2022-09-13: A Hybrid Classifier to Extract URLs linking to Open Access Datasets and Software for Computational Reproducibility Study
It has become common practice to include open access datasets and software (OADS) in computational research publications. Emily Escamilla, discusses the increasing trends of including web and software repository platforms in scholarly publications in her One in Five arXiv Articles Reference GitHub blog. OADS are essential resources for replicating computational experiments and making the work more transparent. OADS are also crucial for building repositories that support computational reproducibility. The process of manually examining a large number of research papers in order to extract URLs linking to OADS is time-consuming and labor-intensive. Thus an automatic approach should be adopted to identify and extract OADS-URLs (URLs linking to OADS) from scientific papers. We proposed a hybrid OADSClasssifier consisting of a heuristic and a supervised learning model to identify OADS-URLs in a research paper automatically. The classifier achieves a best F1 of 0.92. The source code is available in GitHub.
Introduction
In this blog, we introduce a hybrid classifier, OADSClassifier. We applied it to electronic theses and dissertations (ETDs) in our paper titled "A Study of Computational Reproducibility using URLs Linking to Open Access Datasets and Software," accepted by Sci-K 2022 colocated with The ACM Web Conference 2022. Our work reports on the disciplinary dependency and chronological trends of OADS-URLs identified in ETDs. These ETDs cover both STEM and non-STEM disciplines. For convenience, we refer to URLs linking to OADS as OADS-URLs and ETDs containing OADS-URLs as OADS-ETDs.
Framework Architecture
Figure 1 shows that PDFMiner was applied to scientific documents to convert PDFs into text files. Next, SpaCy was used for tokenizing texts into sentences. We developed a regular expression to detect URLs in a sentence. Later, a hybrid method consisting of a heuristic and a learning-based model was used to classify sentences containing URLs. Here, we assume that URLs contained in the same sentence have the same category. The heuristic classifier eliminates URLs that end with .pdf or link to publisher URLs, as we observed that most of the publisher URLs do not link to OADS. The learning-based model encodes a sentence using a pre-trained language model. Later, these vector representations were used to train and test a binary logistic regression (LR) classifier.
 |
Figure 1: OADS-URL classification pipeline. |
Dataset
The ground truth dataset included 500 sentences containing URLs extracted from CORD-19 and an in-house SBS paper corpus later labeled as OADS and non-OADS. The final ground truth contains 248 samples labeled as OADS and the rest labeled as non-OADS. It was randomly split into 400 training samples and 100 test samples to train and test our classifier. We randomly selected 100,000 ETDs from about 450k ETDs. The entire dataset was collected by crawling 42 university libraries. A fraction of ETD metadata provided by the libraries was incomplete. Specific fields such as years were missing. There were values in both the "year" and "department" fields in every ETD we selected. The libraries provided metadata for over 60 departments. Because many departments were closely related, we consolidated departments into 18 disciplines (Figure 2) using the Outline of Academic Disciplines from Wikipedia.
Experimental Results
We introduced three different hybrid models and compared them:
No Heuristic Classifier: In this model, all sentences in training (testing) corpus were encoded into vectors and used for training (testing) the LR classifier.
Heuristic classifier for test data only: The same as (1) except that the heuristic classifier was first applied to the testing data. The remaining sentences were classified using the LR classifier.
Heuristic classifier for training and test data. The same as (1) except that the heuristic classifier was first applied to both training and testing data before using the LR classifier.
Our performance evaluation indicates that adding the heuristic classifier for training and testing data achieved the highest F1=0.92. We also investigated the effect of language models on performance. Our analysis demonstrates that the best F1=0.92 was achieved using DistilBERT, leaving original URLs preserved in sentences. The BERT+LR model achieved the second best result with F1=0.88.
Disciplinary Dependency
The OADSClassifier identified 51,201 (14%) sentences containing OADS-URLs out of 369,802 sentences containing URLs in the selected ETDs. The identified OADS-URLs appear in 15,951 ETDs, i.e., about 16.3% of the ETDs in our corpus. We studied how the inclusion of OADS-URLs changes depending on academic discipline, shown in Figure 2, using two fractions. From Figure 2, we can see some interesting findings:
Computer Science has the highest fraction of OADS-ETD% (50.2%)
ETDs in social sciences (e.g., Political science, Sociology, Anthropology, and Education) contain a relatively higher fraction of OADS-ETD% than STEM disciplines (e.g., Engineering, Biology, and Physics).
Certain disciplines have a very small fraction of OADS-ETDs (< 10%), such as Chemistry (9.6%), Business (8.4%), and Geological-Sciences (8.2%), indicating that it is less frequent to find computationally reproducible works in these disciplines.
The OADS-URL% exhibits a relatively even distribution. Computer Science has the highest OADS-URLs% (24.3%), followed by Biology (20.9%) and Psychology (20.0%), indicating that most URLs in ETDs in these fields (> 75%) do not link to OADS
None of the 717 Geography ETDs contained OADS-URLs.
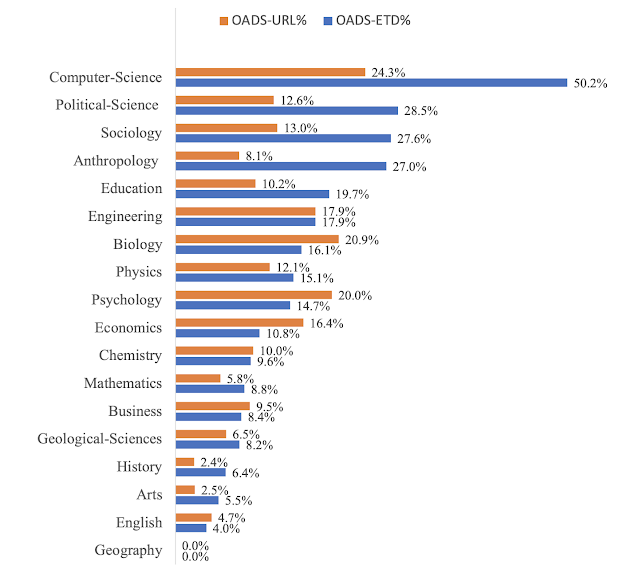 |
| Figure 2: Dependency of the fractions of OADS-URL and OADS-ETD for academic disciplines. |
We also analyzed the chronological trends of OADS-URLs in the context of our sample of ETDs. Our sample may be biased since more recent ETDs are embargoed (so not included in the dataset) than older ETDs, and the fraction embargoed varies by discipline. In addition, our collection process resulted in a lower number of ETDs in the period starting 2019 and a low number before 2010; these factors could lead to uncertainty. Figure 4 illustrates the fraction of OADS-URLs and the fraction of OADS-ETDs as a year function. The findings are the following:
First, the fraction of OADS-ETDs has been gradually increasing from less than 5% in 2000 to more than 25% in 2010 to about 40% in 2020.
The fraction of OADS-URLs seemed relatively stable after 2000. Since 2016, this fraction has gradually decreased from 15% to about 10% in 2019–2020.
Two factors could cause this trend:
The growth of non-OADS URLs in ETDs, and
The selection bias (as seen in Figure 3) due to a weak correlation between embargoed ETDs and the inclusion of OADS-URLs.
 |
Figure 3: Numbers of OADS-URLs and ETDs containing OADS URL as a function of publication year in our dataset. |
 |
Figure 4: Fractions of OADS-URLs (blue) and ETDs containing OADS-URLs (red) as a function of year. |
Conclusions
We analyzed the computational reproducibility of ETDs collected from US universities using OADS-URLs. The essential contribution is a model, OADSClassifier, that automatically identifies sentences containing OADS-URLs from research papers. This model achieved a best F1 of 0.92. Our analysis for URLs in ETDs found that the inclusion of OADS-URLs exhibited a strong dependency on disciplines. Our analysis also found that the fraction of OADS-ETDs gradually increases over the past 20 years.
References
[1] Salsabil, L., Wu, J., Choudhury, M. H., Ingram, W. A., Fox, E. A., Rajtmajer, S. J., & Giles, C. L. (2022). A Study of Computational Reproducibility using URLs Linking to Open Access Datasets and Software. Association for Computing Machinery, 10, 3487553-3524658.
[2] Cacioppo, J. T., Kaplan, R. M., Krosnick, J. A., Olds, J. L., & Dean, H. (2015). Social, behavioral, and economic sciences perspectives on robust and reliable science. Report of the Subcommittee on Replicability in Science Advisory Committee to the National Science Foundation Directorate for Social, Behavioral, and Economic Sciences.
[3] Färber, M. (2020, August). Analyzing the GitHub repositories of research papers. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries in 2020 (pp. 491-492).
[4] Yang, Y., Youyou, W., & Uzzi, B. (2020). Estimating the deep replicability of scientific findings using human and artificial intelligence. Proceedings of the National Academy of Sciences, 117(20), 10762-10768.
--Lamia Salsabil (@liya_lamia)
Comments
Post a Comment