2023-01-02: Survey of Data Interfaces and Archived Data
Data, Data Everywhere
Data
is all around us and comes in many forms. Statistical, descriptive,
discrete, encoded, decoded, geocoded, qualitative, quantitative, quantum
🤯! Wow, there's a lot! Data, often statistical, forms the bedrock for informed decision making within scientific, political, academic, and economic fields to name a few. Public figures and publications
have even gone so far as to coin data as "the new oil". The wellspring of data being generated and mined during the COVID-19 pandemic further espouses this idea of data as oil. During the Coronavirus pandemic we saw an explosion
in interest and data generated from policy makers in government,
scientists across the world, and even citizen scientists using tools such as Folding@Home. The National Institute for Health alone lists 36 different COVID-19 related datasets with a further 28 listed on the World Bank's website.
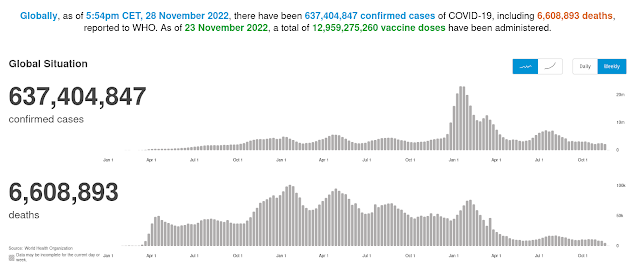 |
| Fig 1. World Health Organization: Coronavirus dashboard |
From China's attempt to enforce a Zero-COVID policy and track more than a billion people, to U.S. presidents tweeting about economic statistics, data plays an important part in our lives and the forces that shape them. While many datasets are private and for proprietary uses, a large amount of data is still available to the public and utilized by public policy makers, government and corporate entities, academic researchers, news agencies, and journalists on a daily basis.
The economy grew at a 2.9% rate last quarter while inflation started to slow and unemployment stayed low.
— President Biden (@POTUS) December 6, 2022
What do these economic statistics really mean for people?
Millions of jobs.
Hundreds of thousands of manufacturing jobs.
Some welcome breathing room for families.
As we will look at in this post, despite our heavy utilization of data, there are many problems that exist in the collection and accessing of data on both the live and archived web. Some of these issues already exist in archived web pages across the web but tend to affect data in specific ways. Others are more exclusive to working with data and help to highlight challenges in archiving non-traditional interactions and experiences on the web.
Frankendata
Thanks, in large part to open source culture, "open data" has been becoming a more and more mainstream idea, even to the public beyond the general development community. Through efforts such as data.gov (check out their page on Open Government),
open data and data transparency is coming a long way. Initiatives like
the Organisation for Economic Co-operation and Development's OURdata Index and Global Data Barometer
(Fig. 2) are helping to track progress on this front but there
is still a long way to go in ensuring data security and accessibility.
In this blog post I will explore some of the pitfalls yet to be
traversed, both on the live and archived web.
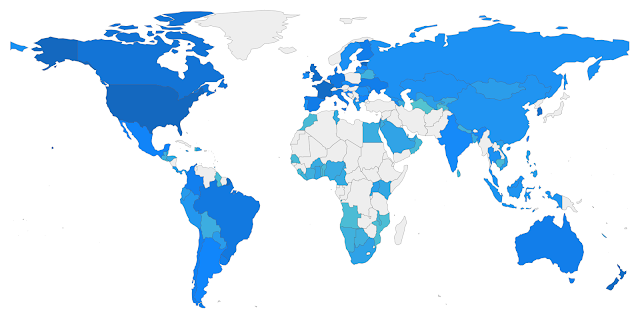 |
| Fig. 2: Global Data Barometer map showing data for available countries |
Abandon all hope, ye who enter here looking for standardized data collection! The OECD has proposed standardized methodology regarding global data collection, but adoption is still actively progressing. Collecting statistical data is a messy, tedious, laborious process, and the output and end result often mimic the input side of things. The European CDC (Fig. 3) offers multiple file types for download but many sites might only offer a single format and this can vary wildly depending on the site and type of data. The content within a dataset itself is shaped by the intentions of the agency collecting the data, the method and design of the survey, the availability of participants, and their willingness to provide accurate information. For instance, the CIA World Factbook does not follow standardized ISO-3166 two- or three-digit country codes traditional of most datasets organized around geopolitical countries, instead using their own country encodings which also include regions and territories not included in most standard datasets. Data sparsity becomes a real issue once we get into any large scale analysis. Figure 2 shows the map Global Data Barometer displays on their website, which only has data tracked for 109 of 249 current countries listed under the ISO-3166 standard.
 |
| Fig. 3: European CDC methods of data access and presentation |
While
some countries, such as the United States might have a huge volume of
data to draw from and make informed decisions, data for many countries
remains few and far
between. Many data points measured might have data that is be outdated
by a
decade or never having been collected for a particular country, with the
probability of stale or missing data increasing with the number of
countries that were surveyed. The UN Data (Fig. 4) is a great example of this,
where cross-country correlations are not always possible.
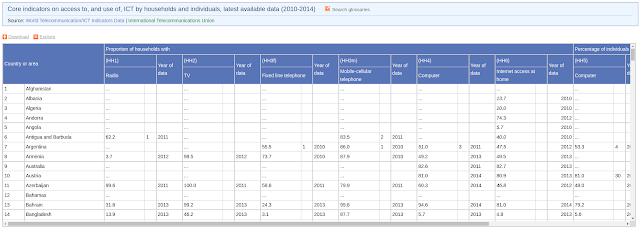 |
| Fig 4. Sparse data from available UN datasets |
Data Interfaces and the Web, a Drama of Many Parts
As
noted in Figure 3, interfacing with datasets on the web can take many
form; web portals indexing internal (Fig. 7) and external (Fig. 5)
datasets, web portals using JavaScript to search and retrieve data files
or external links, interactive visualizations with varying levels of
accessibility, and direct downloads of varied file type to name a few.
Mostly these make data available over the web by way of a web browser. External web pages may also have their own abstractions further
separating the dataset from where the seeker started.
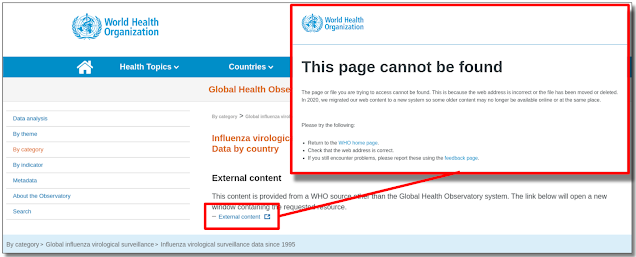 |
| Fig 5. WHO page links to "external content" but link is really for a broken login page |
We
don't have to go far to start finding some issues right on the live
web. Right on the World Health Organization's page I was quickly able to
find some broken links. In the case of Figure 5, a link labeled
"External content" is pointing to
"https://www.who.int/globalatlas/loginManagement/autoLogins/flunet_login.asp",
which is neither external nor functioning. Luckily, we are able to dig up an archived version of the originally intended login page. Figure 6 is from the data.gov/open-gov/
page and shows a much more extreme case. When navigating the data
portal, I attempted to open all of the links for France but found that
only 25% (3 out of the 12) were operational.
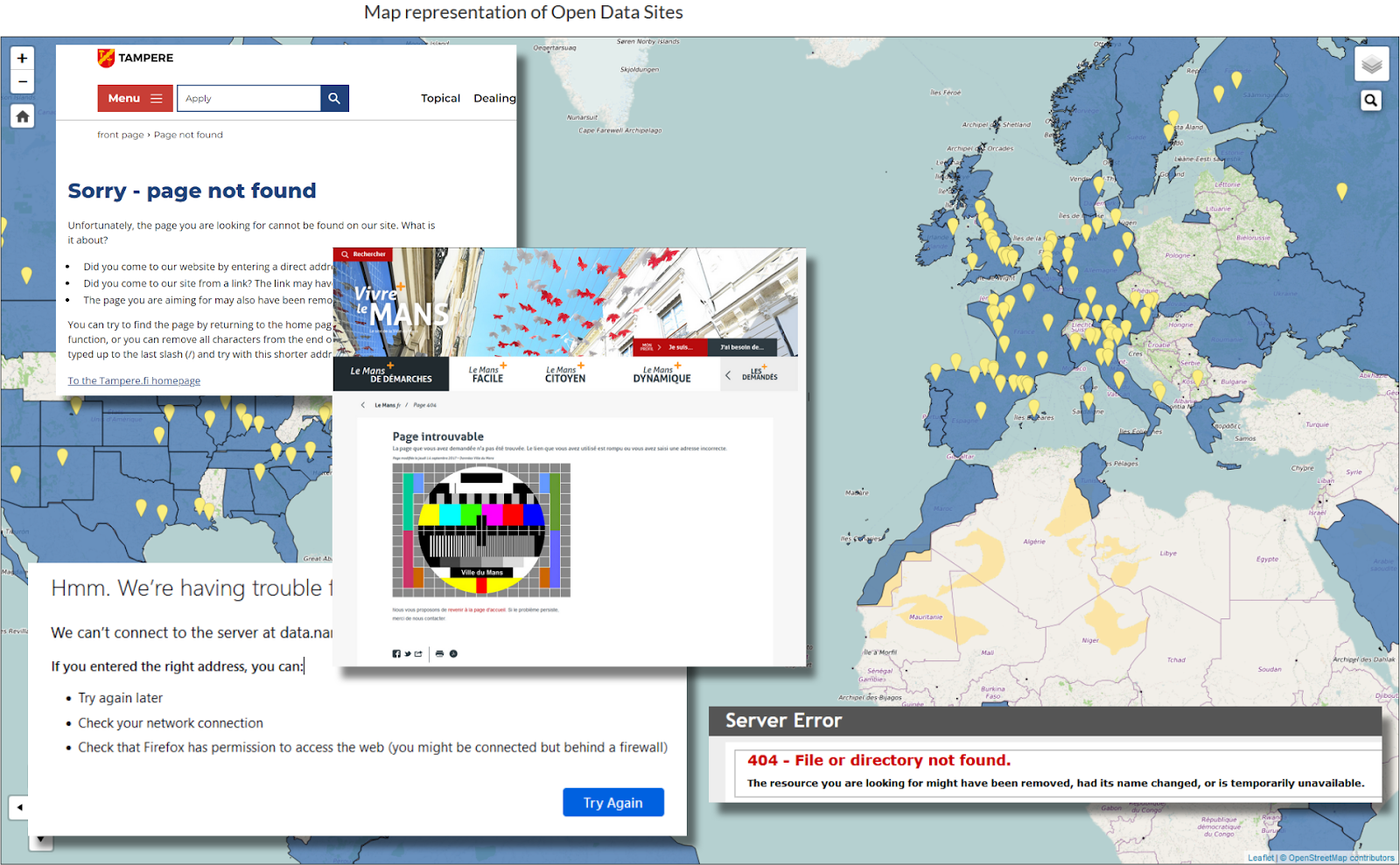 |
| Fig 6. Broken pages sampled from data.gov map |
When we switch gears to the Internet Archive
to try and take a look at some historic data, we are just as quickly
met with some errors of a different kind! Below in Figure 7, I am attempting to navigate an
archived version of the United Nations data portal. We are able to
access the main index or listing of datasets but should we try to
preview them we are met with an unfriendly looking "Error: Http status =
0" modal. There is also never a guarantee that the datasets or anything
beyond the main archive index will be archived and more often than not
data files are missing. In many cases we aren't dealing with just one issue but multiple issues that compound on top of each other. In this case we have some JavaScript code causing errors in the archive, but we are also dealing with links leading to pages which have not been archived.
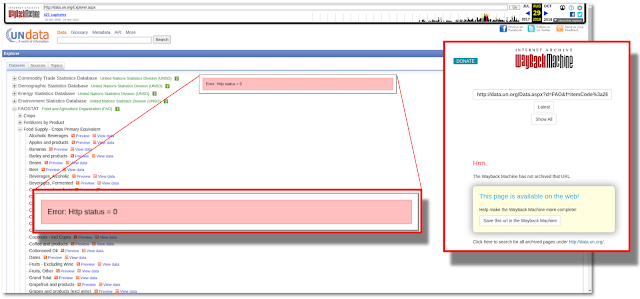 |
| Fig 7. Archived data does not mean that data has actually been archived |
There is a vast trove of semi-frequently updating datasets, ultimately available via
static hyperlinking, which is great for availability but presents a difficult challenge to keep
updated in web archives without automated approaches. But sometimes data is not statically linked and
is fetched from a server using some JavaScript code. In these cases, the
chances of data files being archived is near zero.
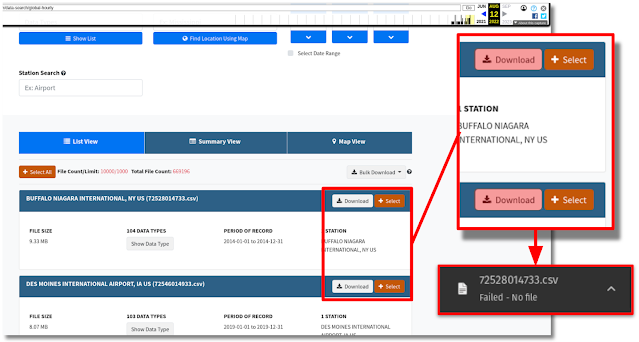 |
| Fig 8. Missing archived files |
Web archiving has many moving components such as the web crawler, the storage infrastructure, and the replay engine. Current web crawling methodologies can have difficulties in capturing web content with complete fidelity. We might also end up with a perfectly faithful representation of a web page or some other form of web content but have a broken replay experience when we go to look at the crawled content. John Berlin wrote his master's thesis on the subject of high-fidelity web crawls and replays and wrote a blog post you can read here if you'd like to dive a little deeper into the subject.
Each component individually in the data pipeline can be a source of broken content and interactivity on archived web pages, as can be seen in Figure 9, where style sheets are not
being correctly applied to the FBI's Crime Data Explorer page, hindering accessibility by breaking
page scrolling and making it unusable compared to the live web page. This can often make it difficult to pinpoint the source of the problem and ties into research by Dr. Justin Brunelle that looks into damage to Mementos (and live web pages). Also see Dr. Brunelle's follow-up blog post, discussing web scientists in Germany who utilized his research while looking at Reproducible Web Corpora, for added context and more information. I have also picked up his work on the Memento Damage project, working with researchers and scholars on the CoSAI project, funded by the Sloan Foundation, to research and help preserve the source code and related ephemera of academic publications. Stay tuned for future updates here on the WS-DL blog!
 |
| Fig 9. Federal Bureau of Inaccessibility |
 | |
| Fig 10. Oil and water, archives and JavaScript |
The
National Oceanic and Atmospheric Administration makes some of its data publicly available as directly downloadable tar.gz archives. This
format of "data portal" is much more archive friendly but still suffers
from all of the traditional shortcomings of normal archiving. For instance, in
Figure 10 we can see the main page has a fair number of snapshots but the number dwindles sharply from 26 to 9 when we navigate one level down (see blog post by Dr. Corren McCoy regarding pagination and archives). We can notice from the last modified date that the archived
tar.gz file does not match with the original date we were browsing.
Attempting to download the file though, will redirect you to yet another
copy with a different file size and date. This single copy is the only
one that shows up from the Internet Archive's main web portal but we if
we check the CDX API we can see that there are two more tar.gz snapshots
which previously used a slightly modified naming scheme of gsom-latest.tar.gz and gsom_latest.tar.gz (Fig. 11). Unfortunately,
what is available in the archive is not even close to the data we need
or expected. Getting data for the specific time you are researching is
of crucial importance and temporally violative content plays a huge error factor.
For normal mementos, this might have an effect on the page but most
likely will not be devastating or render the web page unusable. This
problem is magnified by at least an order of magnitude when archived
data is the target of our inquiry. Sparsely archived URI-Ms, which might
be no where near our target date, simply will not cut it for non-traditional (web page) data representations and trying to work with archived historical data. Scott G. Ainsworth wrote about temporal coherence of composite mementos in his 2015 blog post for those further interested in this topic.
 | |||
| Fig 11. Temporal inconsistencies for archived data |
Google Research applies their search engine approach to their data portal. There is
no relatively static list of datasets to archive as Google dynamically compiles results
based on provided search queries (Fig. 12).
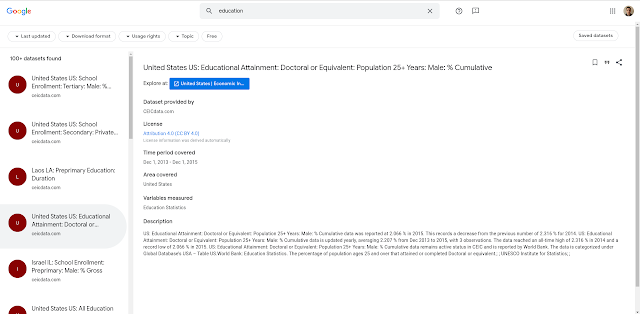 |
| Fig 12. Google Research's compiled dataset search index |
On
one hand this might help users quickly find specific datasets, but on the other it
hinders web crawlers, automatic archiving utilities, and the ability to get a
perspective of overall dataset availability. Some groups and individuals
have even taken on efforts to combat this by mirroring data sources,
such as the CIA World Factbook, and render them into a format more
suitable for the needs of unintended audiences like web crawlers (Fig. 13).
 |
| Fig 13. Third-party CIA World Factbook interface |
Lasting Effects
Sometimes
even intelligence agencies make not so intelligent decisions. When the
CIA decided to migrate their Library page containing the popular World
Factbook, FOIA documents, and other public information, it effectively
broke a vast amount of links scattered around the web.
 |
| Fig 14. If you're going to break something, doing it right always helps! |
Such
drastic changes are not without consequence and in this case it's a
pretty hefty one. By consequence of the CIA Library changes, the 404
redirect page has ended up becoming the most trafficked and archived
page, flooding the web archives with with frequently repetitive
snapshots. Unlike earlier, where we had pages missing which had not been archived, now we have pages we don't particularly wish to be archived at all, or at least not repeatedly in mass number! Any link on this archived redirect page, also being out of
date and broken, now redirect to the archived redirect page in unending
loop (Fig. 15). For more information and perspective on URI design and the effects that changes can have, see W3C's style guide on the subject.
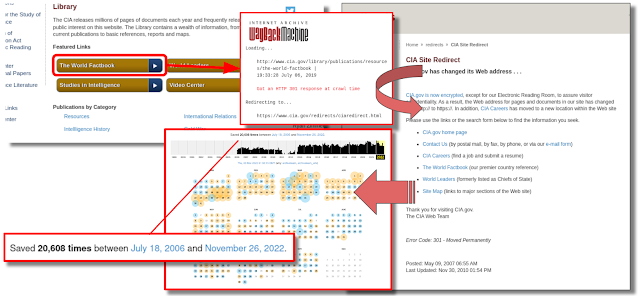 |
| Fig 15. Begone ye wicked interstitial redirect page of the web! |
Sometimes
data is held behind login pages or other walled gardens which limit
their archivability. Often these are not hard walls in that once
authenticated the datasets are otherwise as easy to access as
public data portals. This is enough to cripple automatic crawlers and archiving utilities though which hurts open data, transparency, and accountability which
might otherwise benefit the world. One example of this is content found in the World Bank's data portal, requiring authentication in order to view data (Fig. 16).
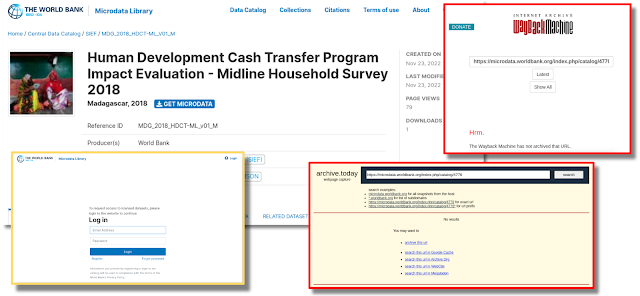 |
| Fig 16. Data availability and ability to archive can be limited by logins and walled content |
One a final note, I wanted to show this example from data.gov which highlights both an archive-friendly and a visually appealing, functional interface and presentation of data. For this dataset, I was able to navigate temporally correct data point details. Both the main and detailed tables used color highlighting to provide emphasis and bring attention to data values. This example shows that there can be good compromises which work for humans, web crawlers, and maintains a level of archivability which can help ensure data security and the preservation of data across expanses of time which might be crucial for future academics and researchers.
 | ||
| Fig 17. Archive-friendly and we get to keep the colors! |
With a look into the heavy importance of data in our lives, as well as issues working with both the past and present web, we can begin to see some of the cracked foundations in our overall data landscape. If we build our assessments about the world from our previous knowledge of it, would it not help if our data systems were more compatible and integrated with established web archiving protocols and worked to make historic data more accessible? If we do not have, cannot trust, or cannot functionally harness the most representative information regarding ourselves and our predicaments, how can we reasonably expect to make much improvement to our situation with it all? The collection of data, its analysis, presentation, and consumption crosses all manner of geopolitical, socioeconomic, and technological domains. No matter how you might work with data, there are always opportunities to help promote a more robust and equitable data ecosystem. Particularly to those of technical backgrounds, I pose that as we step into a new year we might pin up one extra resolution.
We have many protocols, methodologies, and initiatives working independently but we are still missing a cohesive unity at large in how we handle data and present data on the Web. This results in an unfriendly environment for archival and data preservation and many errors which might be mitigated with a more truly unified approach to how we package and distribute data to the Web. By undertaking a more "FAIR" approach towards our design and implementation of data pipelines and how we incorporate our historic data with the archived web, we can transform the "Data Web" into something which looks much more usable and dependable as a source to base our worldly decisions on. Not only would it help out some pretty cool web archiving endeavors and web scientists (😉...) but it could help bring a deeper clarity to many issues we struggle with as nations and individuals!
- David Calano