2024-08-31: Improving LLM Discernibility in Scientific News – A Thesis Journey
In My Process: From the Field to PhD Candidacy

Background
This journey began in December of 2022 when I developed a custom web crawler to download every scientific news article's HTML from ScienceAlert. We extracted valuable information from these HTML such as the title, author, date, category, scientific news text, and more. I managed to collect metadata from 23,346 scientific articles. We discovered that most of ScienceAlert's articles contain links to domains with published research papers in their URLs. Figure 1. illustrates the process flow of the main methodology developed through the study. In the Figure, News Article A represents the ScienceAlert news article, written by a human journalist, while News Article B is the LLM-generated news article.
 |
| Figure 1. Process Flow of Evaluating between Human-Written news and LLM-generated ones |
The Rise of GPT
Traditionally, token-based evaluation metrics are used in NLP to assess the quality of machine-generated text by comparing it with a reference text. These standard automatic evaluation metrics include ROUGE-1, ROUGE-2, ROUGE-L, BLEU, and METEOR. These methods rely on lexical similarity, where the focus is on individual tokens or words rather than large units like sentences or paragraphs. As a result, they fail to capture meaning, especially in complex texts like scientific news. Semantic-based methods like BERTScore and evaluations using LLMs provide more understanding by embedding texts into high-dimensional spaces where semantic similarity is captured.
Since GPT-3.5 was released on November 30th, 2022, many editorial offices have started using it to write news articles. Our work is the first step in discerning the origin of the article. The result implies that we were able to tune large language models (LLMs) to successfully differentiate between human-written news text and AI-generated news text. When we first started evaluating the LLM-generated articles written by GPT, we were instructed to act as a journalist, which we named, Journalist GPT. The articles received much higher scores than the ground truth, the human-written news article from each linked to a research paper abstract. Although scoring can be useful for quick evaluations, we showed in this work that it is not always reliable for comprehensive assessments. Pairwise comparison, by considering the experimental performance of different settings, offers a more accurate and reliable method to evaluate news articles.
Experiments and Results
Throughout the study, we conducted experiments to test three hypotheses:
- Hypothesis 1: The scores generated by GPT are highly correlated with standard evaluation metrics.
- Hypothesis 2: Direct scoring is a reliable method to evaluate and discern human-written and LLM-generated news articles.
- Hypothesis 3: Pairwise comparison provides a more consistent and reliable way of evaluating the quality of text
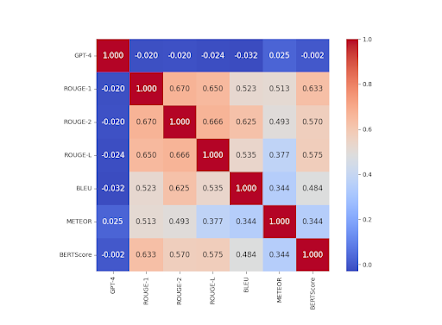 |
| Figure 2. Kendall correlation coefficients testing Hypothesis 1 |
 |
| Figure 3. Correct Term Frequency vs LLM-generated Term Frequency |
Discussion
 |
| Table 1. Guided Few-shot pairwise comparison Performance |
In the GPT-3 paper, OpenAI showed that the performance of LLMs can be improved significantly by providing examples of the model. Our study supports this claim, as shown in the results presented in Table 1. Specifically, the 70 billion parameter LLaMA 3 model beats GPT-4 across all settings. It also shows that open-weight Mistral 7B won direct pairwise comparison and beat GPT-3.5 20B across all settings.
This study revealed a performance comparison between the use of both shots and guides produces better results than either one alone. The findings also emphasize the utility of pairwise comparison methods over direct scoring, when the goal is to distinguish between LLM-generated to human-written news. In the future, we would like to conduct more extensive human studies.
Reflecting on this journey, I realize how transformative it has been. From arriving as a student-athlete to finding my passion in research. This path has not only shaped my academic career but also deepened my relationship with ODU and its people. I'm excited to continue this journey, pushing the boundaries of what's possible in NLP.
The slides can be viewed here:
~Dominik Soós
Comments
Post a Comment