2024-08-07: Tools for Using the Internet Archive's TV News Archive as Research Data
The Internet Archive TV News Archive is a service provided by the Internet Archive that enables users to search across a collection of television news programs. As of May 2024, the TV News Archive provides access to clips from 2.88 million US broadcast shows dating back to 2009 for research and educational purposes. For over a decade, journalists and scholars have used its collections to varying extents in over 2,000 articles and research publications. As illustrated in Figure 1, the TV News Archive data available to the public includes video clips of broadcasts and closed captions. The Internet Archive also provides access to chyrons (the "lower thirds" of TV screens displaying breaking news and highlights).
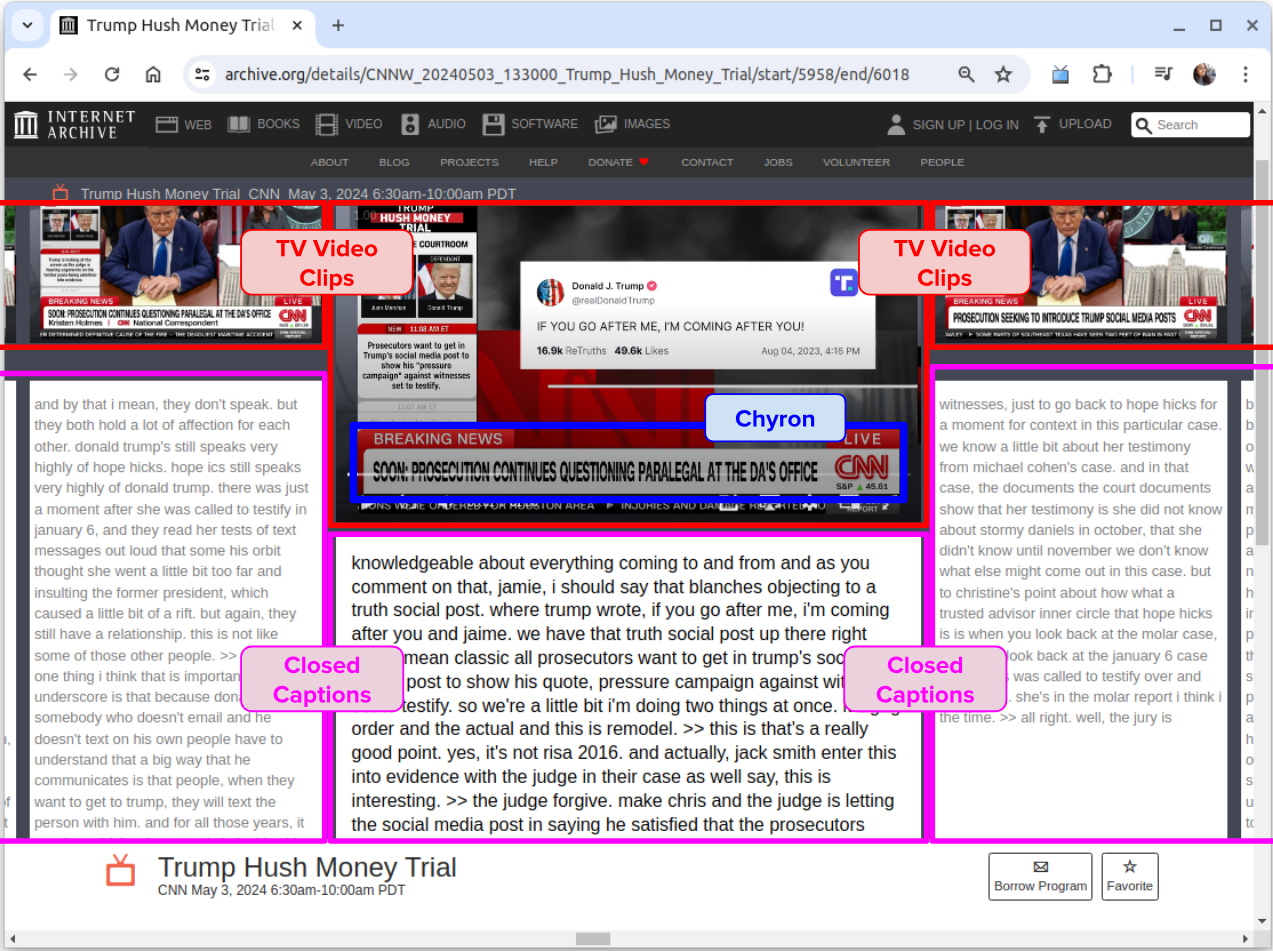
Figure 1: Video clip from the TV News Archive displaying closed captions and a chyron (lower thirds) providing breaking news. Link to the video clip: https://archive.org/details/CNNW_20240503_133000_Trump_Hush_Money_Trial/start/5958/end/6018
Several tools have emerged to leverage the vast repository of broadcast television news archived by the Internet Archive, both independently and in collaboration with Kaalev Leetaru, founder of the GDELT project. These tools employ various technologies and methodologies to provide users with valuable insights into the content, trends, and dynamics of television news coverage.
Introducing Existing Tools Built on Top of TV News Archive Data
In this blog post, we will summarize some of the tools built on top of the Internet Archive’s TV News Archive that can be used to analyze and visualize its content, based on our experiences.
Third Eye (By the Internet Archive)
Third Eye service, developed by the Internet Archive, is designed by applying optical character recognition (OCR) to extract text from the "lower thirds" of TV screens displaying breaking news, highlights, and program promotions like social media engagement prompts.
For instance, to access chyrons from May 3, 2024 (chyron on the example in Figure 1), users can either select the date using the date picker at the Third Eye website or by using the URL:
https://archive.org/services/third-eye.php?dayL={startdate_mm/dd/yyyy}&dayR={enddate_mm/dd/yyyy}. (ex: https://archive.org/services/third-eye.php?dayL=05/03/2024&dayR=05/03/2024).
An excerpt of chyron data retrieved using the example URL is shown in Figure 2. The response includes details such as date, time, channel, duration, unique identifiers for news shows, and the chyron text.
$ curl -s "https://archive.org/services/third-eye.php?dayL=05/03/2024&dayR=05/03/2024" | grep "CNNW_20240503_133000_Trump_Hush_Money_Trial/start/" | head -74 | tail -2
date_time_(UTC) channel duration https://archive.org/details/ text
2024-05-03 15:09:00 CNNW 34 CNNW_20240503_133000_Trump_Hush_Money_Trial/start/5940 PROSECUTION SEEKING TO INTRODUCE TRUMP SOCIAL MEDIA POSTS\nSOON: PROSECUTION CONTINUES QUESTIONING PARALEGAL AT THE DA'S QFFICE
2024-05-03 15:10:00 CNNW 50 CNNW_20240503_133000_Trump_Hush_Money_Trial/start/6000 SOON: PROSECUTION CONTINUES QUESTIONING PARALEGAL AT THE DA'S QFFICE\nPROSECUTION SEEKING TO INTRODUCE TRUMP SOCIAL MEDIA POSTS. . Jamie Gangel @W Special Correspondent
Figure 2: A snippet of chyron data from May 3, 2024 (https://archive.org/services/third-eye.php?dayL=05/03/2024&dayR=05/03/2024) using Third Eye. The unique identifier for the news show is highlighted in blue and the chyron text shown in Figure 1 is highlighted in red.
The unique identifier for news shows is a simple string that combines channel name, show name, time, and date. We can use this identifier to access the clip in the TV News Archive. For example, the identifier CNNW_20240503_133000_Trump_Hush_Money_Trial/start/5940 can be used to build the URL for the TV News Archive by prepending https://archive.org/details to the identifier. (ex: https://archive.org/details/CNNW_20240503_133000_Trump_Hush_Money_Trial/start/5940/).
GDELT Television Explorer (by GDELT 2.0 TV API)
GDELT Television Explorer is a tool developed by the GDELT Project. This service allows you to rapidly create a visual dashboard that summarizes the broadcast television news coverage of your search using data from the Internet Archive's TV News Archive. You can select “Television News (Internet Archive)” as the dataset on the first drop down which would take you to: https://api.gdeltproject.org/api/v2/summary/summary?d=iatv.
You can enter your search keywords to run the search on the raw closed captions that are available through the Internet Archive's TV News Archive. With the provided options, users can opt for their preferred dashboard type, whether it is a single search term or the comparison of up to four search terms for easy juxtaposition. They can also choose specific displays to include for analyzing data, including streamgraph and heatmap volume timelines for pinpointing trends, online news volume timelines for comparing television and online coverage, Google Trends timelines for tracking search interest, station charts for comparing attention across stations, show charts for identifying influential shows, word clouds for commonly associated terms, and top matching clips for viewing relevant TV news video clips. A few of the output charts including word cloud and top clips for the keyword search "Trump Hush Money Trial" on CNN, FOXNEWS, OR MSNBC is shown on Figure 2. Users are allowed to export the charts and word clouds in different formats, such as CSV, JSON, embed code, URL link, or image file. Google Trends timelines are connected to the official Google Trends website, where users can download the chart. Additionally, they have the option to save the top clips as a URL link, CSV file, JSON file, RSS feed, JSONFeed, or embed code.
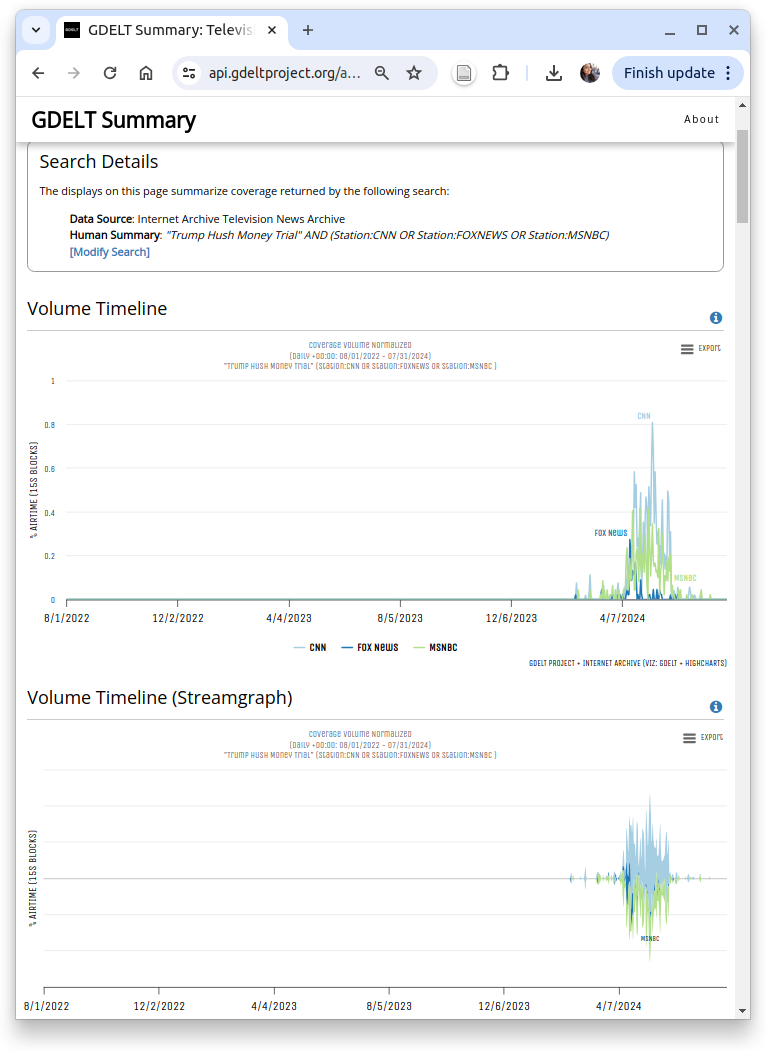
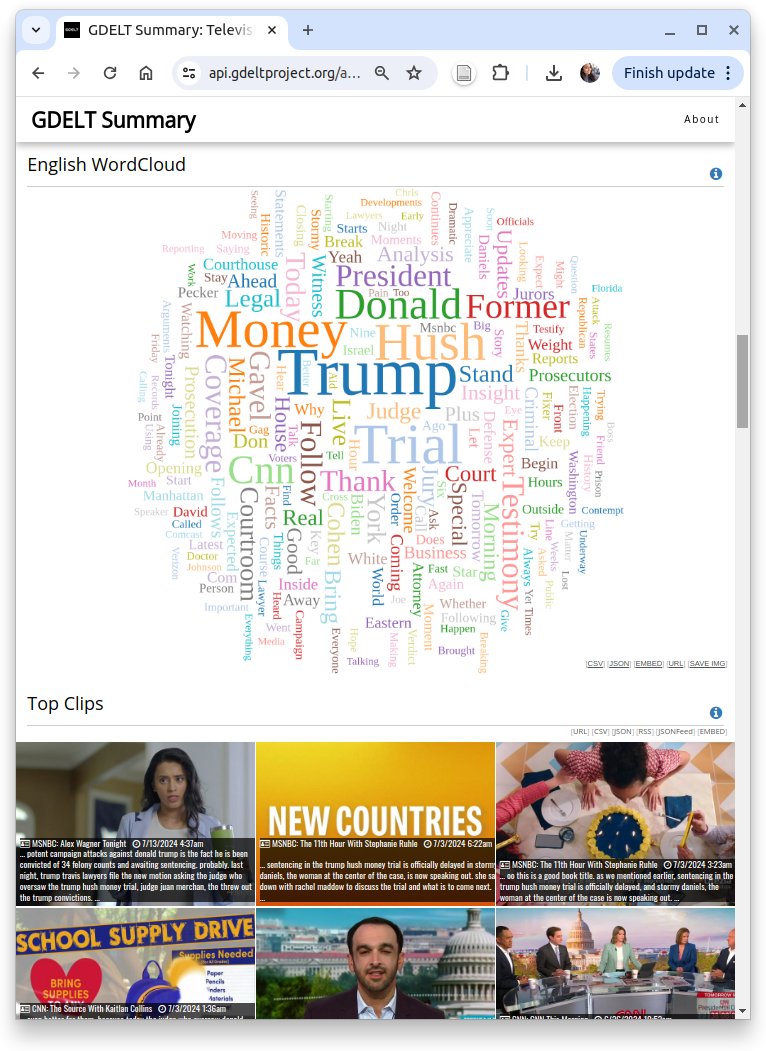
Figure 2: Screenshot of the visual dashboard displaying output charts (left), including a word cloud and top clips (right), for the keyword search "Trump Hush Money Trial" on CNN, FOXNEWS, and MSNBC.
Older versions of the Television Explorer broke down broadcasts into individual sentences and counted the number of matching sentences. However, as Kalev Leetaru highlighted in "The New Television Explorer Launches!" blogpost, users faced difficulties integrating these results with other time-based measures. The updated Television Explorer divides each broadcast into sequential 15-second clips and displays the percentage of clips that match your search, which is directly proportional to airtime.
GDELT AI Television Explorer (by GDELT 2.0 TV API, Google's Cloud Video API, & Google's Cloud Natural Language API)
GDELT AI Television Explorer is a tool developed by the GDELT Project. This tool enables the users to employ cutting-edge computer vision and natural language processing techniques for visually searching over a decade of archived broadcast television news from the Internet Archive's Television News Archive. You can select “Television News - AI (Internet Archive)” as the dataset on the first drop down which would take you to: https://api.gdeltproject.org/api/v2/summary/summary?d=iatvai.
Unlike Television Explorer, there is only one dashboard option available for the GDELT AI Television Explorer for now (single search). The Television AI Explorer offers several advanced features beyond those of the Television Explorer. It allows searches using visual entities, recognizing around 12,000 distinct objects and activities via Google's Cloud Video API. It also analyzes station-provided human-transcribed closed captions through Google's Cloud Natural Language API to identify underlying concepts and topics. Additionally, it uses Automated Speech Recognition (ASR) to create more complete and accurate machine-generated transcripts, provides keyword searches of station-provided captions, and transcribes on-screen text using OCR for keyword searching.
Similar to the Television Explorer users can select from a variety of displays to summarize their results. Options include volume timelines presented as streamgraphs or heatmaps, station and show charts to gauge coverage, and word clouds showcasing key spoken words. These word clouds include ASR WordCloud for machine-generated spoken word transcripts, Caption WordCloud for human-produced spoken word transcripts, Caption NLP WordCloud for topics analyzed by Google's Natural Language API, OCR WordCloud for on screen text, and Visual WordCloud for visual entities identified by Google's Video API. Users can export these charts and word clouds in different formats: CSV, JSON, embed code, URL link, or as an image file. Additionally, users can explore the top matching seconds of airtime, providing a concise overview of relevant content. You have the option to save the top clips as a URL link, CSV file, JSON file, RSS feed, JSONFeed, or as an embed code.
For instance, if we want to search for news coverage about missing aircraft, we could look for the visual object 'aircraft' and the term 'missing' in captions and on-screen text. The visual dashboard, as shown in Figure 3, illustrates this input search for uncovering news episodes about missing aircraft. This approach can be adapted with different combinations to achieve the desired results. Figure 4 shows the visual dashboard with some output charts on the left, including a word cloud of visual entities and top clips on the right.
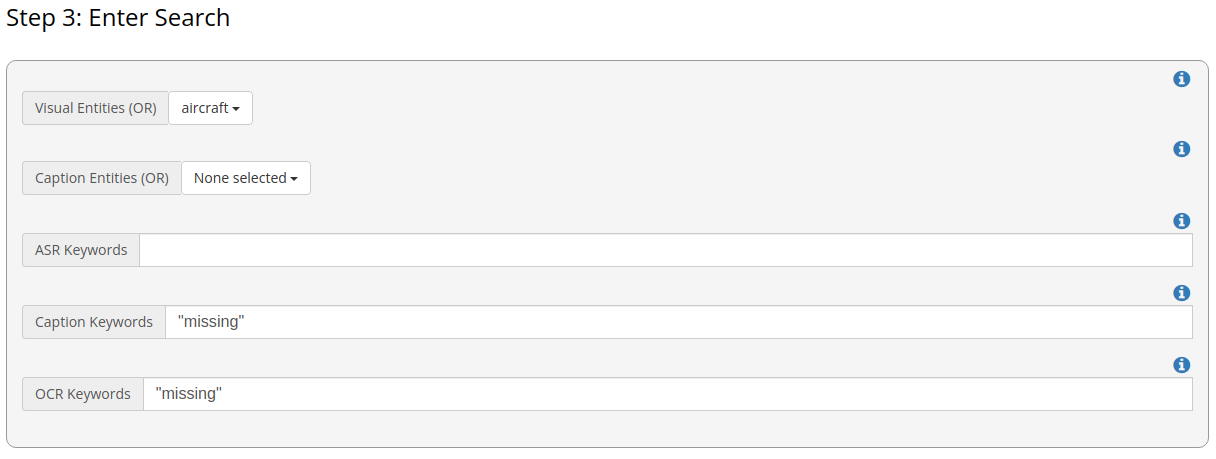
Figure 3: Screenshot of the visual dashboard showing the input search used to uncover news episodes about missing aircraft.
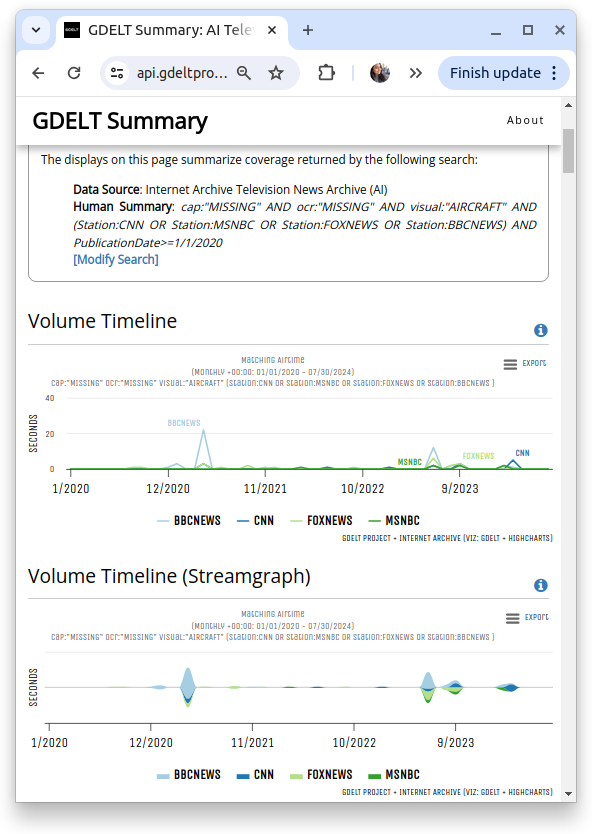
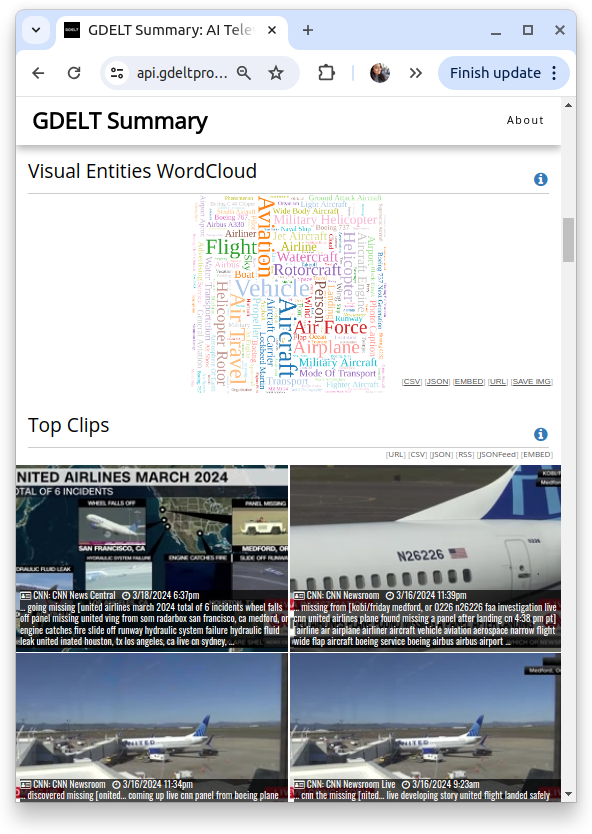
Figure 4: Screenshot of the visual dashboard displaying some output charts (left), including a visual entities word cloud and top clips (right), for the visual object search of 'aircraft' and the term 'missing' in captions and on-screen text.
GDELT TV News Visual Explorer
GDELT TV News Visual Explorer is a tool developed by the GDELT Project. Despite extensive keyword searches through closed captioning, speech recognition transcripts, and OCR'd onscreen text via Television Explorer and Television AI Explorer as discussed earlier, the visual narrative unique to television news sets it apart from other media forms. GDELT TV News Visual Explorer offers an interface that can access broadcasts in the form of thumbnails (one every 4 seconds) for rapid scanning.
For instance, to access the “Trump Hush Money Trial” on CNN from May 3rd, 2024 (example in Figure 1), users can first select the date using the date picker and then select the channel “CNN” under “United States” and select the show title “May 3, 2024 6:30am-10:00am PDT: Trump Hush Money Trial”. Figure 5 shows how the episode is displayed as a grid of thumbnail frames, one every 4 seconds (left) as well as automatic transcription (right) for each broadcast.
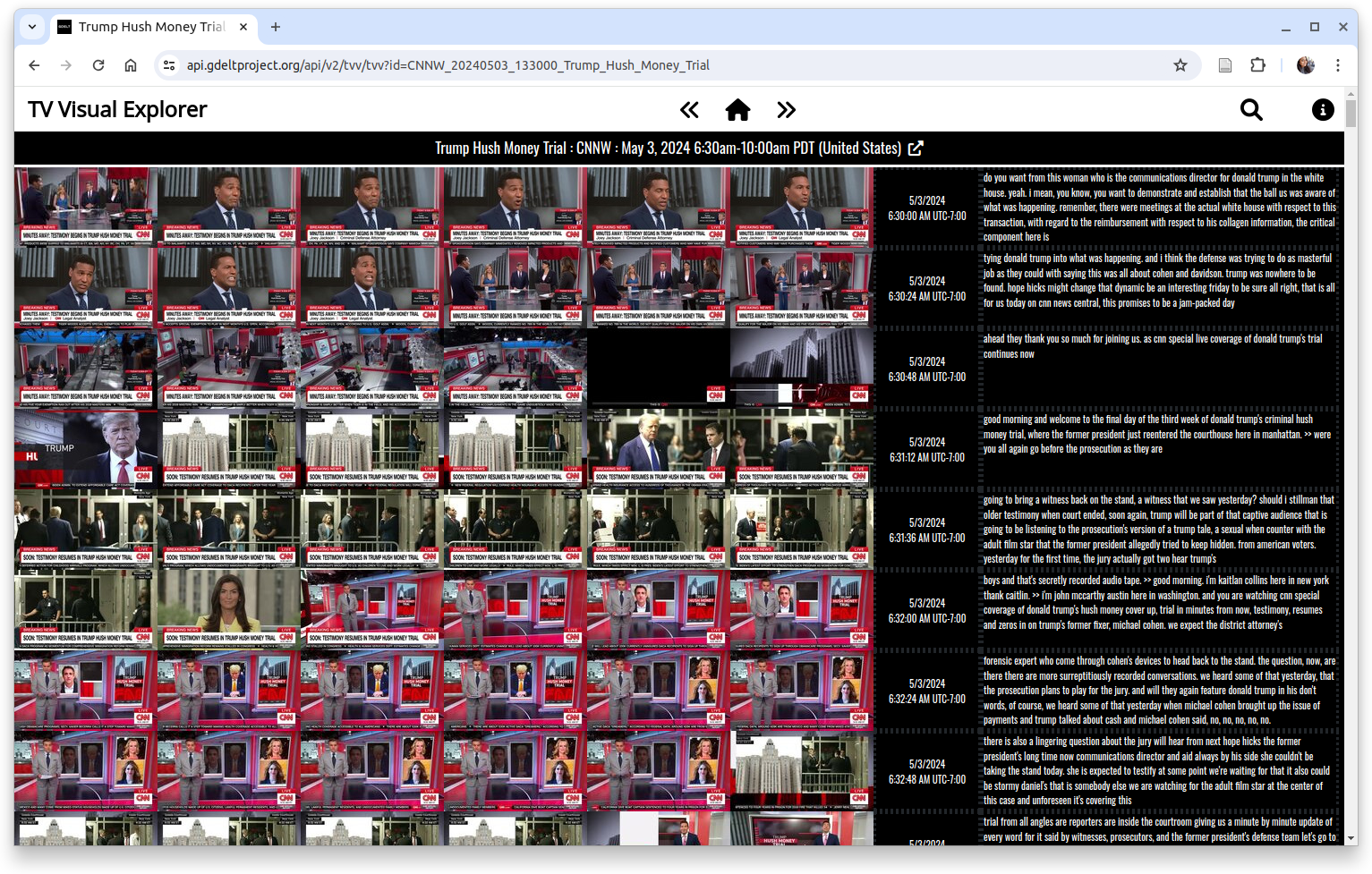
Figure 5: Displaying an episode as a grid of thumbnail frames (one every 4 seconds) which facilitates rapid scanning through the broadcast to help identify specific segments of interest.
Users have the option to download the underlying thumbnails as a ZIP file, facilitating further computational analysis such as OCR.
For this we can use the URL:
https://storage.googleapis.com/data.gdeltproject.org/gdeltv3/iatv/visualexplorer/{unique identifier for news show}.zip
For example:
(obtained by using “CNNW_20240503_133000_Trump_Hush_Money_Trial” as the identifier)
This link downloads a ZIP file of the full resolution versions of the thumbnails in JPEG seen on the page for the “Trump Hush Money Trial” episode on CNN. The thumbnails are numbered sequentially in the order they appear in the thumbnail grid on the TV News Visual Explorer.
Television Emotions Explorer
Television Emotions Explorer is a tool developed by the GDELT Project. This tool analyzes the way television news represents domestic and global stories, offering a broad overview of the emotional tones present in American TV daily news coverage by processing the closed captions of the selected channel/channels.
The captions have been analyzed to assess the emotional and thematic elements of each broadcast using the GDELT Global Content Analysis Measures (GCAM) emotion pipeline, which evaluates nearly 2,500 discrete emotions (a comprehensive system beyond just positive/negative tone assessments). Users can select the “Television Network” and the “Emotion” to generate visualizations by clicking the “Filter Mentions” button.
For example, to assess the "CRIME (Lexicoder Topic Dictionaries)" (one of the CRIME related themes available on the dropdown list) emotion over time on the MSNBC channel at a macro level, select “Television Network” as “MSNBC” and the emotion “CRIME (Lexicoder Topic Dictionaries)”.
This will generate the URL:
To export the raw timeline data in CSV format, append "&output=csv" to the URL: https://television.gdeltproject.org/cgi-bin/iatv_livetvemotions/iatv_livetvemotions?filter_network=MSNBCW&filter_emotion=c4.13&output=csv
However, one limitation of the tool is that it only uses data from the period spanning July 2009 to May 2017 and has not been updated since then.
Note:
A previous version of the tool, “Emotional Explorer: Explore the Emotion of American Television News” which uses data from June 2010 to early September 2014, is also available but has not been updated since then.
Political TV Ad Archive
By using the audio fingerprinting technology, the Political TV Ad Archive identified airings of political ads during the 2016 elections. Internet Archive used “The Duplitron 5000”, a RESTful API designed to identify and manage repeated audio within a larger corpus. It compares incoming media (audio or video) with existing content, categorizing sections based on the comparison result (using ffmpeg and audfprint). Unfortunately, this service has been unavailable for several years, but omitting it would feel like an oversight, so I have decided to mention it here briefly. Figure 6 displays the final archived version of the page (memento) from November 19, 2023, archived by the Internet Archive.
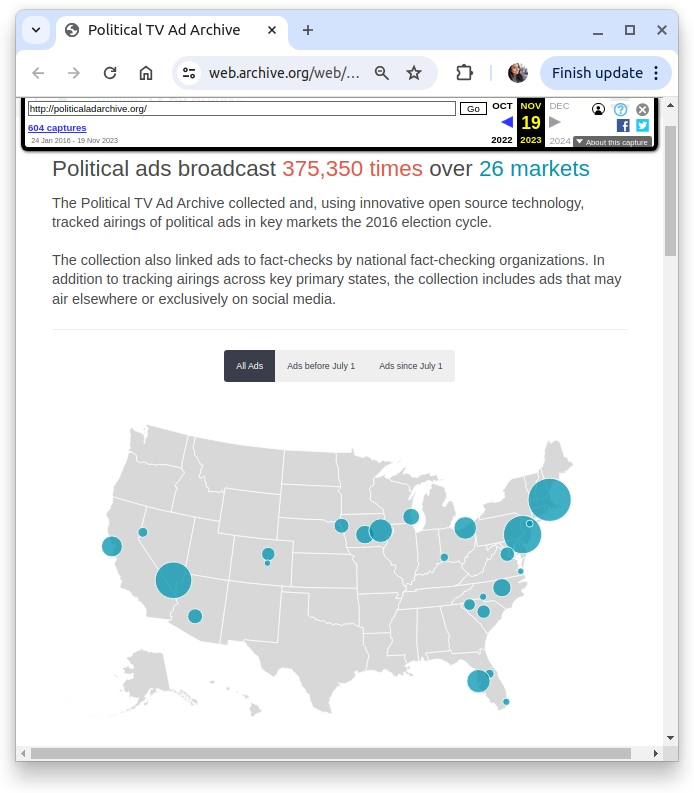
Figure 6: Final archived version of the Political TV Ad Archive (memento) from November 19, 2023, as captured by the Internet Archive. URL of the memento: https://web.archive.org/web/20231119103006/http://politicaladarchive.org/
Conclusion
In conclusion, the Internet Archive's TV News Archive stands as a significant resource for researchers and journalists, offering access to a vast collection of television news programs. Various tools have been developed to look into the TV News Archive data.
The Third Eye service extracts text from chyrons which display breaking news and highlights.
The GDELT Television Explorer offers comprehensive analysis and visualization of TV news coverage, aiding researchers in understanding media dynamics.
By leveraging cutting-edge technologies in computer vision and natural language processing, the GDELT AI Television Explorer offers a more sophisticated approach to analyzing archived TV news content (a significant advancement from its predecessor, the GDELT Television Explorer).
GDELT TV News Visual Explorer offers a distinct function by furnishing an interface for quickly scanning broadcasted content using thumbnail frames.
Television Emotions Explorer analyzes emotional tones in American TV news coverage by processing closed captions, although its data is limited to the period from July 2009 to May 2017.
The Political TV Ad Archive used audio fingerprinting technology to identify and catalog political ads aired during the 2016 elections, but this service is currently unavailable.
As technology advances and these tools undergo continuous improvement, the chance to dig deeper into vast amounts of TV news data gets increasingly stimulating and attainable. I hope this blog post encourages more researchers and journalists to leverage these tools to uncover fresh insights and gain a deeper understanding of television news as a valuable data source. Himarsha Jayanetti (@HimarshaJ)
Comments
Post a Comment