2024-11-15: The 33rd ACM International Conference on Information and Knowledge Management (CIKM) 2024 Trip Report

CIKM 2024 took place in Boise, Idaho, in the Mountain West part of the United States. The mountains in the background distinguish the pictured Idaho State Capitol from the US Capitol.
ACM CIKM 2024 was held from October 21 through 25 in Boise, Idaho. There were over 800 attendees, including over 400 students! Parallel topic sessions included presentations for full papers, resource papers, and invited journal papers. Short papers were presented as posters altogether in one session. The three attendees writing this trip report are Himarsha Jayanetti and Lesley Frew (WS-DL PhD students at ODU) and Gangani Ariyarathne (PhD student at William & Mary supervised by WS-DL alum Alexander Nwala).
Monday
Tutorials
Day 1 at #CIKM2024!
— Himarsha R. Jayanetti (@HimarshaJ) October 21, 2024
Attending the tutorial "Collecting and Analyzing Public Data from Mastodon" by @harisbinzia to learn and gain hands-on experience with the decentralized social network, Mastodon.@WebSciDL pic.twitter.com/0GA4aC1PZ4
On the first day of the conference, there was a line up of tutorials on cutting edge topics like large language models, quantum machine learning, fairness, graph analytics, and AI in industry. I (Himarsha) attended the afternoon tutorial titled “Collecting and Analyzing Public Data from Mastodon” by Haris Bin Zia, a PhD student at the Queen Mary University of London. He started by discussing the significance of studying Mastodon, given the evolving privacy concerns, new regulations like the Digital Markets Act, and shifts in social networks, including Meta's leaning toward the Fediverse. All of these show a high level of interest towards decentralized platforms that prioritize data privacy and user autonomy. He also highlighted the key research areas for decentralized networks including influence and virality, interoperability, and recommendation systems (Mastodon currently doesn’t have one and the content is displayed in reverse chronological order). Before starting the tutorial he mentioned that the data collection challenges on Mastodon result not only because the data is scattered across servers requiring aggregation but also from rate limits, and privacy concerns. We then explored Mastodoner, a tool for discovery, filtering, secure data sharing, and ethical data handling on the Mastodon platform. We followed the tutorial below to explore the usage of the tool.
I asked two questions from the speaker: one about the rate limit (approximately 300 requests per 5 minutes), and another about keyword search functionality, which is not available right now but will be added to the next release.
Additionally during this tutorial session, I learned about Fediverse Observer, a service for finding all the servers within the Fediverse, and that Threads now allows users to post directly to the Fediverse through their app.
Event: Student Murder Mystery Event
🕵️♀️ What a night! The CIKM 2024 Student Social Event's Murder Mystery was a thrilling success! 🎭🔍 Thank you to everyone who joined, solved the mystery, and made it a memorable evening. Check out some highlights from the event below! 📸✨ #CIKM2024 #MurderMystery pic.twitter.com/PukfTIcXEX
— ACM CIKM 2024 (@cikm2024) October 22, 2024
Monday night was a student gathering organized by the conference, but rather than a typical reception, it was an exciting Murder Mystery Event hosted by Boise's Watson's Mystery Cafe. We teamed up with other students to solve the mystery of who killed Arthur Roy, a movie star from 1895, with the help from “Sherluck” Holmes!
Tuesday
Opening/Keynote
The conference opened on Tuesday, and the conference chairs (@f_spezzano and @serraedoardo) presented about registrations and submissions. The conference accepted 646 of 2485 submissions, for a 26% overall acceptance rate. The full and applied paper chairs (@DrCh0le and @YinglongXia) then talked about the paper review process. Both authors and reviewers came from all over the world. Similar to SIGIR in 2023 and 2024, reviewers and authors do not come from the same country.
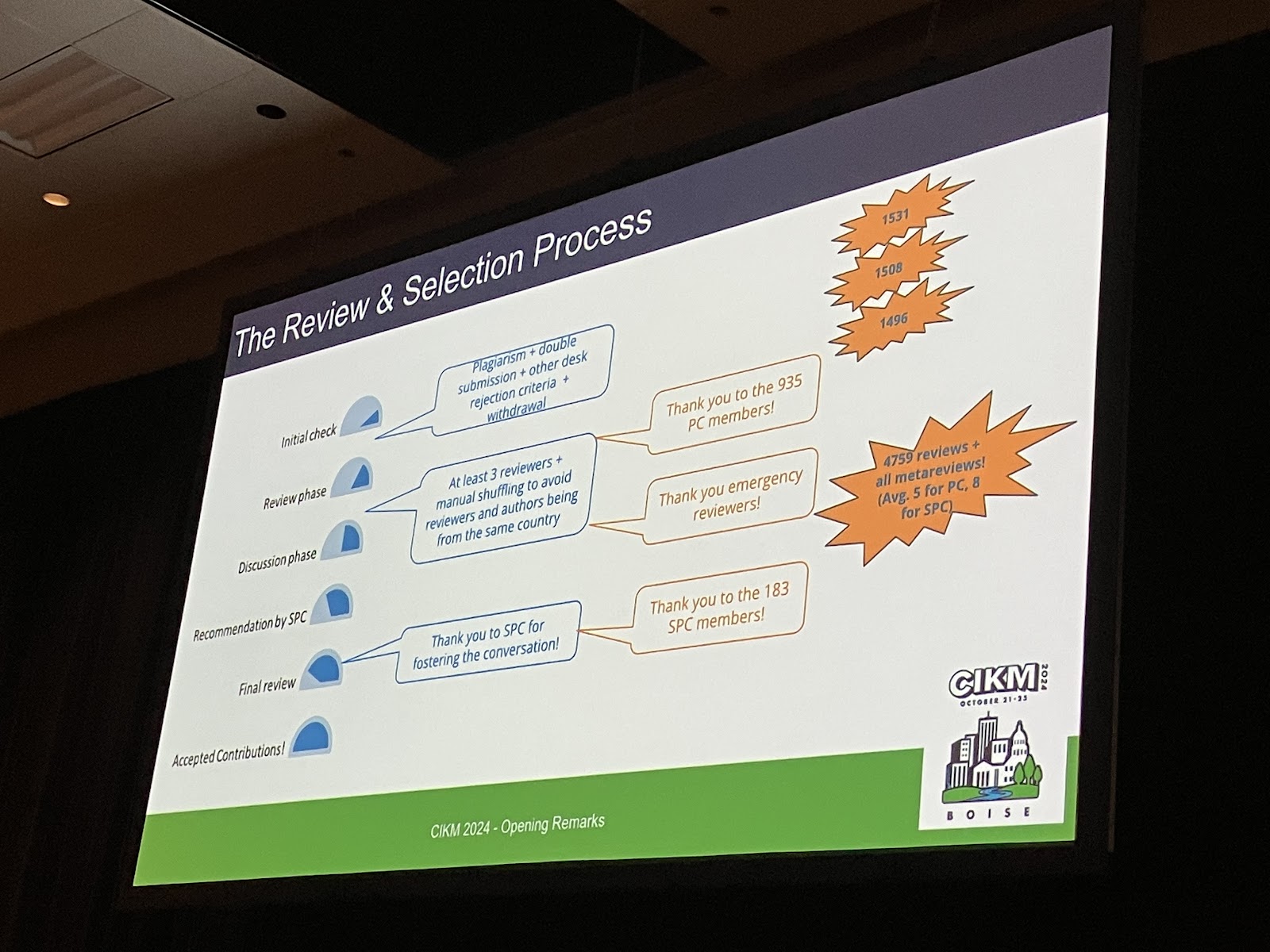
The review process for CIKM avoids undeclared conflicts of interests by assigning reviewers from different countries.
Day 2 at #CIKM2024!
— Himarsha R. Jayanetti (@HimarshaJ) October 22, 2024
First day of the main conference. Opening remarks are happening now!
@lesley_elis @WebSciDL @cikm2024 @BoiseCentre pic.twitter.com/13RI6KqmqP
Following the conference introduction, the first keynote, “Traversing the Journey of Data and AI: From Convergence to Translation” was given by Nitesh Chawla (@nvchawla). He talked about his research using the convergence technique to solve problems, which uses a compelling problem as motivation and interdisciplinary efforts to solve the problem, as well as the translation technique which converts lab discoveries to practical applications that can be deployed at scale. First, he talked about his research, “SaludConectaMX: Lessons Learned from Deploying a Cooperative Mobile Health System for Pediatric Cancer Care in Mexico.” The problem was that the Hospital Infantil de Mexico Federico Gomez which treats pediatric cancer lacks digital records, which hinders timely care. To attack the problem, they worked with doctors and social scientists, and came up with solutions including digitizing records, building models that took into account social conditions such as caregiver attributes, and created LLM chatbots for both hospitals and caregivers. Next, he talked about his research, “Predicting job performance using mobile sensing.” To solve this problem, the team incorporated cognitive science, psychology, sociology, and medical perspectives to make progress for solutions for both the variance of data within each individual and the collective. This research was featured in Time Magazine. Finally, he talked about his work with the Center for Computer Assisted Synthesis on the integration of chemistry and computer science. He talked about his research, “On the use of real-world datasets for reaction yield prediction,” where the main takeaway was that data sparsity in chemistry is prohibitive for developing many AI solutions in this domain.
Day 2 at #CIKM2024!
— Himarsha R. Jayanetti (@HimarshaJ) October 22, 2024
Keynote titled "Data and AI Convergence to Translation: Advancing Common Good” by Nitesh Chawla @nvchawla is happening now.
He is discussing the importance of harnessing the full potential of AI for societal benefits.@lesley_elis @WebSciDL @NotreDame pic.twitter.com/PFvt2FANac
Session: Misinformation
.@jgarcia1599 is now presenting @cikm2024 their work “Data Void Exploits: Tracking & Mitigation Strategies” #CIKM2024https://t.co/aVaotsayni pic.twitter.com/j0wO7kQlJR
— Gangani Ariyarathne (@GanganiAri) October 22, 2024
After lunch, we attended the session on Misinformation. First, Qiong Nan presented her work, “Let Silence Speak: Enhancing Fake News Detection with Generated Comments from Large Language Models.” She proposed GenFEND, which uses an LLM to generate synthetic user comments based on user attributes (gender, age, education) to reduce imbalance from underrepresented groups. She measured the diversity of subgroups, for use in a weighted aggregation of the model. Then, she used her system to successfully classify news as real or fake. Next, Xiaoyu Li presented his work, “DiHAN: A Novel Dynamic Hierarchical Graph Attention Network for Fake News Detection.” He proposed a new graph model for detecting fake news that takes temporal attributes into account. Next, Jinghan Zhang proxy presented “Why Misinformation is Created? Detecting them by Integrating Intent Features.” The authors created an intent hierarchy by extracting already identified psychological motivations for sharing misinformation from existing literature such as influencing public perception and smearing specific individuals. Based on their model they successfully performed misinformation classification. Evelyn Navarette then proxy presented a paper from her research center L3S, “Multimodal Misinformation Detection using Large Vision-Language Models.” The authors created a 3 step model using LLMs, taking into account image and text information first, then using that ranked output as input to the next LLM, in order to verify facts. Junior Garcia (@jgarcia1599) presented his work, “Data Void Exploits: Tracking & Mitigation Strategies.” His work used Google Search Trends to track the temporal introduction of misinformation, which allows researchers to historically analyze concepts even post mortem. This paper won the best paper award.
Session: Privacy, News, Specialized Applications
At the "Privacy, News, Specialized Applications" session, João Leite introduced “EUvsDisinfo: a Dataset for Multilingual Detection of Pro-Kremlin Disinformation in News Articles.” This resource is pivotal for understanding and countering disinformation across different languages and cultural contexts.
Gangani Ariyarathne presented “3DLNews: A Three-decade Dataset of US Local News Articles,” a comprehensive three-decade dataset of U.S. local news articles from more than 14,000 local news websites, providing valuable data for studying trends, social dynamics, and shifts in public discourse over time.
Thrilled to present our research resource paper at 33rd ACM International Conference on Information and Knowledge Management #CIKM2024 in the Resource Track! @cikm2024 @BoiseCentre https://t.co/8xIvaC1kvY pic.twitter.com/0xtnPfUf8a
— Gangani Ariyarathne (@GanganiAri) October 23, 2024
Himarsha R. Jayanetti and Lesley Frew presented “To Re-experience theWeb: A Framework for the Transformation and Replay of Archived Web Pages” on behalf of the authors; John Berlin, Mat Kelly, Michael L. Nelson, Michele C. Weigle. This work was based on John Berlin’s MS Thesis work, which he summarized in a WS-DL blog post.
Event: Welcome Reception/Short Paper Posters
Tonight at the Poster Session during the #CIKM2024 Welcome Reception, @lesley_elis presented her short paper titled “Retrogressive Document Manipulation of US Federal Environmental Websites”. @weiglemc @phonedude_mln @WebSciDL @cikm2024 pic.twitter.com/MalRAFLGdB
— Himarsha R. Jayanetti (@HimarshaJ) October 23, 2024
The 141 accepted short papers were presented as posters during the Welcome Reception. The reception featured local potatoes in a variety of formats, along with plenty of other casual dishes like tacos and pizza. Lesley presented her short paper, “Retrogressive Document Manipulation of US Federal Environmental Websites.” She aligned the EDGI US federal environmental websites 2016-2020 dataset with the Bing ORCAS query-click dataset of the same timeframe to show that query terms were being deleted on these web pages during this timespan, lowering public access to environmental and regulatory information.
Wednesday
Keynote
The second keynote was on “Is the Search Engine of the Future a Chatbot?” by Suzan Verberne (@suzan). This keynote provided a deep dive into how large language models (LLMs) are reshaping the future of information retrieval (IR), the challenges they bring, and why traditional IR principles remain crucial.
Day 3 at #CIKM2024!
— Himarsha R. Jayanetti (@HimarshaJ) October 23, 2024
Keynote titled "Is the Search Engine of the Future a Chatbot?” by Suzan Verberne (@suzan) is happening now.@lesley_elis @WebSciDL @UniLeiden @TMLeiden pic.twitter.com/mhNcHVBzhm
She began by mapping out the paradigm shift in NLP over recent years, from feature-based supervised learning to transfer learning and finally to in-context learning, contrasted the older, resource-heavy approach of training models from scratch with today’s methods, which leverage pre-trained models like BERT. Now, we’ve entered an era where generative LLMs can handle tasks with minimal additional training by following prompts and examples; a method known as in-context learning. She highlighted this shift with an example query, “What places should I visit in Boise?”, demonstrating how conversational LLMs can quickly generate coherent answers for common search queries. In-context learning has opened up new possibilities, especially in summarization and question-answering tasks, where it can outperform older transfer-learning models. However, Verberne noted that while in-context learning shows potential for classification and extraction tasks, its success still depends heavily on the task and the model’s fine-tuning. A significant portion of her talk explored the challenges that accompany LLMs. First and foremost is hallucination, the tendency of LLMs to generate plausible but incorrect information. As she explained, this issue becomes particularly problematic when handling low-resource topics or when sources aren’t directly linked to generated content. In her words, “ ChatGPT is plausible but not factual,” highlighting the importance of verifying outputs before accepting them as true. Bias in LLMs is another critical concern. She noted that human biases such as gender stereotypes in phrases like "a nurse is female, a doctor is male" are often amplified by LLMs, reinforcing prejudices. Ethical considerations also included the environmental cost of LLMs, with massive energy consumption involved in training and inference. She also raised concerns about the reliance on low-cost labor for data optimization tasks, a less-discussed but vital issue in the ongoing dialogue around AI ethics . She said that IR can complement LLMs through approaches like retrieval-augmented generation (RAG). By grounding responses in actual sources, RAG can help mitigate hallucinations though, as she noted, it doesn’t eliminate them. RAG shines in domains requiring factual accuracy and context, such as legal questions, where responses are best informed by specific and authoritative documents. She also said that RAG is not without challenges. Hallucination still occurs, especially with ambiguous or complex queries.
“RAG can reduce hallucination,
— Himarsha R. Jayanetti (@HimarshaJ) October 23, 2024
.
.
.
But not fully prevent it”
A small rock a day keeps the doctor away? 🧐@lesley_elis @WebSciDL @suzan @TMLeiden @UniLeiden pic.twitter.com/VcxZnzDGKX
As she explained, RAG’s main advantages lie in connecting responses to their sources, improving user trust through transparency, and enabling domain-specific customization. This adaptability is particularly beneficial in professional environments that rely on proprietary databases and knowledge bases, where maintaining up-to-date information is crucial without retraining the entire model.
She argued that RAG represents an exciting shift in search engine functionality but doesn’t entirely replace traditional IR’s strengths. A search engine still needs to manage diverse query intents whether navigational, informational, exploratory, or high-recall and continue to deliver relevance, diversity, and transparency. She emphasized that IR isn’t just about ranking and relevance; it’s fundamentally user-oriented. Search engines must consider result diversity, fairness, source trustworthiness, and transparency, ensuring users see why a document is relevant. Additionally, inference speed matters in ensuring a smooth search experience, and any IR strategy must minimize latency.
For commercial applications, she cautioned that LLM-based engines can pose risks, but there’s an opportunity in using LLMs to generate training data for IR models. She also mentioned that, this data-generation potential opens doors for faster development of robust datasets while circumventing some costs of manual data labeling.
She also discussed how LLMs can assist users in exploratory search. Since exploratory queries are often short and underspecified, LLMs can help users refine their searches by explaining how the initial query was interpreted. By revealing the underlying assumptions of a short query, search engines could help users better define their information needs.
She concluded with a thought-provoking answer to the keynote’s central question: while chatbots have a promising future, the perspectives and frameworks of IR remain essential. Finally, she emphasized that we must bridge the gap between retrieval and LLMs, expanding beyond benchmarks and models to address real-world problems with transparency and fairness.
Session 1
For session 1 on Tuesday, there were eight parallel sessions, and we each went to a different one. We will highlight a few papers from the various sessions.
At the Knowledge Discovery session, Yannik Hahn presented “Quality Prediction in Arc Welding: Leveraging Transformer Models and Discrete Representations from Vector Quantised-VAE.” This applied paper contributes a dataset of labeled and unlabeled examples to this unique domain.
At the Fairness session, Kathleen Cachel (@kathcachel) presented “Wise Fusion: Group Fairness Enhanced Rank Fusion.”This work addresses the problem of fairness in black-box aggregation lists. Kathleen has also published work at the ACM Conference on Fairness, Accountability, and Transparency (FAccT).
.@KathCachel is now presenting her work, “Wise Fusion: Group Fairness Enhanced Rank Fusion” #cikm2024 https://t.co/uNcl4UPlG8 pic.twitter.com/6CcxUz5j7D
— Lesley Frew (@lesley_elis) October 23, 2024
At the NLP session, Zhipang Wang discussed "Learning to Differentiate Pairwise-Argument Representations for Implicit Discourse Relation Recognition," focusing on enhancing accuracy in recognizing implicit discourse relations through pairwise-argument representations. A proxy presented "L-APPLE: Language-Agnostic Prototype Prefix Learning for Cross-lingual Event Detection," introducing a framework that enables effective event detection across languages without heavy reliance on language-specific resources. Tz-Huan Hsu introduced“PIECE, a system designed to improve timeline summarization through protagonist identification and event chronology extraction.” The presentation detailed how the model identifies key protagonists in narratives and organizes events in chronological order to create coherent and informative timelines. This work is significant for applications in historical data analysis and news summarization, offering users a clear view of events and their relationships over time. Lastly, Fnu Mohbat presented "LLaVa-Chef: A Multi-Modal Generative Model for Food Recipes," which generates diverse food recipes by combining text and visual inputs, thereby enhancing personalized cooking experiences. The presentation highlighted the model's capabilities in understanding ingredients and cooking techniques, allowing it to generate diverse and creative recipes.
Fnu Mohbat is now presenting his work “LLaVa-Chef: A Multi-modal Generative Model for Food Recipes” at NLP session in #cikm2024
— Gangani Ariyarathne (@GanganiAri) October 23, 2024
DOI: https://t.co/5nJYAVWHFR pic.twitter.com/yA0OTTXhUP
Five research papers were presented during the Computer Vision session. Shuili Zhang (presented on behalf of Dongming Zhou) discussed the cross-modal knowledge reasoning for visual-language navigation, while Jungi Lee presented their proposed generalized approach for noisy data handling using k-NN. Yehonatan Elisha presented their work on probabilistic path integration with baseline distribution mixtures. Ziyi Kou presented FaDE, a framework for face identity anonymization in fair face recognition and finally, Shuili Zhang presented her work on improvements in multi-modal structured knowledge representation using hard negative samples.
Day 3 at #CIKM2024!
— Himarsha R. Jayanetti (@HimarshaJ) October 23, 2024
Session: Computer Vision (FP22)
Presentation 1: Learning Cross-modal Knowledge Reasoning and Heuristic-prompt for Visual-language Navigation, By Dongming Zhou
DOI: https://t.co/iUt7IC5Bbz@WebSciDL @CIKM2024 pic.twitter.com/IXMmGsakFT
Session 2: IR & LLM
Seven research papers were presented during the IR & LLM session. Zhongxiang Sun presented their work on “Large Language Models enhanced Collaborative Filtering” (LLM-CF) framework inspired from the in-context learning and chain of thought reasoning in LLMs. Zhongzhou Liu then presented their proposed framework of Collaborative Cross-modal Fusion with Large Language Models (CCF-LLM) for Recommendation”. Yuxuan Hu delivered a recorded presentation for “APTNESS: Incorporating Appraisal Theory and Emotion Support Strategies for Empathetic Response Generation”. Yuhao Wang then presented their proposed LLM-enhanced paradigm for multi-scenario recommendation named LLM4MSR. Jizheng Chen introduced ELCoRec, a method for enhancing language understanding in recommendation models by incorporating numerical and categorical features through a GAT expert model. Bo Pan presented their work on “Distilling Large Language Models for Text-Attributed Graph Learning” by training an interpreter model with rich rationale and then a student model that mimics the interpreter's reasoning without the rationale. Finally, in a recorded presentation Yuchen Shi presented “AgentRE: An Agent-Based Framework for Navigating Complex Information Landscapes in Relation Extraction”, an agent-based framework that leverages the full potential of LLMs including memory, retrieval and reflection, to achieve elation extraction (RE) in complex scenarios.
Day 3 at #CIKM2024!
— Himarsha R. Jayanetti (@HimarshaJ) October 23, 2024
Session: IR & LLM (FP24)
Presentation 1: Large Language Models Enhanced Collaborative Filtering, By Zhongxiang Sun
DOI: https://t.co/WEwb9aBy86@WebSciDL @CIKM2024 #CIKM2024 pic.twitter.com/ghpig9s297
Event: Banquet
The conference dinner was held at the Boise Centre. A jazz quartet played great music while we ate our bacon-wrapped steaks and potato galettes. After dinner, the conference committee presented the awards. Congratulations to all the winners!
#CIKM2024 Banquet Dinner happening now!
— Himarsha R. Jayanetti (@HimarshaJ) October 24, 2024
Jazz music setting the tone for the night!@lesley_elis @GanganiAri @WebSciDL @cikm2024 pic.twitter.com/BbhW9p6Z07
- Best paper: “Data Void Exploits: Tracking & Mitigation Strategies” by Miro Mannino,Junior Garcia,Reem Hazim,Azza Abouzied,Paolo Papotti
- Best student paper: “Physics-guided Active Sample Reweighting for Urban Flow Prediction” by Wei Jiang,Tong Chen,Guanhua Ye,Wentao Zhang,Lizhen Cui,Zi Huang,Hongzhi Yin
- Best short paper: “GeoReasoner: Reasoning On Geospatially Grounded Context For Natural Language Understanding” by Yibo Yan,Joey Lee
- Best applied paper: “A Real-Time Adaptive Multi-Stream GPU System For Online Approximate Nearest Neighborhood Search” by Yiping Sun,Yang Shi,Jiaolong Du
- Best student applied paper: “Robust Sequence-Based Self-Supervised Representation Learning for Anti-Money Laundering” by Shuaibin Huang,Yun Xiong,Yi Xie,Tianyu Qiu,Guangzhong Wang
- Best resource paper: ”pyPANTERA: A Python PAckage for Natural language obfuscaTion Enforcing pRivacy & Anonymization” by Francesco Luigi De Faveri,Guglielmo Faggioli,Nicola Ferro
- Best demo paper: “Introducing CausalBench: A Flexible Benchmark Framework for Causal Analysis and Machine Learning” by Ahmet Kapkiç,Pratanu Mandal,Shu Wan,Paras Sheth,Abhinav Gorantla,Yoonhyuk Choi,Huan Liu,K. Selçuk Candan
- Test of time: “Learning deep structured semantic models for web search using clickthrough data” by Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, Larry Heck
Thursday
Keynote
On Thursday, Charu C. Aggarwal from IBM Research Center in Yorktown Heights gave the third keynote speech of the conference, “Ensembles for Outlier Detection and Evaluation”. He explained the history of outlier ensembles, and explained how they improve performance by making algorithms less sensitive to parameter choice. He emphasized that there is no single "best" algorithm in unsupervised tasks and using ensembles can help reduce the dependence on specific parameters. The results he discussed showed that methods like KNN, Kernel Mahalanobis, and Isolation Forest performed well, while a "trinity ensemble" approach (an ensemble of ensembles, one that is combining multiple ensembles) showed even better performance.
The third #CIKM2024 Keynote is happening now!
— Lesley Frew (@lesley_elis) October 24, 2024
Charu C. Aggarwal of IBM T. J. Watson Research Center is giving his talk, “Ensembles for Outlier Detection and Evaluation”@HimarshaJ @WebSciDL pic.twitter.com/qLIP58Emra
Session: IR & LLM
There were 8 resource track papers presented at the LLMs Applications and Sentiment Analysis session on Thursday afternoon. Juhao Ma opened the session with a presentation titled “CH-Mits: A Cross-Modal Dataset for User Sentiment Analysis on Chinese Social Media”. The study proposed the PEMNet model to address challenges in detecting true emotional polarity when images and text convey different sentiments. The next presentation was by Patricia Chiril, on BioMAISx, the first English dataset of direct quotes on agricultural biotechnologies, compiled from Africa-based news sources. The third presentation was titled “Covid19-twitter: A Twitter-based Dataset for Discourse Analysis in Sentence-level Sentiment Classification” by Asef Nazari. Their paper introduced a 100k-tweet dataset to study Contrastive Discourse Relations (CDRs) in sentiment classification. The authors used emoji analysis and VADER for automatic labeling instead of manual annotation. Next presentation was by Hanane Djeddal where she introduced a reproducible evaluation framework for benchmarking attributed information seeking. Their framework can be used with any backbone LLM and incorporate three architectural designs such as Generate, Retrieve-then-Generate, and Generate-then-Retrieve. The next presentation was by Honggu Kim titled “Dataset Generation for Korean Urban Parks Analysis with Large Language Models”. His study contributed a dataset of 42,187 Instagram images tagged with #Seoul and #Park, filtered and annotated using InternLM-XComposer2 and GPT-4 to analyze urban park usage, including physical elements, activities, animals, and emotions. The next presentation was a recorded talk by Yanlin Zhang titled “ELF-Gym: Evaluating Large Language Models Generated Features for Tabular Prediction”. Following that, Yiwen Peng also presented a recorded talk titled “Refining Wikidata Taxonomy using Large Language Models”. The final presentation of the LLMs Applications and Sentiment Analysis session was by Bulou Liu. He presented their paper titled “LeDQA: A Chinese Legal Case Document-based Question Answering Dataset”, the first Chinese legal case document-based question answering dataset, featuring 100 case documents, 4,800 case-question pairs, and 132,048 sentence-level relevance annotations. The dataset is created with GPT-4 for efficient annotation, to enhance legal AI applications and improve question answering models.
Presentation 1: CH-Mits: A Cross-Modal Dataset for User Sentiment Analysis on Chinese Social Media, By Juhao Ma
— Himarsha R. Jayanetti (@HimarshaJ) October 24, 2024
DOI: https://t.co/OsFWAIPHMt@WebSciDL @CIKM2024 #CIKM2024 pic.twitter.com/m7vrsw8E5K
Friday
PhD Symposium
On the last day of the conference, 19 PhD students presented their ongoing research at the PhD symposium. It was a great opportunity for doctoral students to receive feedback and engage in discussions with peers and mentors. The organizing committee announced that the PhD symposium this year had an unexpectedly high number of submissions, with the lowest acceptance rate (20.41%) among all paper tracks.
There were five presentations in session 2. As the first presenter, Maryam Amirizaniani presented "Assessing Human Viewpoints in Theory of Mind for Large Language Models in Open-Ended Questioning". Theory of Mind (ToM) is the ability to understand that others' beliefs, desires, intentions, emotions, and thoughts may differ from one's own. In this presentation, she explored how LLMs' ToM capabilities are essential for delivering effective responses in real-world scenarios. The research highlights that while incorporating questioners' viewpoints improves LLMs' reasoning, their responses still fall short of human-like understanding, revealing limitations in interpreting human mental states.
Next, Dae-Young Park presented "Graph-theoretical Approach to Enhance Accuracy of Financial Fraud Detection Using Synthetic Tabular Data Generation". His research addressed the key challenges in financial fraud detection (FFD) data, such as class imbalance and data sparsity, by introducing novel graph-theoretical generative models, SeparateGGM and SignedGGM.
I (Himarsha) presented "Evaluating Social Media Reach via Mainstream Media Discourse". Our work focuses on understanding how social media content is amplified through mainstream media by expanding their reach to new audiences. We would use the data from Internet Archive’s TV News Archive to explore how social media content flows into TV news and the contexts in which it is incorporated. We will also develop methods to quantify the amplification and impact of social media content when integrated into mainstream TV news broadcasts.

Next, Wenbo Wang explored "The ‘Path’ to Clarity: Identifying False Claims Through a Knowledge Graph Exploration". He introduced Path-FC, an automatic fact-checking model that is designed to identify false claims by incorporating additional contextual information through knowledge graph exploration. A key idea is identifying false claims by learning the difference between claims and evidence. Experimental results show significant performance improvements, and their code is available at Path-FC GitHub.
Finally, Sarah Condran presented "The Veracity Problem: Detecting False Information and its Propagation on Online Social Media Networks". She proposes an ensemble framework that covers multiple aspects of false information, identifying bad actors and their intent in coordinated campaigns, and creating a cross-platform dataset to study how false information spreads across social media platforms.
Summary

Himarsha, Lesley, and Gangani presenting at CIKM and enjoying the sights in Boise including a Steelheads hockey game
Our key takeaway from the conference was the spotlight on large language models (LLMs), with research papers and keynotes highlighting the hottest trends and innovations shaping the field.
We learned about tools like VADER, a sentiment analysis tool that is specifically designed for social media data (paper), and InternLM-XComposer2, a vision-language model for text-image composition and comprehension (arXiv, demo), both of which could be useful for our own work.
Our week in Boise for CIKM ‘24 was truly rewarding. We had the pleasure of exploring the city’s attractions, sampling potato-inspired dishes, all the while learning about groundbreaking research. We left the conference feeling grateful for the opportunity to connect with fellow researchers and motivated to advance our own work. Until next time!
Last, but not least, a big shoutout and THANK YOU to @HimarshaJ for the amazing real-time coverage of #CIKM2024! 🎉🙌 Your updates have been spot-on and truly captured the energy and excitement of the conference. Keep up the awesome work! 👏 #CIKM2024
Acknowledgements
We acknowledge the support of the National Science Foundation (NSF) and the Computer Science Graduate Society (CSGS) at Old Dominion University for providing travel grants, which made our attendance at this conference possible.
-Lesley, Himarsha, and Gangani
Comments
Post a Comment