2023-01-10: A Summary of "Multi-Type-TD-TSR -- Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations"
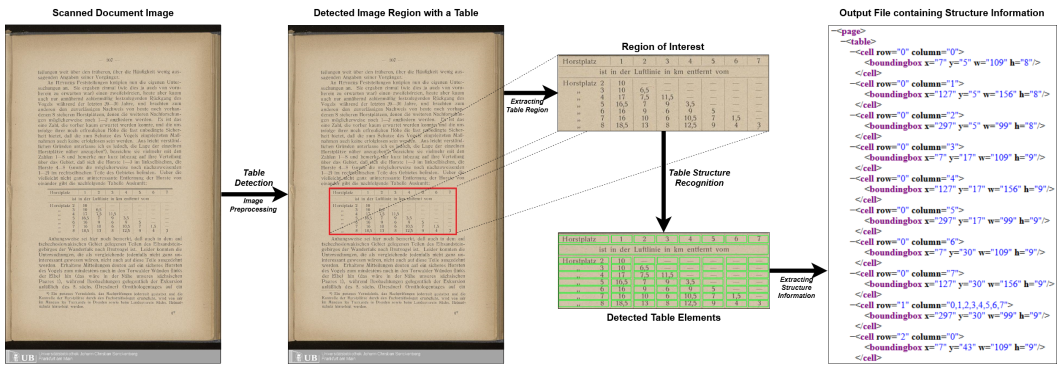
Figure 1: Detecting tables and extracting table cell structures in document image (Fig 2 in Fischer et al.)
In the past decades, several works have been published on detecting and extracting tables both from in-text-tables and tables appearing in born-digital or scanned PDF documents [Pyreddi et al.]. Early work focus on using heuristics such as character alignment in table images to extract tables [Pyreddi et al.]. Recent works involve detecting the corners of the table cells and inferring their connectivity [Seo et al.] in document images (see Figure 2).

Figure 2: Detecting table cell corners (Fig 2 in Seo et al.)
Table extraction in document images involves two steps: detecting the tables (TD) present in the document images and extracting the table cell structures (TSR). Previous works treated TD and TSR as independent tasks and used rule-based method for TD and classical machine learning methods such as conditional random fields (Wei et al.) and hidden markov model for TSR (Babatunde et al.). Most recent works use end-to-end deep-learning-based solutions to solve the two problems together.
Pascal Fischer et al. recently published a paper on "Multi-Type-TD-TSR - Extracting Tables from Document Images using a Multi-stage Pipeline for Table Detection and Table Structure Recognition: from OCR to Structured Table Representations" in KI 2021: Advances in Artificial Intelligence, in which he utilizes end-to-end deep learning techniques to detect tables and extract cell structures in document images. The proposed model also differentiates bordered, borderless, and partially bordered tables (Figure 3).

Multi-Type-TD-TSR

Figure 4: The two stage process of TD and TSR in Multi-Type-TD-TSR (Fig 3 in Fischer et al.)
In Multi-Type-TD-TSR, the authors first apply a preprocessing function to correct any form of skewness in the input document image. Then the aligned document image is passed to a pretrained ResNet152 model to identify the tables present in the image. The authors then process the identified table(s) to convert the foreground (lines and fonts) to black and the background to white to create a color-invariant table image, which are classified into bordered, borderless, and partially-bordered tables. The Multi-Type-TD-TSR takes a document image as input and produces table cell structures in XML format as output.
Structure Recognition for Bordered Tables
Bordered tables are tables with clearly defined ruling-based lines. The authors first convert the identified table image into a binary image, which has a pixel value of either zero (black) or one (white). The resulting image is inverted to obtain a table image with white foreground and black background. Then, the authors perform dilation and erosion operations on the inverted table images to obtain grid-cell table images. To obtain the cell structures, the authors apply a contour-based text detection algorithm on the grid-cell image (see Figure 5).

Structure Recognition for Borderless Tables
Borderless tables are tables with no ruling-based lines. Similar to bordered tables, the authors first convert an identified table image to a binary image. Then, the authors apply an erosion operation on the image. Finally, the authors invert the resulting table image in combination with a bitwise-AND operation to obtain the cell structures.

Structured Recognition for Partially-Bordered Tables
The algorithm implemented on partially-bordered tables is very similar to the one used for bordered tables. The main difference is that instead of creating grid-cell table images using the horizontal and vertical lines detected during the erosion and dilation operations, these lines are deleted from the table images, resulting in borderless tables. Then, the algorithm for the borderless tables is applied on these table images.

Figure 7: Results of erosion operation on partially-bordered tables (Fig 6 in Fischer et al.)
Data
The authors use the table detection model proposed by Li et al. for the task of TD in document images.
The authors trained the TSR model using the ICDAR 2019 training set consisting of 342 document images containing a total of 114 bordered and 429 borderless tables.
Evaluation
To evaluate the proposed TSR model, the authors manually re-annotate some of the table images from ICDAR 2019 (Track B2) dataset. This is because the proposed TSR model recognizes only table cells as part of the overlap from recognized rows and columns. An example of the annotation is shown below (see Figure 7).


Conclusion
In this work, the authors propose Multi-Type-TD-TSR, a multi-stage pipeline for the task of TD and TSR in document images. The proposed model applies a preprocessing function to correct any form of skewness in the document images. The model achieves the highest F1-score among the systems compared for IoU threshold of 0.6 and 0.7 on the annotated test set.
Acknowledgement
I want to express my gratitude to Dr. Michael Nelson and Dr. Jian Wu for taking out time to review this blog post.
Comments
Post a Comment