2025-06-27: Paper Summary: MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery
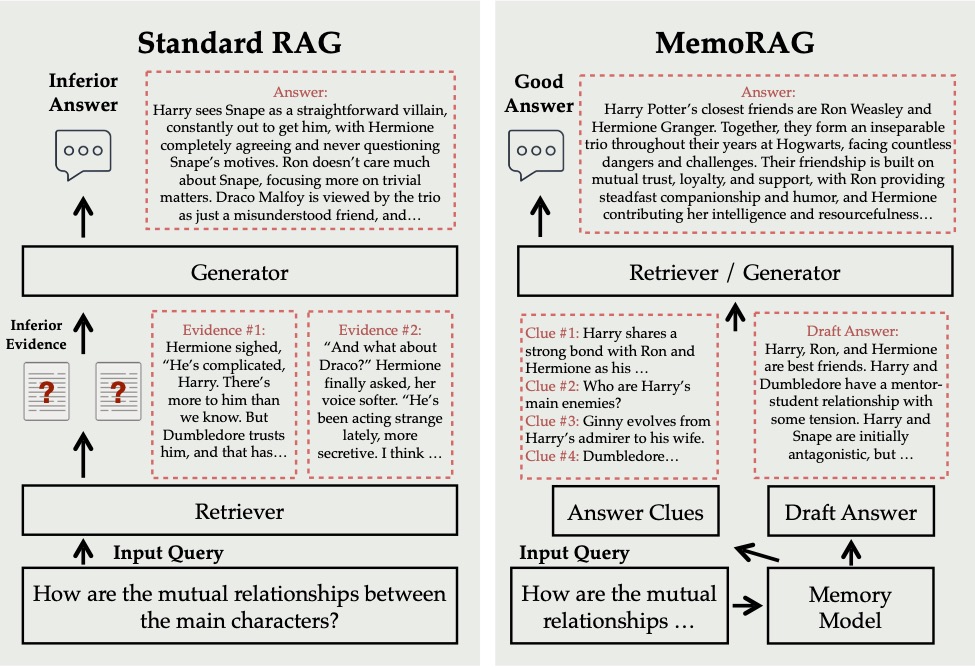
Comparison of Standard RAG systems and MemoRAG (Qian et al.)
In my post “ALICE - AI Leveraged Information Capture and Exploration”, I proposed a system that unifies a Large Language Model (LLM) with a knowledge graph (KG) to archive routinely lost information from literature generating events. While assessing project risks, we have further researched hallucination and semantic sprawl mitigation strategies. I have been focusing on representation learning and embedding space methods to reduce the need for external knowledge bases such as in Retrieval Augmented Generation (RAG) methods. Along the way, I discovered similar current research. In this post, we review “MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery”, a novel approach to RAG by Hongjin Qian, Peitian Zhang, and Zheng Liu from the Beijing Academy of Artificial Intelligence; and Kelong Mao and Zhicheng Dou from Renmin University of China published in the ACM Web Conference 2025. MemoRAG integrates memory mechanisms that will help bypass the limitations of the traditional RAG models. MemoRAG extends previous RAG systems by incorporating a novel dual memory model architecture which uses a lightweight memory model for maintaining long-term information and a heavy weight generator model that refines its output. We will discuss failures of the classical RAG systems, new memory components of MemoRAG, its performance across various benchmarks, and relative advantages on challenging reasoning, long-context summarization, and ambiguity handling.
Challenges of Traditional RAG Systems
Although large language models have revolutionized natural language processing, they still tend to express weaknesses in hallucinating information, maintaining long-term information, dealing with complex queries, and synthesizing unstructured sources of information. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, Lewis et al. 2020 explains how RAG can bridge these gaps by allowing language models to leverage external databases in real time for improved accuracy and relevance . However, in “SG-RAG: Multi-Hop Question Answering with Large Language Models Through Knowledge Graphs 2024”, Saleh et al. show that traditional RAG systems largely fail when there is a need to perform tasks that are more complex, requiring much deeper contextual understanding, ambiguity handling, and synthesis across multiple sources.
Traditional systems are based on a retriever model that fetches relevant information from a pre-indexed knowledge base and a generator model which generates responses in light of the retrieved context. This works when the task is simple, fact-based question-answering but fails when dealing with more complex information or implicit queries that would require synthesis from multiple documents or databases. For example, answering a question that would only require retrieval from a single source and pulled via lexical/semantic similarity — like “when did Apollo 11 land on the moon” would be well served by traditional RAG systems. But a question about how some book develops a theme might involve stitching together different narrative elements with information from multiple sources, which is beyond the capability of most classic RAG systems. Also, when working with unstructured datasets, traditional RAG systems often fail in performance owing to their orientation toward finding an exact answer rather than synthesizing loosely related information.
Reliance on Explicit Queries: Current RAG systems rely on simple, explicitly defined queries to access relevant data. They are intended to perform relevance matching between the input query and curated knowledge bases. But in practice, information requirements are often not clear or explicit, so the system must guess the user’s intention before loading the relevant content. Questions that require explicit reasoning, for example, or indirect citations (such as understanding themes in a text) are difficult to solve using standard RAG methods.
Difficulty with Structured and Distributed Data: Most RAG schemes are designed to work well with structured databases, where information can be pulled from it based on defined input parameters. But any task involving unstructured data (narratives, reports, etc.) is still an issue. Furthermore, when evidence stretches across multiple parts of a dataset, RAG models are typically incapable of bringing all this information together. Multi-hop reasoning, in which we must connect evidence to other points of data, is notoriously challenging for such systems.
Context Window Limitations: LLMs operate on a finite context window and cannot take on large historical interactions or large datasets. Even in the context of RAG systems, this restriction still remains because retrieval algorithms are unable to bridge the gap between long-context processing and short-context processing in any meaningful way. As a result, RAG systems might retrieve weak or partial evidence when performing an exercise that requires inclusion of wide spread information.
Challenges in Query Refinement: One of the problems of RAG systems is that they do not properly sanitize queries for more optimal retrieval outcomes. When the input from the user is ambiguous, standard RAG methods lack tools to translate the query into a practical query. This inconsistency often leads to obfuscated or incomplete fetching which negatively affects the final output.
Limited Applicability Beyond Straightforward Tasks: Standard RAG systems are best suited to tasks such as question answering or simple summarization, for which knowledge retrieval is direct. But they are unable to perform well in more difficult situations like pooling scattered evidence across documents, understanding abstract or complicated questions (e.g., thematic analysis) and working in domain-specific contexts like legal or financial records.
MemoRAG’s solution to Traditional RAG challenges
MemoRAG addresses these challenges through its memory-inspired architecture. The central novelty in MemoRAG is a memory model that enables long-term information storage and retrieval. While previous RAG systems had been based on query-based usage of databases for every different task, MemoRAG proposed a twin-system architecture for memory integration. This architecture includes:
Lightweight Memory Model-Long-Context LLM: It compresses large data in memory tokens representing the whole database and providing clues for answering elaborate queries. Essentially, it acts like a summarizer that builds guideposts for the retrieval process.
LLM-heavy Generator Model: It fine-tunes the information retrieved and produces highly detailed responses in a coherent manner. It does exceptionally well on ambiguous queries, multi-hop reasoning, and summary insights with complexity.
Using this architecture MemoRAG, operates in three main stages:
Memory Formation: Memory model forms a truncated but semantic version of the database. The memory module takes raw input tokens (say, database entries) and compiles them as compressed memory tokens without discarding any semantic information. The mechanism for this is an attentional mechanism of transformers. For example:
The input tokens are passed over a series of transformer layers and context is taken in.
Memory tokens are introduced as long-term knowledge stores which it deciphers and encodes high-level semantic data of the input tokens.
Clue Generation: Depending on the query entered, the memory model produces "clues" intermediate to it, in other words, handwritten solutions to the query that will inform the retrieve. With a continuous append of memory tokens and the elimination of less meaningful data from the input string, the memory module gradually shrinks long inputs into an efficient and concise memory image. The process works similarly to how human memory works – in which short-term information is reduced to long-term memories.
Example: A query like “How does the report discuss financial trends?” might yield clues such as “Identify revenue figures from recent years” or “Locate sections discussing market growth.”
Evidence retrieval and Answer Generation: Based on clues, relevant evidence is pulled from the database and the generator model generates the final result. Memory tokens are used as a mediator between input data and output. When asked a question, the memory module returns cues that tell you what you can expect the answer to be and how to retrieve evidence.
MemoRAG’s memory architecture enables it to synthesize information from disparate sources, bridging the gap where the traditional RAG systems falter. This contributes to the following benefits over traditional RAG systems:
Long-Term Memory: MemoRAG achieves performance beyond the traditional limitations of finite context windows by using a memory model that can compress large data into an accessible representation.
Evidence-Based Retrieval: Clues provided by the system help to steer the retrieval, bridging the gap between a vague query and evidence.
Dual-System Design: Dividing the memory and generation functions between separate models makes MemoRAG free up computational space while maintaining accuracy.

Example of Implicit Query Workflow (Qian et al.)
To illustrate MemoRAG’s advantages, the paper compares MemoRAG with standard RAG by asking the question: “How the book convey the theme of love?” (referring to the Harry Potter series). Standard RAG fails to extract these implied relationships due to scattered evidence and poor formulation in the question. MemoRAG, however:
Creates an internal memory of the book.
Provides placeholder clues, for example defining relationships between characters.
Digs through the clues to pull out pertinent elements and builds a complete and precise solution. This is a way to demonstrate MemoRAG’s capability to handle implicit queries and distributed evidence effectively.
Training the Memory Module
The memory module must be trained at two different phases to ensure its efficacy:
Pre-Training: The memory module gets long contexts in the pre-training phase from various datasets (e.g., novel, papers, reports). That allows the model to learn how to squeeze and store semantics important elements in very long inputs. The RedPajama dataset, a large set of quality texts, was extensively used to do this.
Supervised Fine-Tuning (SFT): At the fine-tuning phase, the memory module is trained on task data in order to get the most clues possible. This entails:
To give the model a question, long context, and an answer.
Programming it to output intermediate hints between the query and the long context.
The authors designed 17,116 supervised fine-tuning samples to improve MemoRAG’s response in questions answering and summarization tasks.
Performance and Benchmark Evaluation
MemoRAG was tested against two benchmarks:
Standard Benchmarks: Applied to datasets including NarrativeQA (questions-asking), HotpotQA (multi-hop reasoning), and MultiNews (summaries of multiple documents).
ULTRADOMAIN, designed by the authors to test the ability of LLMs to handle long-context tasks across diverse domains like the Law, Finance, and Education. The evaluation tasks included both in-domain, closer to that provided for training the model and out-of-domain, meaning the contextual presentation involved new and unfamiliar settings.
In-domain tasks: MemoRAG demonstrates very solid gains over the comparator models in domains like Law and Finance, where precision and integration of information are key. As a simple example, in tasks dealing with legal matters, the memory model of MemoRAG allowed it to infer better relations between clauses.
Out-of-domain tasks: The performance of MemoRAG was also very impressive across out-of-domain settings, including summarization of philosophical works or fiction. It has secured a 2.3% gain compared to the top-performing baselines over the Fiction dataset by effectively synthesizing high-level themes and insights from long-context information.
Assessment metrics varied depending on the task but F1 score for questions and Rouge-L for summaries was the most common.
MemoRAG’s performance was benchmarked against several modern baselines:
Full Context Processing: Conveniently exposing the full context to large language models.
General RAG Approaches:
BGE-M3: A generic retriever.
RQ-RAG: A query optimization framework which reduces queries into simpler subqueries.
HyDE: Creates fake documents for navigating the retrieved data.
Alternative Generative Models: MemoRAG’s generator model was compared to popular models such as Mistral-7B and Llama3-8B.
Multi-Hop Reasoning and Distributed Evidence
MemoRAG is unique in that it can support multi-hop reasoning, meaning that it draws evidence from multiple sources in order to formulate answers to complex questions. Whereas traditional RAG models evaluate each query in isolation, the memory component of MemoRAG enables information to be fetched and synthesized from a set of distributed sources. This is particularly helpful in domain-specific areas such as finance, where determining factors for revenue growth requires synthesis from a number of reports and inferences from a set of relationships such as expanded market and reduced cost.
Enhanced Summarization Capabilities
MemoRAG did a great job summarizing unstructured and long documents like government reports, legal contracts, and academic papers. Because of its global memory capabilities, summaries are more concise, detailed, and accurate than those generated by baseline systems. This makes the system particularly useful in areas of journalism, law, and academia that require a great amount of data synthesis.
Innovations in Memory Integration
MemoRAG encodes its tokens with crucial aspects of large-scale contexts. These tokens serve as the ways that enable the model to recall information from memory. This makes the model highly efficient on long-context tasks. Regarding training, MemoRAG involves a two-step process: unsupervised pre-training over large datasets and task-specific supervised fine-tuning. This guarantees that memory tokens are optimized for the generation of relevant clues with the goal of improving retrieval accuracy and speed.
ULTRADOMAIN benchmark results showed MemoRAG making massive gains:
On in-domain datasets (i.e., legal and financial contexts), MemoRAG scored an average F1 improvement of 9.7 points on the best-performing baseline.
MemoRAG outperformed baselines across 18 disciplines on out-of-domain datasets by an average of 2.4 points (showcasing its versatility). For example:
For financial data, MemoRAG scored 48.0 F1 score (40.8 by the nearest baseline).
In the long-context domain (e.g., college textbooks), MemoRAG did not degrade much even at extremely long context lengths.
MemoRAG’s advantage lies in its new clue-driven retrieval algorithm and memory model implementation. In contrast to conventional RAGs that find unreliable or redundant evidence, MemoRAG:
Finds semantically rich clues to refine retrieval.
Analyzes long contexts more effectively, without the truncation complications that conventional systems have.
Works well on difficult complex problems like multi-hop reasoning and summarization, where other solutions fall flat.
MemoRAG’s strategy of combining retrieval and generation of memory has important implications for developing artificial intelligence and its uses:
Scalability of AI Models: MemoRAG shows how memory modules extend the optimal context window of LLMs and allow them to consume datasets which were once considered too large. This would open the door for cheap AI solutions that can outperform big models without significantly more computation power.
Better Knowledge Discovery: By enabling an exchange of raw data to meaningful information, MemoRAG can support knowledge-intensive activities such as scientific research, policy analysis, and technical writing.
Personalization: Since it’s built with and stores long-term memory, MemoRAG can match individual user preferences and records to create personalized recommendations for entertainment, e-learning, and e-commerce.
Future AI Research: MemoRAG’s framework revolutionizes retrieval-based systems with its memory-inspired design. It might spur more research into hybrid architectures that integrate retrieval and memory better.
Conclusion: MemoRAG and the Future of Retrieval-Augmented AI
MemoRAG has addressed the fundamental drawbacks of traditional RAG architecture by adopting a memory-based architecture. With a memory module that produces global, context-dependent representations, MemoRAG is perfect for tasks involving complicated logic, extended contexts, and evidence gathering.
The framework scores very well on the ULTRADOMAIN benchmark for its versatility and power to handle both in-domain and out-of-domain datasets. Using it for everything from legal defense to conversational AI, MemoRAG reveals how memory-based systems can help to expand the limits of what a language model can be.
As AI systems mature, technologies such as MemoRAG could be the basis for handling even more sophisticated tasks, straddling the divide between retrieval and complex reasoning. My work on ALICE involves doing similar retrieval and clue systems via knowledge graph structure and the techniques used by MemoRAG will help inform ALICE’s development by both providing a comparative methodology to evaluate against and hints on how to achieve greater information coherence for truth grounded response. This performance by MemoRAG is a reflection of the next generation of AI systems that will be able to retrieve and generate information but also remember, infer, and synthesize knowledge in ways that are becoming increasingly indistinguishable from human cognition. As AI continues to evolve, it is models such as MemoRAG that will lie at the heart of nuanced information-based tasks characteristic of the modern world.
Jim Ecker
References
- Qian, H., Zhang, P., Liu, Z., Mao, K., and Dou, Z., “MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery”, 2024. URL https://doi.org/10.48550/arXiv.2409.05591.
- Lewis P., Perez E., Piktus A., Petroni F., Karpukhin V., Goyal N., Kuttler H., et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”, 2020, URL https://doi.org/10.48550/arXiv.2005.11401
- Saleh, Ahmmad O. M., Tur, Gokhan., Saygin, Yucel., “SG-RAG: Multi-Hop Question Answering with Large Language Models Through Knowledge Graphs,” ICNLSP 2024. URL 2024.icnlsp-1.45
- Weber, M., Fu, D., Anthony, Q., Oren, Y., Adams, S., Alexandrov, A., Lyu, X., Nguyen, H., Yao, X., Adams, V., Athiwaratkun, B., Chalamala, R., Chen, K., Ryabinin, M., Dao, T., Liang, P., Ré, C., Rish, I., and Zhang, C., “RedPajama: an Open Dataset for Training Large Language Models”, 2024. URL https://doi.org/10.48550/arXiv.2411.12372.
- Kočiský, T., Schwarz, J., Blunsom, P., Dyer, C., Hermann, K. M., Melis, G., and Grefenstette, E., “The NarrativeQA Reading Comprehension Challenge,” , 2017. URL https://doi.org/10.48550/arXiv.1712.07040.
- Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., and Manning, C. D., “HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering” , 2018. URL https://doi.org/10.48550/arXiv.1809.09600.
- Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., and Liu, Z., “BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation” , 2024. URL https://doi.org/10.48550/arXiv.2402.03216.
- Chan, C.-M., Xu, C., Yuan, R., Luo, H., Xue, W., Guo, Y., and Fu, J., “RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation” , 2024. URL https://doi.org/10.48550/arXiv.2404.00610.
- Gao, L., Ma, X., Lin, J., and Callan, J., “Precise Zero-Shot Dense Retrieval without Relevance Labels” , 2022. URL https://doi.org/10.48550/arXiv.2212.10496.
- Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E., “Mistral 7B” 2023. URL https://doi.org/10.48550/arXiv.2310.06825
- Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, et al., “The Llama 3 Herd of Models” , 2024. URL https://doi.org/10.48550/arXiv.2407.21783.
Comments
Post a Comment