2024-09-20: Some URLs Are Immortal, Most Are Ephemeral

This post reports preliminary results from the "Not Your Parents' Web" project, a collaboration between Old Dominion University's Web Science and Digital Libraries group, the Internet Archive (IA), and the Filecoin Foundation, with funding provided by the Filecoin Foundation. This work was performed by Kritika Garg (ODU PhD student), Sawood Alam (Internet Archive), Michele Weigle (ODU faculty), Michael Nelson (ODU faculty), and Dietrich Ayala (Filecoin Foundation).
Our goal is to revisit the question, "How long does a webpage last?". The canonical response has been 44, 75, or 100 days, but that was based on research done in the early days of the Web (1996–2003). A study published in May 2024 from the Pew Research Center, "When Online Content Disappears", found that 38% of webpages that existed in 2013 are no longer available on the live Web. A February 2024 study from the SEO company Ahrefs also considered the current status of links from 2013 and found that 66% of those links were dead. The fact that one estimate is nearly double the other illustrates that results are largely dependent upon the source sample. However, neither of these studies investigated if those dead webpages were still available in web archives. We have performed similar analysis, but we start our study from the point of view of web archives. Whereas other studies have sampled URLs from the live web and tracked them forward through time, we sample URLs that have been archived and track them backwards through time.
Dataset
Our dataset consists of archives of 27.3 million URLs from 1996 to 2021, comprising 3.8 billion archived versions, or mementos. This dataset was sampled from the Internet Archive's Wayback Machine in November 2021 and the status of each URL was checked with additional crawls in June and September 2023 (including following redirections). The details of how we compiled the dataset will be described in a forthcoming tech report. We made every effort to ensure that the URLs included in the sample were to actual HTML web pages and not to embedded resources, like images, stylesheets, or JavaScript code. The URLs in our sample contained almost 8M unique domains and 813 unique top-level domains (TLDs).
For several pieces of our analysis, we split the URLs into root URLs and deep links. Root URLs are web pages at the top-level of a website, such as https://www.cnn.com/ or https://www.odu.edu/. We defined deep links as any URL that contained a path element, such as https://www.cnn.com/business/tech or https://www.odu.edu/computer-science.
Our goal was to obtain 1M URLs that were first archived in each of the 25 years between 1996-2021. The figure below (Fig. 1) shows the number of URLs in our dataset first archived in the specified year. We note that because both the size of the Web and the rate of archiving were smaller in the late 1990s, we had to combine URLs first archived between 1996-2000 to reach at least 1M URLs. We also increased our sample by adding the root URLs from some of our deep links, which increased the number of URLs (and proportion of root URLs) first archived before 2003.
 |
| Figure 1. Number of URLs in our dataset (27.3M) by year first archived. |
High-Level Results
1. The Median Lifespan of a URL is 2.3 Years
- For root URLs, the median lifespan is 8.8 years.
- 10% of the root URLs died within 1 year, but 20% lived for over 20 years before dying.
- However, for root URLs that were first archived in the last 10 years of our study (2012-2021), the median lifespan was only 2.6 years, indicating overall shorter lifespans for newer webpages.
- For deep links, the median lifespan is 1.3 years. Over 50% of the deep links died within 1 year, and only 4% lasted for over 10 years before dying.
2. Only 35.3% of the webpages were still alive in 2023
- However, nearly half of the URLs first archived between 1996-2000 were still alive, but this is likely affected by the large proportion of root URLs in our dataset in the early years.
- For those URLs first archived between 2012-2021, about 40% were still alive in 2023, for both root URLs and deep links.
3. The remaining 64.7% are considered dead
- HTTP 4xx (25.1%) - These returned HTTP 4xx status codes, meaning that the webpages were gone or inaccessible, but the webserver was still alive.
- Error (39.6%) - These resulted in a DNS failure, TCP connection timeout, HTTP 5xx status, invalid redirection, or some other error state.
In the chart below (Fig. 2), we show the percentage of alive (2xx) and dead (4xx or error) URLs as of 2023 based on the year the URL was first archived by IA. The only years with more than 50% of the URLs still alive in 2023 were the most recent, 2020 and 2021.
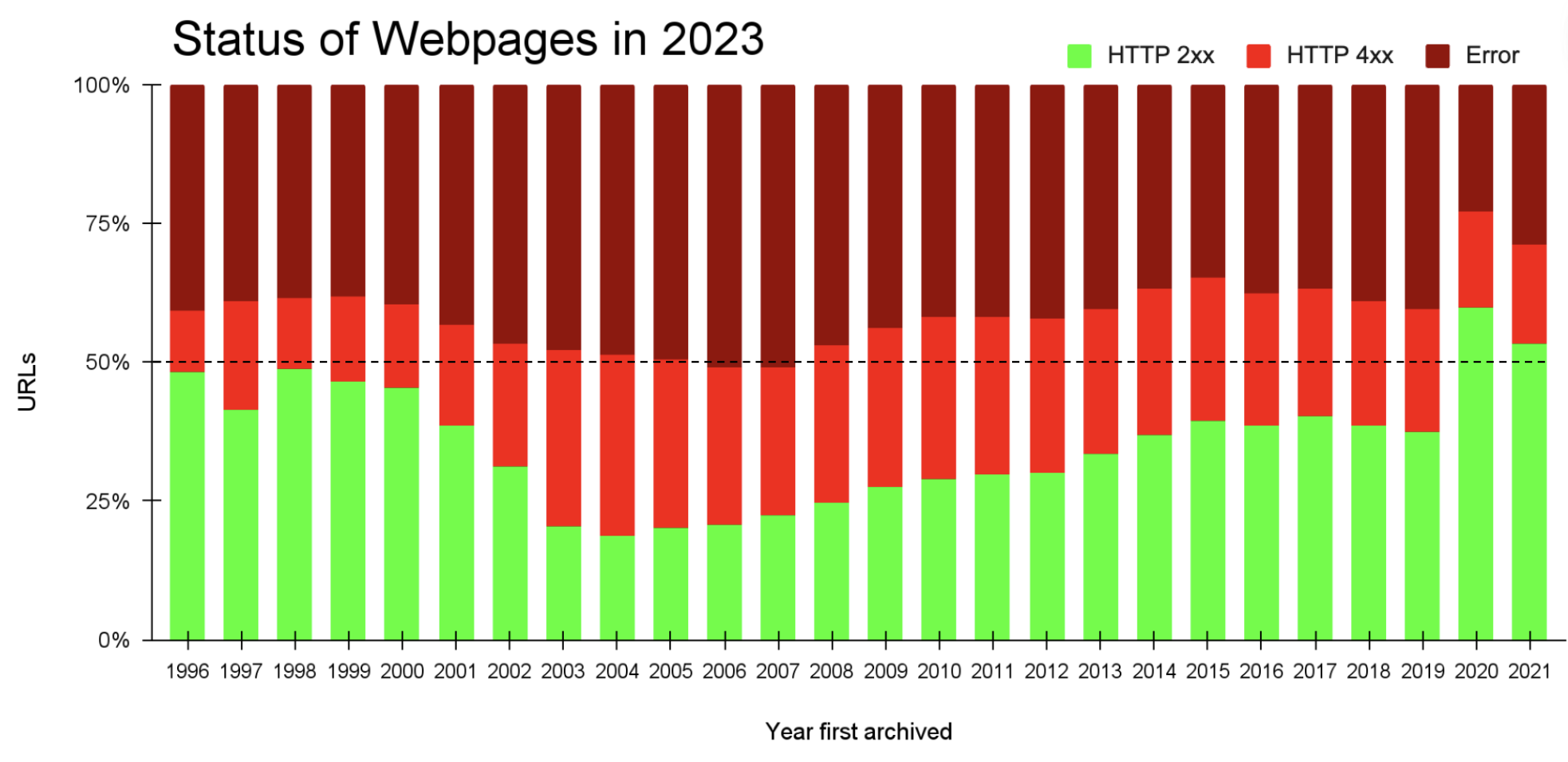 |
| Figure 2. Percentage of URLs in our dataset that were considered alive (green) or dead (red/maroon) in 2023 by the year they were first archived by the Wayback Machine. |
Before continuing with our analysis, we define a set of terms to describe our interpretation of observations of webpages by IA's Wayback Machine:
- archival span - Difference between datetime of the earliest memento, or archived version of a webpage, and the datetime of the latest memento of the webpage. This provides an indication of how long IA was aware of the webpage. The datetime of the earliest memento is an estimate of the creation date of the webpage. The datetime of the latest memento just tells us that IA was still trying to visit the webpage -- it does not tell us that the webpage was still alive at that time. We assume that as long as a webpage is linked from other live webpages, it may still be crawled and assume that if a webpage is no longer being crawled, then it is likely not linked from live webpages.
- lifespan - Difference between the datetime of the earliest HTTP 2xx memento and the datetime of the first error or HTTP 4xx status observed after the last HTTP 2xx memento. This value was only calculated for webpages that were determined to be dead (HTTP 4xx or error status) after the June 2023 crawl. This value represents our upper-bound estimate of how long the webpage was alive, as the webpage could have died at any time between the last HTTP 200 memento and the subsequent memento.
The figure below (Fig. 3) provides an example illustration of the difference between the two time ranges. Each Ti represents a memento. The figure highlights that we calculate lifespan based on the first non-2xx status after the last observed 2xx status. At this point, we know that the URL has died, but we don't know exactly when it died. Also, the archival span can continue to grow even after the URL has died, just as long as IA continues attempting to archive it.
 |
| Figure 3. Illustration of archival span vs. lifespan |
Initial TimeMap Analysis
In early 2022, we used IA's CDX API to collect the TimeMap, or list of mementos, for each of the 27.3M URLs in our sample. The TimeMap for an original URL contains each memento, the datetime of its capture, and the HTTP status code returned when it was archived. Using this information, we were able to analyze the number of mementos held by IA for each URL. This indicates the archival activity of the URL - how many times over the years the Wayback Machine visited the given URL. We found that most URLs had a low memento count, with a median of 7 mementos and less than 1% collecting more than 1000 mementos. However, some URLs had millions of mementos.
As mentioned earlier, for several pieces of the analysis, we split the URLs into root URLs and deep links. We found, not surprisingly, that root URLs tended to collect more mementos than deep links, meaning that the top-level page on a website would be visited more often by the Wayback Machine than deeper webpages.
We analyzed the HTTP status code of each memento, providing a picture of the URL's state at the time it was visited by the Wayback Machine's crawler. We found that over 56% of the original URLs in our 27.3M dataset returned a 200 OK status code each time they were visited. (This does not mean that the content on the webpage did not change, or that the content was "correct", just that the webserver reported that some content was available at the URL. This also does not mean that the webpage was always alive, just that it was alive when the crawler visited.) We also found that 11% of our TimeMaps had no 200 OK status codes.
With the TimeMaps, we can calculate for how long a URL has been visited by the Wayback Machine's crawlers, or its archival span. Because the archival span depends upon when the URL was first archived (e.g., URLs archived in 1996 would have the opportunity for a much higher archival span than URLs first archived in 2016), we separated our archival span analysis by the year each URL was first archived. In addition, we can only calculate archival span on URLs with more than one memento (meaning that it was archived by IA more than once). About 6.4M URLs had only 1 memento, so our archival span calculation is based on the remaining 20.9M URLs. We found that the archival span for root URLs and deep links differed greatly, with root URLs being archived for, on average, 4 times longer than deep links (14 years versus 3 years).
The figures below (Fig. 4) show the median archival span based on year first archived. The top chart shows root URLs and the bottom chart shows deep links. We also show a dotted line indicating the upper bound for each year -- for instance, a URL first archived in 2020 has a maximum archival span of just under 2 years based on its status in late 2021. We can see that the median archival span for root URLs generally tracks the upper bound, meaning that most of these webpages have continued to be visited by the Wayback Machine's crawler. There is more volatility starting in 2003, implying that more newly-created root URLs were disappearing from being linked on the live web since the crawler no longer visited them. The story is vastly different for deep links, however. No matter when the deep link URL was first archived, the median archival span remains below 10 years and is less than 5 years for URLs discovered after 1999.
 |
| Figure 4. Median archival span for root URLs (top) and deeplinks (bottom) based on year first archived |
We found that 83% of our 27.3M URL sample was not crawled at all in 2021. The figure below (Fig. 5) shows our 27.3M URLs and if they were first archived, re-archived, or not archived during each year of our study. The blue section is relatively consistent throughout the years as our aim was to only introduce into our sample about 1M new URLs each year. The green area shows the number of URLs that had been re-crawled in a later year. The gray area indicates the number of URLs in our sample that had previously been archived, but that were not archived again. By 2021, the gray area comprises over 80% of our 27.3M sample.
 |
| Figure 5. Status of the repeated crawling of the 27.3M URLs. We introduced ~1M URLs each year. |
However, just because a URL had not been crawled in several years does not mean that it is no longer alive. So we wanted to crawl each of our URLs again to evaluate their current status. Crawling 27.3M URLs is not a trivial task and it took until September 2023 to obtain reliable data for an updated crawl. These crawls were done at the Internet Archive, so all of the mementos from our 2023 crawls are available in the Wayback Machine.
2023 Crawls
In our June 2023 crawl, we found that only 15% of the original 27.3M URLs were still alive (returning HTTP 2xx status codes), 45% were considered dead (including HTTP 4xx status codes and DNS failures), and 40% were redirecting to another URL (HTTP 3xx status codes). We followed the redirections in a separate crawl in September 2023 and report on those in the "Redirecting" section below.
The chart below (Fig. 6) shows the percentage of live (green, 2xx), redirecting (yellow, 3xx) and dead (maroon/red, 4xx/Err) URLs found in June 2023 based on the year that URL was first archived. The high percentages of redirecting and dead URLs throughout the sample points to the volatility of webpages.
 |
| Figure 6. Percentage of live (green), redirecting (yellow), and dead (maroon/read) URLs found in June 2023 based on the year the URL was first archived. |
For the 15M URLs from our June 2023 crawl that were non-redirecting, we also looked at the relationship between the URL's status (alive or dead) and the number of years since its last archived HTTP 200 response. The chart below (Fig. 7) shows that the percentage of live URLs decreases with the time since its last "200 OK" memento. If a URL has not been archived successfully for many years, most likely it is no longer available on the live web.
 |
| Figure 7. Percentage of live vs. dead URLs based on the number of years since the URL was last archived. |
Below, we report on further analysis based on each of the three conditions: dead, redirecting, or alive.
URLs Die at Different Rates
We found that 45% of our original 27.3M URLs were no longer available on the live web in June 2023. Of the original 7M unique domains, 36% experienced DNS failures, meaning that those domains no longer exist. This impacted 22% of our 27.3M URLs.
Once a URL has died, we can estimate its lifespan. For many URLs, we are not able to calculate the exact lifespan because we do not have regular observations of their status. There were some URLs that had not been visited by IA for many years before our June 2023 crawl. We can know they were dead in June 2023, but we do not know when they actually died.
Before further analysis, we removed all URLs for which there was only 1 memento (6.4M) or which never returned a 2xx HTTP status code to IA's crawler (2.3M). This left us with 7.4M dead URLs. From this set, we separated the URLs based on if they were root webpages or deep links. As expected, we found that root webpages had longer lifespan than deep links. We show the empirical CDFs of the lifespan of these URLs below (Fig. 8 and Fig. 9).
 |
| Figure 8. Lifespan of the 7.4M URLs that were dead in 2023. |
Overall, we found that over 60% of the 7.4M dead URLs died within 5 years of their first archival time and that the median lifespan of a URL was 2.3 years, meaning that half of the URLs died within 2.3 years of first being archived and half lived longer than 2.3 years. As with archival span, we found the lifespans of root webpages and deep links greatly differed.
 |
| Figure 9. Lifespan of the dead URLs split by if they were root URLs or deeplinks. |
Nearly 50% of the 2.6M root URLs persisted for over a decade, while only 10% died within a year of being first archived, with a median lifespan of 8.8 years. Deep links exhibit the opposite behavior, as almost half of the 4.8M deep link URLs were dead within a year of being first archived and only 4% lasted for over a decade, with a median lifespan of only 1.3 years.
For these dead webpages, we calculated their survivability, based on the Kaplan-Meier estimator and found that overall there was about a 50% probability of a webpage surviving for longer than 2 years (Fig. 10). As with the lifespan, we observed dramatic differences between root webpages and deep links. For root webpages, the 50% survivability mark, or half-life, was at 9 years, and for deep links, it was only 1 year.
 |
| Figure 10. Survival curve of the 7.4M dead URLs, split by root URL or deeplink. |
We will be continuing our analysis of these dead URLs to see if there are characteristics of a URL that could be predictive of its lifespan, such as path depth or "attractiveness" of its domain or path (for deep links).
Redirecting
In September 2023, we re-crawled the 11.7M URLs that had reported redirection in June 2023, following up to 10 redirects per URL. Our findings revealed that 744K URLs were no longer redirecting. Among the 11M URLs still redirecting, we observed that approximately 50% terminated in a live webpage (2xx status), 50% ended in an error status, and 0.06% continued redirecting beyond 10 times without termination. During this process, we could not determine the terminating status for 13.22% of the 11M URLs due to invalid location HTTP response headers or non-HTTP redirects (e.g., those induced by JavaScript or HTML meta refresh directives).
We categorized 9.5M redirects that did terminate into canonicalized and non-canonicalized based on the terminating URL. Canonicalized redirects are those that essentially are the result of a webserver re-configuration, such as http:// to https:// or google.com to www.google.com. These redirect URL variations to a single, canonicalized URL and generally would map to the same TimeMap in the Wayback Machine. These are redirections that end users likely do not even notice. We categorized over half (6M) of our 9.5M redirecting URLs as canonicalized, which matches the analysis from a previous study we performed in 2017.
The 3.5M non-canonicalized URLs represent instances where the original URL is no longer alive, but the webserver indicates that the content may be available elsewhere. It is important to note that these 3.5M URLs could be counted as dead even if they ultimately resolve to a HTTP 2xx status because the URL itself is no longer returning an HTTP 2xx status. This highlights one of the complications with trying to determine when a webpage has died -- should we be more concerned about the original URL no longer being alive or the content?
We observed several types of non-canonicalized redirects, as shown in the Sankey diagram below (Fig. 11), with the most common being a redirection to a URL with a different hostname. We performed additional analysis on these non-canonicalized redirects, including identifying common sinks (URLs that received many redirects) and investigating path depth change between the original URL and the final terminating URL. Many times requesting a deep link that is no longer available will result in a redirection to the domain's top-level webpage, such as http://alumnifriends.mines.edu/alumni/career/job_listings/0703-012.htm redirecting to https://www.mines.edu.
 |
| Figure 11. Types of non-canonicalized redirections |
When we followed the 9.5M terminating redirects, we found that 5.4M terminated in a live webpage (2xx status). We further investigated those URLs that were sinks (where multiple webpages in our dataset redirected to). Some of these sinks were obvious e-commerce farms (such as https://pharm-discount.net/?aff=1023/), some were to login pages (such as https://twitter.com/login), and others were to top-level websites (such as http://www.bing.com/, https://www.usatoday.com/, and http://www.google.com/). However, one sink that we found in the top 5 in terms of source URLs (489) and top 10 in terms of source domains (82) was notable -- https://www.youtube.com/watch?v=oHg5SJYRHA0, a video with almost 100M views. (See https://en.wikipedia.org/wiki/Rickrolling. The official video at https://www.youtube.com/watch?v=dQw4w9WgXcQ has over 1.5B views.)
Alive
Our analysis of the remaining live webpages is ongoing. We are analyzing these to determine how many are parked pages or soft 404s, which would indicate webpages that are not generally useful. We are also analyzing these live webpages for content drift, because many pages may still technically be alive, but their content may be so different than when the page was originally archived that it could be considered an entirely different webpage.
Summary
Our analysis of this data is ongoing, but we have reported preliminary findings from our study of the mementos of 27.3M URLs in our sample that were first archived by the Internet Archive's Wayback Machine in its first 25 years of operation (1996-2021). By late 2021, 45% of our sampled URLs had died and for these URLs, we found a median lifespan of 2.3 years, with root URLs exhibiting a much longer lifespan (almost 9 years) than deep links (just over 1 year). By late 2023, only 35.3% of the original URLs were still alive. For newer URLs (first archived between 2012-2021), 60% had died by late 2023. Newer root URLs had a median lifespan of only 2.6 years, while newer deep links had a median lifespan of 1 year, similar to those discovered throughout our 25-year study period.
-Michele
(posting on behalf of Kritika, Sawood, Dietrich, and Michael)
Comments
Post a Comment