2021-11-02: Extraction and Evaluation of Knowledge Entities from Scientific Documents (EEKE2021) Workshop Trip Report

Due to the global pandemic the ACM/IEEE Joint Conference on Digital Libraries (JCDL 2021) was organized online by the School of Information Sciences of the University of Illinois at Urbana-Champaign during September 27-30, 2021. Members of the Web Science and Digital Libraries Research Group (WSDL) attended the workshops, tutorials, paper sessions, posters and demonstrations virtually via Zoom. Muntabir Choudhury wrote an excellent trip report covering the JCDL 2021 main conference.
The JCDL workshop, September 30, 2021, on “Extraction and Evaluation of Knowledge Entities from Scientific Documents (EEKE2021)” was organized by Dr. Chengzhi Zhang, Dr. Philipp Mayr, Dr. Wei Lu, and Dr. Yi Zhang with an aim to draw the attention of the Computer and Information Science scholars specialized in relevant fields (Information Extraction, Text Mining, NLP etc.) towards the open problems in the extraction and evaluation of knowledge entities from scientific documents.
The EEKE2021 workshop was assembled into four different sessions where three papers were presented in each of the first three sessions. Session 4 was the longest session with six paper presentations.
Session 1: Entity Extraction and Application
Session 1 started with the presentation of the long paper “ANEA: Automated (Named) Entity Annotation for German Domain-Specific Texts ” by Anastasia Zhukova, from University of Wuppertal, Germany.

Anastasia Zhukova, from University of Wuppertal,
— Lamia Salsabil (@liya_lamia) September 30, 2021
Germany now presenting "ANEA: Automated (Named) Entity Annotation for German Domain-Specific Texts" at #JCDL2021 @JCDLConf https://t.co/Ui56NcgjH0 pic.twitter.com/iyonSMRveC
This paper proposed an unsupervised Wiktionary-based automated entity annotator that automatically extracts domain entities from German texts. Anastasia Zhukova asserted that the entities are extracted by deriving the most domain representative automatically annotated terms. This work addresses a core problem of Named Entity Recognition (NER) - the cost of expensive and labor intensive human annotations required for the creation of domain-specific NER datasets. ANEA substitutes this time consuming task by automating the categorization and annotation of most representative terms.
Evaluation Methods and results of ANEA pic.twitter.com/pNRXtGlIdo
— Lamia Salsabil (@liya_lamia) September 30, 2021
The second paper presented in this session was “Joint Entity and Relation Extraction from Scientific Documents: Role of Linguistic Information and Entity Types” by Debarshi Kumar Sanyal, from Indian Institute of Technology, India. The goal of this paper is to automatically extract entities and their relationships from a scientific abstract using deep neural networks. In their work, they used a pre-trained transformer, BERT, to get the contextual embedding of the tokens. Then they used POS encoder ScispaCy to generate POS tags of the input sentence. A fusion module is used to add the BERT embedding of the token and the POS embedding of its corresponding POS tag. Finally, a shallow entity classifier and a shallow relation classifier are used to identify entities and classify the relationship between every pair of entities respectively.
Dataset: Adverse-Effect and Drug pic.twitter.com/kekdses0RW
— Lamia Salsabil (@liya_lamia) September 30, 2021
The last paper presented in this session was “Classification of URLs Citing Research Artifacts in Scholarly Documents based on Distributed Representations” which describes methods for classifying URLs mentioned in scholarly papers into three categories:
a tool - a program, software, toolkit etc.
dataset - experimental data, observation data
Other - not research artifacts
Masaya Tsunokake, from Nagoya University, Japan is giving a talk on "Classification of URLs Citing Research Artifacts in Scholarly Documents based on Distributed Representations" at #JCDL2021 @JCDLConf pic.twitter.com/LMLmO9V6CE
— Lamia Salsabil (@liya_lamia) September 30, 2021
Citation context of URL is the key approach of their work pic.twitter.com/o55xuqfo6s
— Lamia Salsabil (@liya_lamia) September 30, 2021
The citation context of URL is a key approach to their work. They have used two different approaches for distributed representation of URLs:
Considering each URL as a word
Considering each element of a URL as a word
Two different approaches for distributed representations of URLS pic.twitter.com/hDRiXD8qHb
— Lamia Salsabil (@liya_lamia) September 30, 2021
Methods for URL classification -
— Lamia Salsabil (@liya_lamia) September 30, 2021
1. considering each URL as a word
2. considering each URL element as a word pic.twitter.com/NVrKziFh0U
Experimental results of the work pic.twitter.com/yF2e7TVSUF
— Lamia Salsabil (@liya_lamia) September 30, 2021
Session 2: Keyword Extraction and Application
The theme of session 2 was “Keyword extraction and their application”. Session 2 started with the paper presentation by Liangping Ding, from University of Chinese Academy of Science, China on "Design and Implementation of Key phrase Extraction Engine for Chinese Scientific Literature". The authors developed a Chinese key phrase extraction engine for Chinese scientific literature based on advanced deep learning. The training corpus used in training the Chinese Keyphrase Extraction Engine is small and not diversified and also the models are not openly and widely accessible to the researchers. The authors asserted that their Keyword Extraction Engine is built on large-scale training data from multiple domains. They have conducted their experiments on five models - four of them are based on sequence labeling and the last model is based on span formulation prediction.
Candidate Keyphrase Extraction and candidate Keyphrase Ranking pic.twitter.com/cbYRMFHb3A
— Lamia Salsabil (@liya_lamia) September 30, 2021
Browser online demo pic.twitter.com/2ySKhZo3iB
— Lamia Salsabil (@liya_lamia) September 30, 2021
Aofei Chang, from Peking University, China presented their paper “Keyword Extraction and Technology Entity Extraction for Disruptive Technology Policy Texts” in session 2. Aofei Chang started the presentation by discussing the importance of disruptive technologies.
Aofei Chang, from Peking University, China is giving a talk on their work "Keyword Extraction and Technology Entity Extraction for Disruptive Technology Policy Texts" at #JCDL2021 @JCDLConf #EEKE2021 pic.twitter.com/x2mw2YzR9H
— Lamia Salsabil (@liya_lamia) September 30, 2021
Then he discussed text collection, relevance judgement and the construction of keyword extraction algorithms of disruptive technology. He also showed a comparison of algorithms used (YAKE, TextRank, KeyBERT).
Comparison of Algorithms used (YAKE, TextRank, KeyBERT) and the result pic.twitter.com/tFN260zmWR
— Lamia Salsabil (@liya_lamia) September 30, 2021
Last paper in session 2 was “Extracting Domain Entities from Scientific Papers Leveraging Author Keywords” by Jiabin Peng, from Nanjing University of Science and Technology, China. In this paper, the authors proposed a method for extracting domain based entities from scientific papers using author keywords. The core purpose of this paper is to reduce the dependency of current extraction methods on manually annotated corpus and to increase the generalization ability.
Jiabin Peng, from Nanjing University of Science and
— Lamia Salsabil (@liya_lamia) September 30, 2021
Technology, China now presenting "Extracting Domain Entities from Scientific Papers Leveraging Author Keywords" at #JCDL2021 @JCDLConf #EEKE2021 pic.twitter.com/srXQzMsMma
From their experimental analysis and result, they have shown that SVM performs best with a f1-score of 0.753 among the five models.
SVM has the best performance with f1 score of 0.753 pic.twitter.com/YOiqcBLeYT
— Lamia Salsabil (@liya_lamia) September 30, 2021
Session 2 ended with Keynote 2 "Entity Summarization: Where We Are and What Lies Ahead?" by Gong Cheng. It was a presentation largely from his survey paper "Entity Summarization: State of the Art and Future Challenges". He started like this- In the wiki there are summaries, for example for Illinois. For which I do not need to read all the things. But how can we summarise all the entities? In this survey, he addressed present state of R&Ds which tries to solve the summarization problem. In this research, the authors identified more then 30 technical features which are being used in this field. They synthesized them into two types of features: Generic and specific. Gong explained a few generic features including score a property, statistical informativeness, Ontological informativeness and Diversity. Specific features are used when it requires domain knowledge, context awareness, and personalization. Few include Query relevance and Entity interdependence.
Session 2 is ending with keynote 2: "Entity Summarization: Where We Are and What Lies Ahead?" by Gong Cheng at #EEKE2021 @JCDLConf #JCDL2021 pic.twitter.com/pQjSFAC5QV
— Sami Uddin (@usersami7) September 30, 2021
Gong identified current methods that are mainly unsupervised and combine multiple technical features using various frameworks. Authors also found some deep learning methods, but they are far from perfect because of the lacking for training data.
Frameworks for feature combination. Pros and cons. pic.twitter.com/rjOL5OMmyW
— Sami Uddin (@usersami7) September 30, 2021
Gong pointed out several future directions: the use of semantics, human factors, machine and deep learning, non-extractive methods, and interactive methods.
What lies ahead? What can we do?
— Sami Uddin (@usersami7) September 30, 2021
- Use of semantics
- Human factors
- Machine and Deep Learning | How can we work on weak supervision
- Interactive methods pic.twitter.com/3CAOHjuDCw
Session 3: Knowledge Graph and Application
Session 3 kicked in with the presentation "Detecting Cross-Language Plagiarism using Open Knowledge Graphs" by Johannes Stegmüller, University of Wuppertal, Germany. The authors have proposed the new multilingual retrieval model Cross-Language Ontology-Based Similarity Analysis (CL-OSA) for identifying cross-language plagiarism. They have shown that CL-OSA outperforms the trending methods for retrieving candidate documents from large, topically diverse test corpora which includes distant language pairs. Johannes described how the detection of plagiarism works in a multilingual platform with a brief and informative overview of CL-OSA.
Session 3 kicked in with the presentation "Detecting Cross-Language Plagiarism using Open Knowledge Graphs" by Johannes #EEKE2021 #JCDL2021 @JCDLConf @WebSciDL pic.twitter.com/xwBcUtiGs4
— Sami Uddin (@usersami7) September 30, 2021
How this detection works in a multilingual platform
— Sami Uddin (@usersami7) September 30, 2021
- Vectors created for docs from each language
- Calculate similarity pic.twitter.com/1CQHyrXnSJ
Preprocessing pic.twitter.com/FDe9X81JBz
— Sami Uddin (@usersami7) September 30, 2021
Entity Extraction pic.twitter.com/xnHMh4cVqJ
— Sami Uddin (@usersami7) September 30, 2021
An entity can contain different meanings. pic.twitter.com/QehKR8HUjz
— Sami Uddin (@usersami7) September 30, 2021
The second paper presented in session 3 was on “A PICO-based Knowledge Graph for Representing Clinical Evidence” by Yongmei Bai, Peking University, Beijing, China. In this work, the authors have introduced the method of generating PICO-based knowledge graphs from clinical trials. They have used clinical trials about COVID-19 in ClinicalTrials.gov as the raw data and constructed two knowledge graph - CTKG & CTRKG. These knowledge graphs allow for queries, batch exports, and provide data for clinical evidence based on PICO.
Knowledge graph representation related to covid. pic.twitter.com/tWdTJX9hJI
— Sami Uddin (@usersami7) September 30, 2021
Session 3 ended with a short paper presentation by Chuanming Yu on “A knowledge graph completion model integrating entity description and network structure”. In this work, a knowledge graph completion model has been proposed which not only includes the entity relationship representation but also includes the entity description and network structure. The authors have conducted experiments on various datasets -- FB15K, WN18, FB15K237, and WN18RR -- to prove their claim about the proposed model.
Experimental results on four different datasets. pic.twitter.com/HH8VMvUtaV
— Sami Uddin (@usersami7) September 30, 2021
Session 4: Poster/ Greeting Notes of EEKE2021
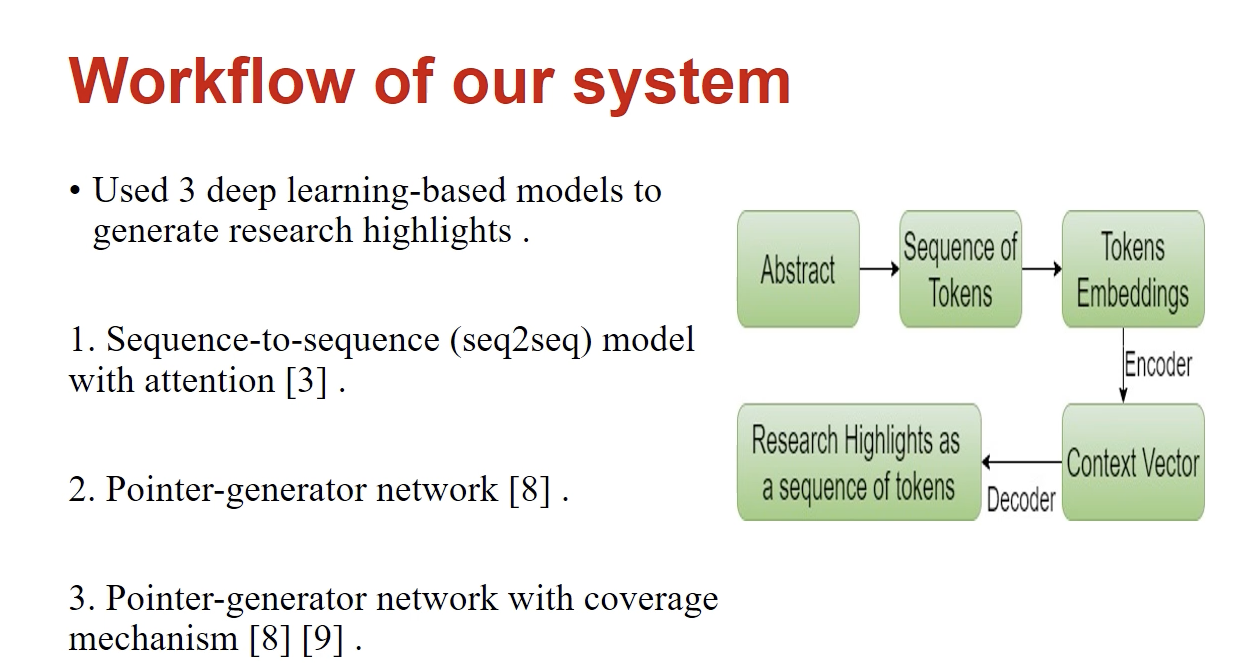
Session 4 was all about poster paper presentations. It happened parallelly in six different breakout rooms. We joined one presentation by Tohida Rehman on “Automatic Generation of Research Highlights from Scientific”. The authors of this paper proposed deep-neural network based models to automatically generate research highlights from scientific abstracts.
They have basically used three deep learning based models to generate the highlights:
Sequence-to-sequence (seq2seq) model
Pointer-generator network and
- Pointer-generator network with coverage mechanism
Closing:
The EEKE 2021 workshop ended with the keynote presentation of co-chairs of EEKE2021 (Chengzhi Zhang, Philipp Mayr, Wei Lu, Yi Zhang) about the future of this workshop. We found this workshop very informative and learnt about some fresh ideas. Hopefully, this EEKE workshop will be arranged in the future to facilitate further research and welcome fresh and great research ideas.
-- Lamia Salsabil (@liya_lamia), Sami Uddin (@usersami7)
Comments
Post a Comment