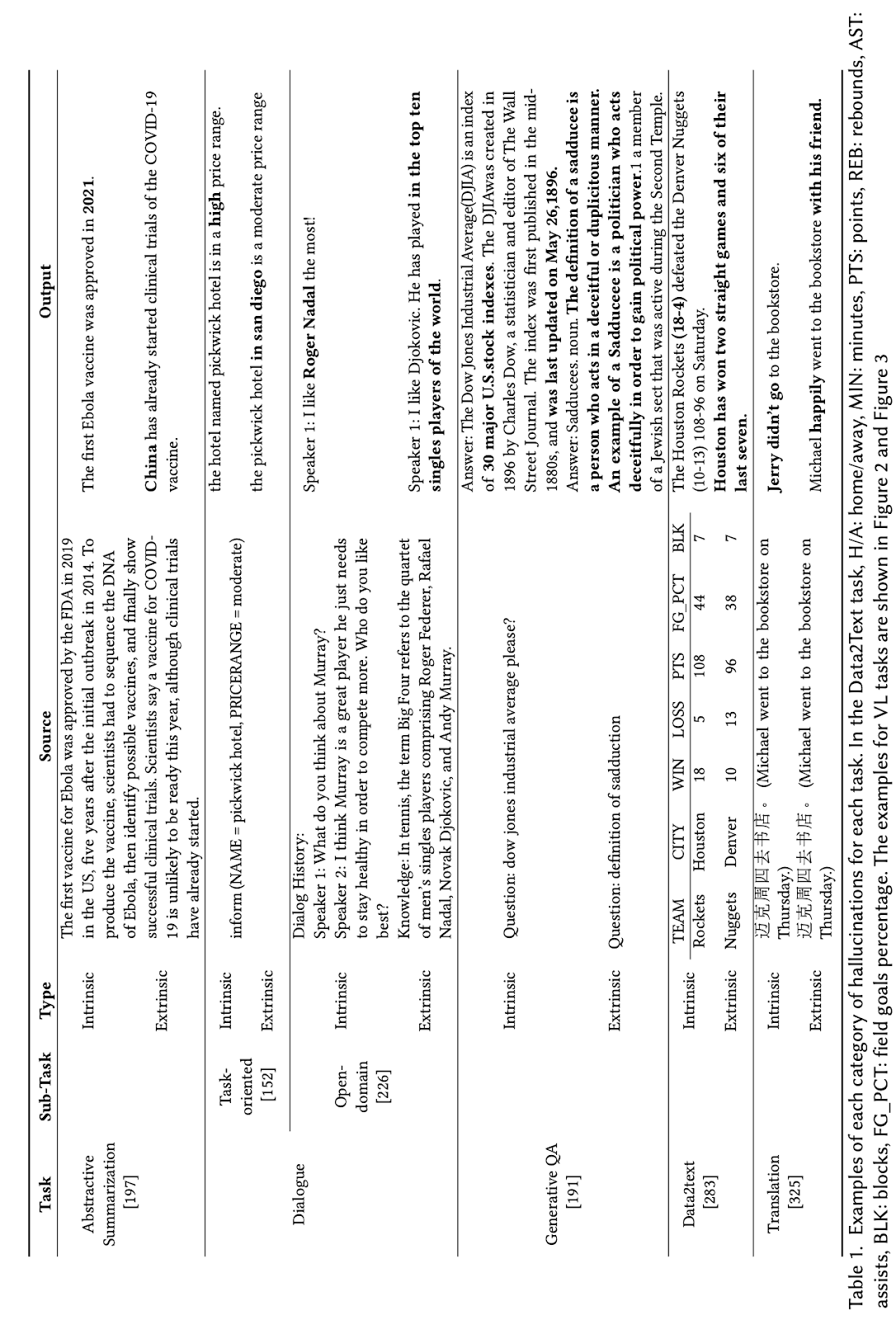
Table 1. from Ji et al., showing various hallucinations in text respective to data

Fig 2. Ji et al., Examples of hallucination in image generation
Figure 2 from Ji et al.'s survey provides both intrinsic and extrinsic examples of object hallucination in image captioning, showcasing the challenges in multimodal tasks. For instance, when describing an image, a model might generate captions referencing objects that are not present in the visual content. This serves as a concrete illustration of how hallucination manifests beyond textual outputs, underscoring the need for robust grounding techniques in multimodal systems.
Recent research extends these definitions to include distinctions between factuality hallucinations (deviation from real-world facts) and faithfulness hallucinations (deviation from user instructions or input context).
Causes of Hallucination
Hallucination arises from multiple interconnected factors throughout the lifecycle of LLMs, encompassing data, training, and inference processes.
Data-Related Causes:
Source-Reference Divergence: According to Ji et al., tasks like abstractive summarization, the reference text might include information absent from the source, leading models to generate outputs based on incomplete grounding.
Misinformation and Bias: Both Rawte et al. and Huang et al. explain that training datasets often contain erroneous or biased information, which models inadvertently learn and reproduce.
Training-Related Causes:
Pretraining Limitations: During pretraining, models optimize for next-token prediction, potentially leading to overgeneralization or memorization of inaccuracies.
Fine-Tuning Misalignment: Misaligned training objectives during supervised fine-tuning (SFT) or reinforcement learning from human feedback (RLHF) can exacerbate hallucination tendencies.
Inference-Related Causes:
Imperfect Decoding Strategies: Techniques such as beam search may prioritize fluency over factuality, amplifying hallucination.
Overconfidence: Models often assign high probabilities to fabricated outputs, further complicating detection and mitigation.
Metrics for Evaluating Hallucination
Evaluating hallucination requires a nuanced approach:
Statistical Metrics: These include precision and recall for factuality and alignment.
Model-Based Metrics: Leveraging pretrained models to assess the veracity of generated content.
Human Evaluation: Employing expert annotators to identify and classify hallucinatory outputs, though this is resource-intensive.
Recent efforts also emphasize the development of task-specific benchmarks, such as TruthfulQA and HaluEval, which test models against curated datasets designed to probe their factual consistency and faithfulness. These benchmarks are instrumental in driving standardized comparisons across models.
Mitigation Strategies
Efforts to mitigate hallucination span data curation, training modifications, and inference adjustments:
Data-Centric Approaches:
Data Filtering: Removing noisy or biased samples from training datasets.
Augmentation with External Knowledge: Incorporating structured knowledge bases or retrieval-augmented generation (RAG) to ground outputs in verifiable facts.
One notable example of augmentation is the use of retrieval mechanisms that fetch relevant external documents during inference, providing models with updated and accurate information to support generation.
Training Enhancements:
Faithfulness Objectives: Adjusting training loss functions to prioritize adherence to source content.
Contrastive Learning: Encouraging models to distinguish between grounded and ungrounded content.
Knowledge Injection: Embedding domain-specific or real-time data updates into the model during training to reduce reliance on potentially outdated pretraining data.
Inference Techniques:
Iterative Prompting: Refining outputs through step-by-step guidance.
Factuality-Enhanced Decoding: Modifying decoding algorithms to prioritize accuracy over fluency.
Self-Verification Mechanisms: Employing models to cross-check their outputs against trusted sources or re-evaluate their answers iteratively.
Applications and Implications
The implications of hallucination extend far beyond theoretical concerns with real world consequences. One such case happened with Air Canada’s customer support chatbot hallucinated a policy that doesn't exist. When a passenger asked Air Canada’s website chatbot about bereavement fares, the bot invented a rule saying he could buy the ticket at full price and claim the discount retroactively within 90 days. After the trip, the airline refused the refund only to have Canada’s Civil Resolution Tribunal order it to pay C$650 (plus interest and fees) and reject Air Canada’s claim that the chatbot was “a separate legal entity.” One stray hallucination turned into real legal and financial liability, illustrating why faithful generation matters. Another case happened during Mata v. Avianca, Inc., a personal injury suit tried in the U.S. District Court for the Southern District of New York. Two attorneys used ChatGPT to draft part of a motion and it hallucinated six precedent cases that never existed. U.S. District Judge P. Kevin Castel spotted the fabrications, dismissed the citations as “gibberish,” and fined the attorneys and their firm Levidow, Levidow & Oberman C$5,000 for “conscious avoidance and false statements.” The sanction shows how un-vetted AI hallucinations can turn into real ethical and financial consequences.
These real world examples illustrate how in domains like healthcare, hallucination can lead to life-threatening misinterpretations of medical advice. In journalism, it risks eroding public trust by disseminating misinformation. Similarly, legal contexts demand utmost accuracy, where any hallucinatory output could have grave consequences.

Fig 3 Ji et al. Examples of hallucination in visual question answering. The bold text is the output generated by the model and the part before it is the input prompt
Figure 3 further elaborates on this by depicting scenarios where hallucinated captions create misleading narratives about visual data. These examples highlight the significant risks in real-world applications like autonomous systems or assistive technologies, emphasizing the urgency for improved evaluation and mitigation strategies.

Fig 5 from Rawte et al. A video featuring three captions generated by various captioning models, with factual errors highlighted in red italics
Figure 5 from “A Survey of Hallucination in “Large” Foundation Models” adds another layer to this discussion by presenting video captioning outputs with factual errors highlighted in red italics. These examples reveal the complexities of grounding outputs in video data, where temporal and contextual nuances often exacerbate hallucination issues. They underscore the necessity for domain-specific training and evaluation techniques in applications like autonomous systems or assistive technologies.
However, hallucination is not universally detrimental. In creative applications like storytelling or art generation, "controlled hallucination" may enhance innovation by producing imaginative and novel content, like protein discovery. Balancing these use cases with robust mitigation strategies is critical.
Research Frontiers and Open Questions
Despite notable progress, significant gaps remain:
Dynamic Evaluation: Developing adaptive evaluation frameworks that account for diverse tasks and domains.
Contextual Understanding: Enhancing models’ ability to reconcile disparate contexts and avoid contradictory outputs.
Knowledge Boundaries: Establishing clear delineations of models’ knowledge limitations to improve trustworthiness.
Explainability and Transparency: Understanding why hallucinations occur and providing users with insights into the reasoning behind model outputs.
Cross-Modal Hallucination: Exploring hallucination across modalities, such as text-image generation systems, to develop unified mitigation strategies.
Conclusions
Addressing hallucination in LLMs is paramount as these models become integral to decision-making systems in high-stakes domains. By tackling the root causes through better data practices, refined training paradigms, and innovative inference strategies, the NLP community can enhance the reliability and trustworthiness of LLMs. Collaborative, interdisciplinary efforts will be essential to navigate the complexities of hallucination and unlock the full potential of generative AI.
Moreover, as LLMs continue to evolve, fostering ethical and responsible AI practices will be crucial. Researchers and developers must work together to ensure that these powerful tools serve as reliable partners in human endeavors, minimizing risks while amplifying benefits for society at large.
Jim
Works Cited
Ji, Ziwei; Lee, Nayeon; Frieske, Rita; Yu, Tiezheng; Su, Dan; Xu, Yan; Ishii, Etsuko; Bang, Yejin; Chen, Delong; Dai, Wenliang; Shu Chan, Ho; Madotto, Andrea; Fung, Pascale. "Survey of Hallucination in Natural Language Generation." ACM Computing Surveys, vol. 1, no. 1, Feb. 2022. DOI: https://doi.org/10.48550/arXiv.2202.03629.
Rawte, Vipula; Sheth, Amit; Das, Amitava. "A Survey of Hallucination in 'Large' Foundation Models." arXiv preprint, Sept. 2023. DOI: https://doi.org/10.48550/arXiv.2309.05922.
Huang, Lei; Yu, Weijiang; Ma, Weitao; Zhong, Weihong; Feng, Zhangyin; Wang, Haotian; Chen, Qianglong; Peng, Weihua; Feng, Xiaocheng; Qin, Bing; Liu, Ting. "A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions." ACM Transactions on Information Systems, Jan. 2024. DOI: https://doi.org/10.48550/arXiv.2311.05232.
Comments
Post a Comment