2022-11-02: David DePape's blog on "frenleyfrens.com" was crawled by Bing by at least October 24, 2022 -- four days before the attack on Paul Pelosi
 |
| Screen shot from: https://www.thegatewaypundit.com/2022/10/exclusive-two-far-right-websites-attributed-david-depape-fabricated-created-friday-deleted-today/ |
An October 29, 2022 article in the Gateway Pundit about the October 28, 2022 attack on Paul Pelosi stated:
It looks like this is all another far-left conjured-up lie. The websites reportedly connected to Paul Pelosi’s “friend” in his underwear are likely fakes.
Part of the author's reasoning is "[t]he only activity on this site as well was in the last two days", referring to the screen shot above of the TimeMap of "frenlyfrens.com/blog" at the Internet Archive's Wayback Machine. The author is conflating crawling of the web page by the Wayback Machine with the creation of the web page, and then arriving at the conclusion that the web page was created on October 28, 2022, the day of the attack. This is most clearly stated in the slug used in the article's URL (emphasis mine):
In the URL above, "friday" refers to October 28, 2022 and "today" refers to October 29, 2022. Of course, there's no guarantee that web sites will be crawled by the Internet Archive (or Google, Bing, etc.) the day they are created. While the presence of a URL in the index of the Internet Archive is proof that it existed (or at least returned an HTTP response) at the time it was crawled, creation time can and frequently does predate the time of archiving.
Using web archives, WHOIS, and search engine (SE) caches, we can prove prove:
- The domain "frenlyfrens.com" was registered September 8, 2022.
- Web pages in the blog were crawled by Bing as early as October 24, 2022.
Thereby negating the premise of the Gateway Pundit article that the web sites were fabricated after the attack, as a "another far-left farce" to associate the attacker with QAnon and other far-right conspiracy theories. The web archives will not help us establish that the David DePape that registered "frenlyfrens.com" is the same David DePape that attacked Paul Pelosi, nor can they help us address the claims that do not have a web component, but they will help us establish a sequence of web-based events prior to October 28, 2022.
First, we can see from whois.com that the domain "frenlyfrens.com" was registered on September 8, 2022 (2022-09-08).
 |
| https://www.whois.com/whois/frenlyfrens.com https://archive.ph/qlsDl |
Since this registration can also change in the future, I've archived the above page to preserve the registration as it was on 2022-10-31.
Next, we can prove that search engines were crawling the site prior to October 28, 2022. Google presumably crawled the site, but they are also quick to purge their caches when pages are removed and I found no evidence of frenlyfrens.com in Google's index when I checked on October 31, 2022. But there is evidence of it being indexed in both Bing and Yandex. In the images below, I provide: the live web link to the SE, a copy of the SE cache URL in the Wayback Machine, and a copy of the SE cache URL in archive.today. The live web SE caches will eventually disappear.
 |
| Bing cache (live web) Bing cache 2022-10-31 (Wayback Machine) Bing cache 2022-10-31 (archive.today) Note: the live web Bing cache looks slightly different than the archived versions because Bing is likely changing the SERP based on the HTTP User-Agent request header. |
 |
| Yandex cache (live web) Yandex cache 2022-10-31 (Wayback Machine) Yandex cache 2022-10-31 (archive.today) Note: the live web Yandex SERP seems to give a different ordering to the URLs on each access. |
In both the Bing and Yandex SE result pages (SERPs), you can see dates that predate October 28, 2022, such as Bing's "Sep 28, 2022", "Sep 04, 2022", and "Aug 23, 2022". Two of these dates are prior to the domain being registered (2022-09-08). There are two possible explanations for why some posts have earlier dates:
- The site was being published at http://wixsite.com prior to having a custom domain registered.
- The HTML meta tags and Schema.org JSON block were altered by the content creator.
Regarding explanation #2, it is important to note that SEs retrieve the dates displayed in the SERPs by extracting them from the HTML. For example, looking at:
https://www.frenlyfrens.com/post/pizzagate
(Bing cache live web, Bing cache 2022-10-31 (Wayback Machine), Bing cache 2022-10-31 (archive.today))
 |
| The HTML meta data for https://www.frenlyfrens.com/post/pizzagate. |
 |
| The Bing cached version of https://www.frenlyfrens.com/post/pizzagate, archived at the Wayback Machine (2022-10-31). |
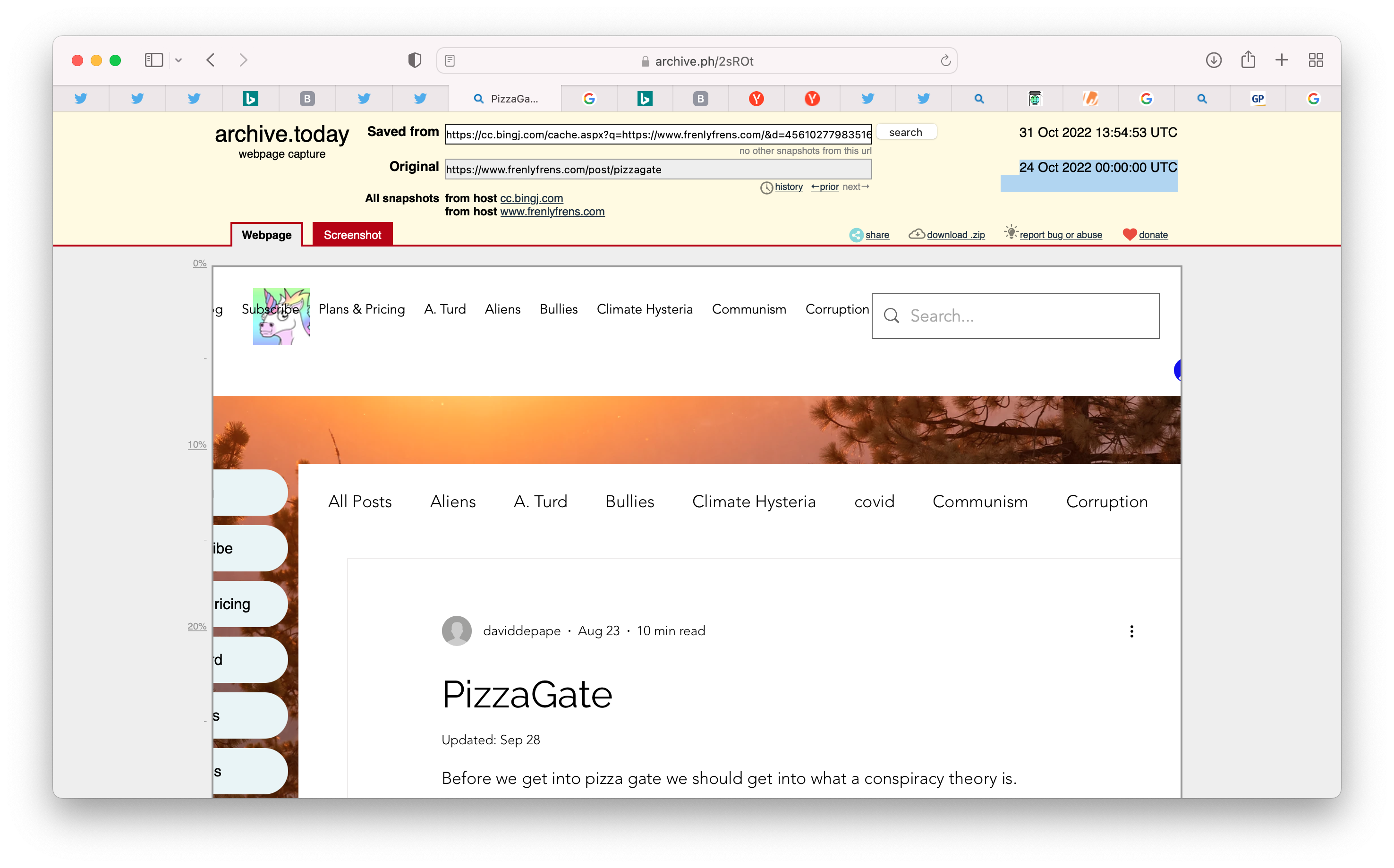 |
| https://archive.ph/2sROt |
(Bing cache live web, Bing cache 2022-10-31 (Wayback Machine), Bing cache 2022-10-31 (archive.today))
 |
| Archived version of https://www.frenlyfrens.com/post/mccarthyism at the Wayback Machine (2022-10-31) |
- The domain "frenlyfrens.com" was established 2022-09-08.
- Some of its pages were crawled by Bing as early as 2022-10-24, four days before the attack.
In MAGA world the big smoking gun around the Pelosi attack is that the attacker's conspiracy blog is *supposedly* faked. Their evidence? They wrongly believe that the Wayback Machine shows the date a website was created (it shows when a site was crawled). Excellent work, all. pic.twitter.com/nk3IcK45Kv
— Charlie Warzel (@cwarzel) October 30, 2022
Joe Hoft asks a fair question - who created these websites? The digital record from the Wayback machine tells you it’s own story.
— Lara Logan (@laralogan) October 30, 2022
Two Far-Right Websites Attributed to David DePape to Smear Conservatives FABRICATED - Created Friday & Deleted Saturday https://t.co/CG5Obs95i8
It is true that for the Pelosi attacker's blog "www.frenlyfrens. com/blog" (unlinked on purpose), @waybackmachine activity began on 2022-10-28.
— Michael L. Nelson (@phonedude_mln) October 31, 2022
We can prove:
1. Domain was registered Sept 8, 2022
2. it was crawled by SEs as early as Oct 23, 2022
🧵 #WebArchiveWednesday https://t.co/6GVHryXkcf
It is also worth noting the domain registration for https://t.co/7f11natTgG, one of the sites described by @AP, shows David DePape’s name and contact information as the person who created the site on 9/8/22 — more than 7 weeks before the attack at Pelosi’s home. pic.twitter.com/GPp0Z0vWdU
— Michael Biesecker (@mbieseck) November 1, 2022
 |
| Clicking on "Saved Copy" |
 |
| Clicking "Saved Copy" in the above image produces this 404 page. I had similar results for all the Yandex SERP results I tried. |
- Lulwah Alkwai, Michael L. Nelson, and Michele C. Weigle, Comparing the Archival Rate of Arabic, English, Danish, and Korean Language Web Pages, ACM Transactions on Information Systems, 36(1), 2017.
- Lulwah Alkwai, Michael L. Nelson, and Michele C. Weigle, How Well Are Arabic Websites Archived?, Proceedings of JCDL 2015.
- Yasmin AlNoamany, Ahmed AlSum, Michele C. Weigle, Michael L. Nelson, Who and what links to the Internet Archive, International Journal on Digital Libraries, 14(3), pp. 101--115. April 2014.
- Yasmin AlNoamany, Ahmed AlSum, Michele C. Weigle, Michael L. Nelson, Who and What Links to the Internet Archive, Proceedings of TPDL 2013. (Also available as Technical Report arXiv:1309.4016).
- Scott Ainsworth, Ahmed Alsum, Hany SalahEldeen, Michele C. Weigle, Michael L. Nelson, How much of the web is archived?, Proceedings of JCDL 2011, pp. 133-136. (Also available as Technical Report arXiv:1212.6177).
Comments
Post a Comment