
Brenda Reyes Ayala, "Gone, Gone, but Not Really, and Gone, But Not Forgotten: A Typology of Website Recoverability", 13th Temporal Web Analytics Workshop (TempWeb '23) in Companion Proceedings of the Web Conference 2023 (WWW '23), Apr. 2023 (Texas, USA), pp. 1208-1213, doi: 10.1145/3543873.3587671.
We often come across web pages where we see ‘Error 404’, which means the server is unable to retrieve the requested page. Moreover, we also encounter web pages where the content significantly changes through time, moving away from the original referenced content. Such disappearance of web resources is a common phenomenon on the web. Web resources can disappear or change for a variety of reasons, such as server crashes, expired domains, hacking, creators abandoning websites and moving web resources to a different location.
Disappearance of resources from the web is broadly termed as reference rot, which has two components - link rot and content drift. Link rot is defined as when the URI of a resource disappears from the web, so there is no way to access the referenced content using that specific URI. Content drift is defined as when the content of a resource for a particular URI changes over time, and as a result, the intended referenced content is no longer accessible using that specific URI. The basic difference between link rot and content drift is that, for link rot, the resource identified by a URI vanishes from the web whereas for content drift, the resource evolves to such an extent that the URI does not refer to the original content. Additionally, for content drift, this depends on the intent of a user. Dereferencing the URI always returns the state of the resource identified by the URI. It is possible that a URI is now used to identify a different resource, but it is also possible that the resource is changing. For instance, there are some type of resources that will always be transient in nature such as daily weather update, stock market price etc. These are some examples which are not necessarily content drift.
Using web archives, such as the Internet Archive's Wayback Machine, is a way to preserve the state of web resources at a particular time. For example, @mattyglesias posted a tweet along with a screenshot of a tweet posted by @DonaldJTrumpJr. Fig. 1 shows that the tweet by @mattyglesias is not currently available on the live web because it was deleted. However, the original tweet by @DonaldJTrumpJr is available on the live web. Searching for the URL of the tweet by @mattyglesias in the Wayback Machine provides an archived version of his deleted tweet (Fig. 2).

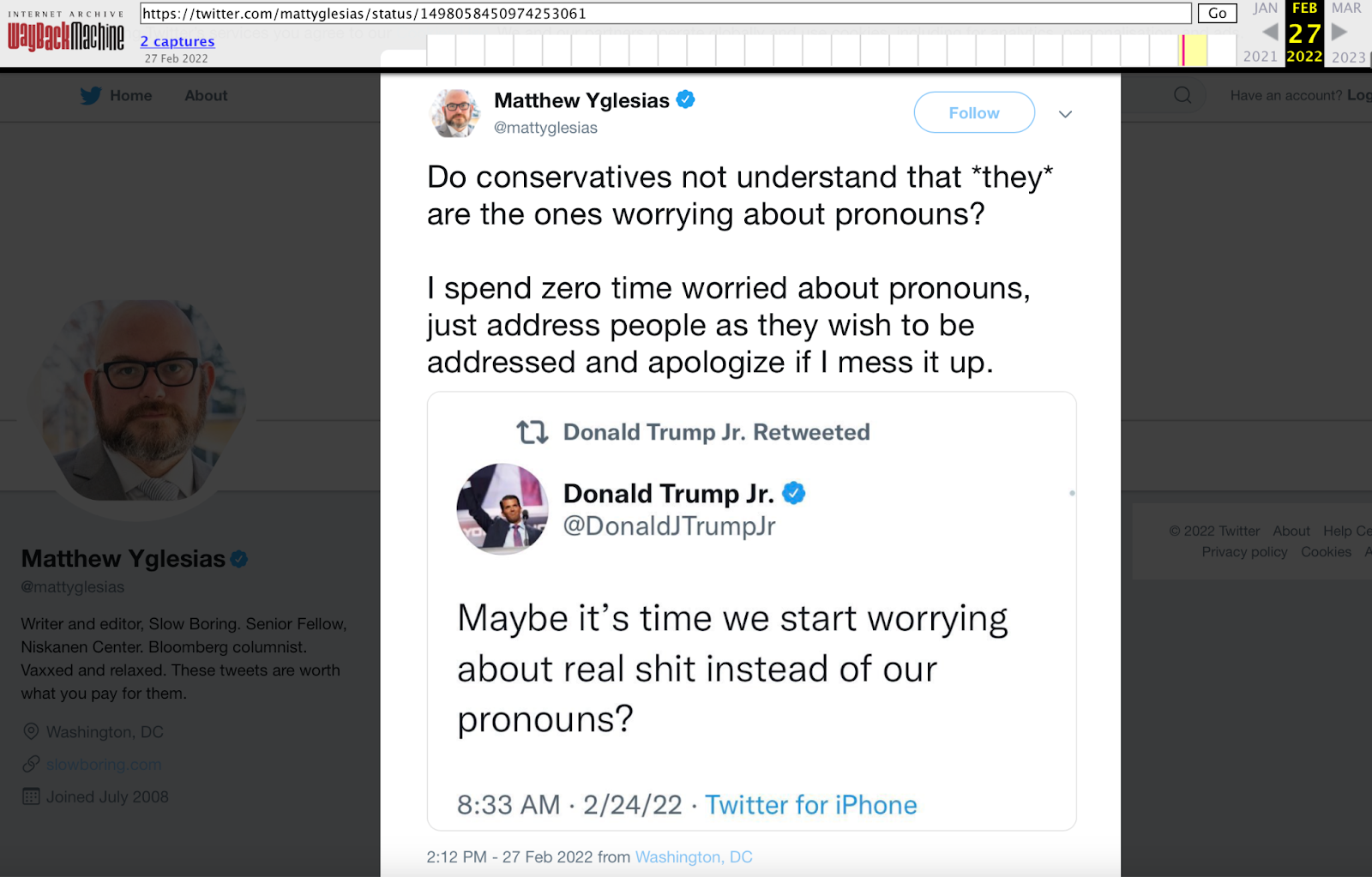
Figure 2. Archived version of the deleted tweet by @mattyglesias.
Moreover, web archives are also useful when a web resource has been affected by content drift. Fig. 3 shows a screenshot of the homepage of the IceCube Neutrino Observatory at the University of Wisconsin. The archived versions of the web page as of May 8, 2009 (left) differs significantly both in terms of content and presentation from that of August 27, 2009 (right). This example demonstrates how dramatically content drift has occurred within a 3-month period.
Figure 3. Images of the archived versions on May 8, 2009 (left) and on August 27, 2009 (right) of the IceCube Neutrino Observatory website’s homepage, Figure 3 from Jones et al.
It is clear that content of live web pages might change over time (i.e., content drift). Again, many web pages might become inaccessible on the live web (i.e., link rot). The above examples demonstrate that for many web resources, their archived counterparts are the only evidence that the resources even existed at all. Hence, web archiving efforts can be helpful to recover such web resources, but the following research questions exist regarding the recoverability of these web pages:
- Can they be recovered at all?
- If so, can they be fully recovered? Or, only in a diminished form?
- How are these recovered web pages different from those that have been permanently lost?
Dr. Brenda Reyes Ayala has explored these issues in her paper “
Gone, Gone, but Not Really, and Gone, But Not Forgotten: A Typology of Website Recoverability” (
13th Temporal Web Analytics Workshop, 2023), in which she performs a qualitative analysis of the recoverability of the web pages on the live web, where the corresponding archived version is used as a baseline standard, or “ground truth”. Here, we provide a summary of her work.
Dr. Reyes Ayala's analysis results in categorizing three degrees of web page recoverability: cannot be recovered at all (with three subtypes), fully recoverable, and partially recoverable. Previous work by
McCown and Nelson also introduced different states of web resource recoverability in the web infrastructure: vulnerable, replicated, endangered, and unrecoverable based on web page availability on the web server and in search engine caches.
Data Collection
The datasets used in this study come from four web archive collections with varying degrees of content drift. The collections were created by the University of Alberta and Library and Archives of Canada (LAC). The scope of these collections is limited to preservation of individual live web pages and their archived versions rather than entire websites. The live web analysis was conducted during 2021. The web collections are:- Idle No More (INM): Web pages related to the Idle No More movement, which is a Canadian political movement concerning environmental issues and rights of indigenous communities. The pages were collected in January 2013.
- Fort McMurray Wildfire 2016 (FMW): Web pages related to the Fort McMurray Wildfire of 2016 in the province of Alberta, Canada. The pages were collected in May 2016.
- Western Canadian Arts (WCA): Web pages related to websites created by filmmakers in Western Canada. The pages were collected in September 2015.
- Government of Canada (GoC): Web pages related to Canadian government websites. The pages were collected in February 2016.
Methods
The author used methods that involve web archives as a baseline to examine content drift of web resources on the live web. She adopted the following methods to determine the varying degrees of content drift in the web archive collections of the dataset:
- Research assistants manually examined each of the live web pages and compared them to their archived versions.
- The author inspected both the content of each live web page and its relevance to the larger collection.
- If a live web page was found to be affected by content drift, the author tried to find the original content on the live web.
A ‘recovered web page’ is defined as a web page that is still present on the live web and the content is similar to its archived version. The author was able to recover a few pages that were thought to have vanished from the live web by searching for the title of the original web page as well as the name of the website on the live web. Once the author was able to recover a significant number of web pages, she further analyzed and compared them to their archived versions to explore whether any repeated patterns exist.
Results
The analysis shows that the web archive collections of three of the datasets were affected by varying degrees of content drift. Using the methods described above, the author was able to achieve a small decrease in the content drift. Table 1 provides an overview of the percentage of content drift of the live web pages with respect to their archived counterparts before and after recovery efforts.
Table 1. Details of web archive collections and content drift, Table 1 from
Reyes Ayala.

Among the four collections, the INM collection had the lowest (8.7%) content drift, whereas the FMW collection had the highest (33.2%). The recovery efforts of the author resulted in a small decrease – difference of 3.4% and 3.7% for the FMW and INM collections, respectively. The GoC collection had the largest difference - an 8.6% decrease. The author was not able to recover any web resources for the WCA collection. The author mainly used human manual intervention and web page titles as retrieval methods for missing web pages.
Some previous works suggest that a website’s title is quite useful for recovering lost web pages.
Reyes Ayala, Du, and Han used cosine similarity scores to compare the titles of a live web page to its archived counterpart for detecting content drift on the live web. Another work by
Klein et al. also compared titles of a live web page and its archived version by using edit distance in order to investigate the discovery performance of missing web pages.
Klein and Nelson further experimented individually and in combination with lexical signatures, web page titles, tags, and link neighborhood lexical signatures to investigate retrieval performance for missing web pages. They also found that titles performed well, either by themselves or in combination with other methods, for the rediscovery of web pages on the live web.
Discussion
Reyes Ayala further establishes the boundaries among the varying degrees of web page recoverability. These are briefly discussed below:
1. Gone: Not recoverable
This category of web pages includes the following three classes:
- Web pages that have completely disappeared from the live web. These web pages return ‘Error 404: Not Found’ when accessed. This means that the content is not found anywhere on the live web page. Fig. 4 shows an example of the homepage of an online retailer website, Kozmo.com, that has recently disappeared from the live web. Thus, the live version of the web page is not accessible anymore.

- Web pages that have disappeared from the live web but the failed URLs are redirected to a website’s homepage, known as a 'soft 404'. Bar-Yoseef et al. have defined 'soft 404' more elaborately. Sometimes when the server is unable to return a web page that has dissapeared from the live web, the server returns a substitute page with an OK code (200) instead of the 'Error 404: Not Found' code. This substitute page can provide a written error indication, can be a redirect to the original domain home page, or can provide something that is totally irrelevant to the original web page. Fig. 5 shows an example for a case of 'soft 404' where the server returns a substitute page providing a written error indication. Fig. 6 shows the headers for this web page that the page is returned with an OK code (200).
- Web pages that appear to be the same with respect to their archived version, but have been affected by content drift. This is known as ‘traditional content drift’. This means that the content of the live web page differs significantly from its archived version. Fig. 3 shows an example of content drift for the IceCube Neutrino Observatory website’s homepage. The content of the web page changed significantly within a 3-month period.
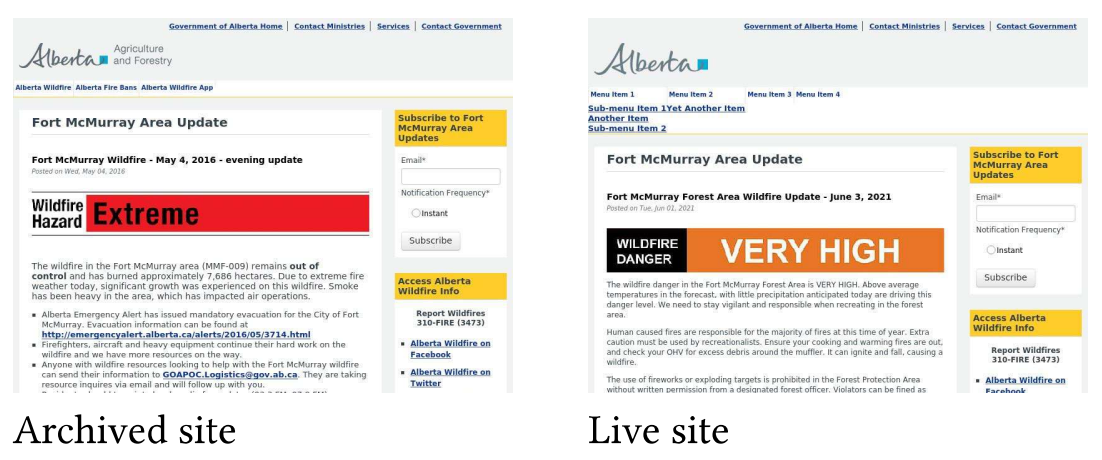
The author also introduced a special case of content drift - live web pages that have been updated continuously since the time its archived version was created. As a result, the archived version can no longer be considered as a representative of the live web page. Fig. 7 shows an example of a special case of content drift - Fort McMurray Area Update from the FMW collection. The original archived website showed the wildfire conditions to be extreme for May 4, 2016 and the live website showed the wildfire conditions to be very high for June 3, 2021. As the website has been updated continuously, the live web page is no longer about the wildfire condition of May 4, 2016. Likewise, there are web pages such as daily weather update, stock market price that are meant to be continually updated. The author here intended to explain how the change of content of such web pages can be a special case of content drift.
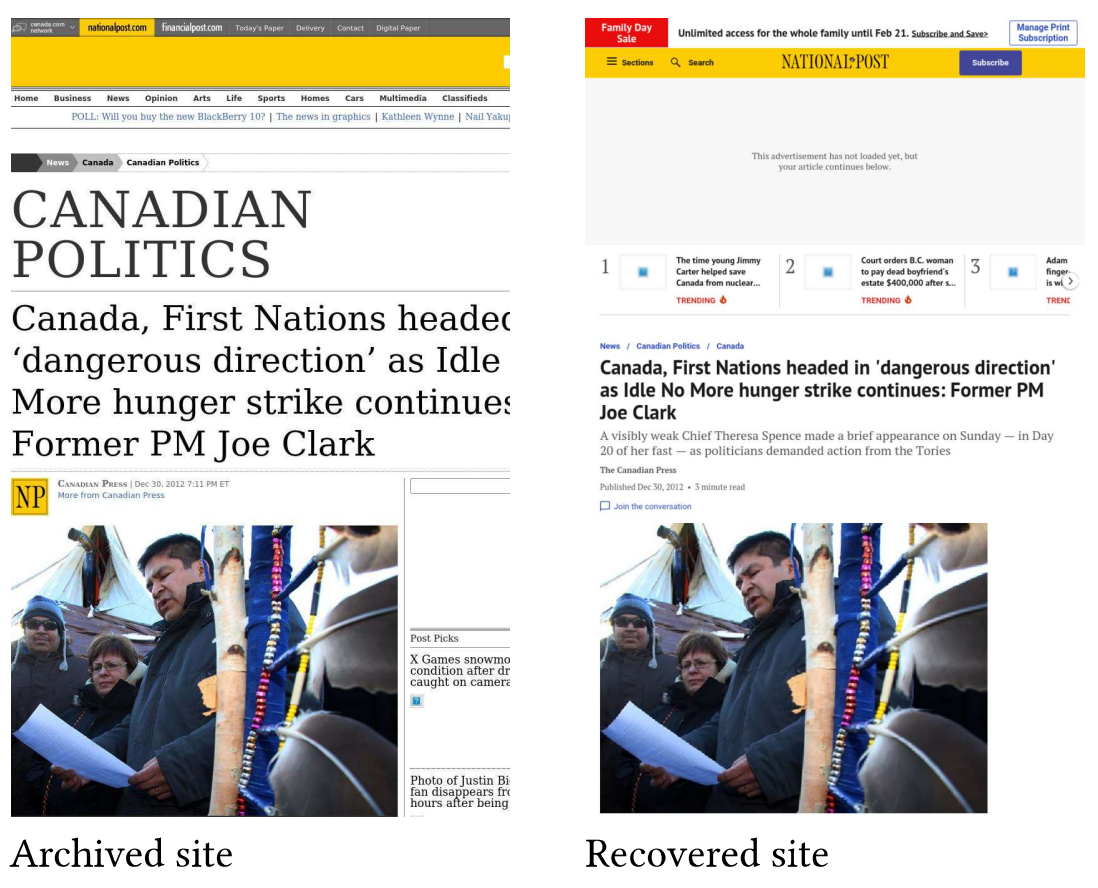
2. Gone, but not really: Recoverable web pages
Web pages which seem to have disappeared from the live web but in reality have been relocated elsewhere belong to this category. Fig. 8 shows an example of a recovered website – a
National Post article from the INM collection where content of the original URI had been moved to a different URI within the same domain.
3. Gone, but not forgotten: Partially recoverable
Web pages that have disappeared from the live web and cannot be recovered but similar or related content can be found in other web pages belong to this category. Fig. 9 shows an example of a partially recovered website, the Government of Canada 2019 census from the GoC collection. The recovered version covers a similar topic but not the exact same content. Fig. 10 shows another example of a partially recovered website, a news article in ‘The Start Phoenix’ from the INM collection. The recovered version covers a shortened version of the original one. For both examples, the original article has disappeared.

Conclusion
Dr. Brenda Reyes Ayala used web page titles to recover pages where the live web page no longer matched the archived version. The outcomes of her analysis showed that using web archives as a baseline standard and web page titles as recovery method, she was able to achieve a small decrease in content drift. Her analysis resulted in identifying three categories of lost web pages. These are:
- Not Recoverable - web pages that have completely disappeared from the live web.
- Fully Recoverable - web pages that seem to have disappeared from the live web but can be found elsewhere on the live web.
- Partially Recoverable - web pages that have disappeared from the live web and cannot be recovered but related content can be found on the live web.
Previous works also showed that web page titles are quite efficient to rediscover URLs on the live web. Such real-time methods like using the web page titles can help web archivists or web researchers to rediscover new locations of web resources deemed to be lost.
--- Tarannum Zaki (
@tarannum_zaki)



Comments
Post a Comment