2020-08-27: A 25 Year Retrospective on D-Lib Magazine
In this HTML version, the footnotes were converted to either hyperlinks or endnotes.
A 25 Year Retrospective on
D-Lib Magazine
Michael L. Nelson
Old Dominion University
Norfolk, VA USA
mln@cs.odu.edu
Herbert Van de Sompel
Data Archiving and Networked Services
The Hague, Netherlands
herbert.van.de.sompel@dans.knaw.nl
Abstract
In July, 1995 the first issue of D-Lib Magazine was published as an on-line, HTML-only, open access magazine, serving as the focal point for the then emerging digital library research community. In 2017 it ceased publication, in part due to the maturity of the community it served as well as the increasing availability of and competition from eprints, institutional repositories, conferences, social media, and online journals -- the very ecosystem that D-Lib Magazine nurtured and enabled. As long-time members of the digital library community and authors with the most contributions to D-Lib Magazine, we reflect on the history of the digital library community and D-Lib Magazine, taking its very first issue as guidance. It contained three articles, which described: the Dublin Core Metadata Element Set, a project status report from the NSF/DARPA/NASA-funded Digital Library Initiative (DLI), and a summary of the Kahn-Wilensky Framework (KWF) which gave us, among other things, Digital Object Identifiers (DOIs). These technologies, as well as many more described in D-Lib Magazine through its 22 years, have had a profound and continuing impact on the digital library and general web communities.
1 Introduction
In July, 1995, the Corporation for National Research Initiatives (CNRI) published the first issue of D-Lib Magazine (www.dlib.org). D-Lib Magazine was the most visible and impactful component of the D-Lib Forum administered by CNRI and funded by the Defense Advanced Research Projects Agency (DARPA). In July, 2017, D-Lib Magazine published its 265th and final issue, bringing to a close a successful 22 year run that saw it evolve into an entity around which the entire digital library (DL) community coalesced. D-Lib Magazine was itself an innovation: it was published in HTML only and thereby encouraged exploration in scholarly publishing with hypertext and hypermedia, it was open access with no article processing charge so it reached a broad community, its “magazine” focus and initially monthly publication schedule facilitated community building in a pre-blog and pre-social media world, and it found the elusive middle ground between researchers and practitioners.
During its 22 year run, D-Lib Magazine offered several opportunities for self-reflection for both the magazine and the community at large. In 2000, Bill Arms surveyed the first five years [10]. In 2005, a ten year anniversary special issue was published with contributions from many of the central figures of D-Lib Magazine and the DL community at large [54, 128]. The 20 year anniversary had a more muted tone, with only the issue’s editorial marking the event [65]; perhaps because editor Larry Lannom knew the time for the final editorial was not far off [66]. So we take this, the 25 year anniversary of the first issue, to reflect on the impact of D-Lib Magazine, both for the information that it conveyed as well as a proof-of-concept for many DL and web concepts and technologies that we enjoy today. We provide this retrospective as those for whom D-Lib Magazine had a significant career impact, both as readers and authors; after the editors we were the top two most frequent authors, with 39 unique contributions between us.
Internet-based digital libraries (or “electronic libraries” as they were frequently known as prior to 1994) predated the popularity of the web; some of the well-known examples include: “Knowbots” [55], the CORE electronic journal project [69], Netlib [25], xxx.lanl.gov [34], Computer Science Technical Reports Project (CS-TR) [53], Wide-Area Technical Report Server (WATERS) [73], and the Langley Technical Report Server (LTRS) [85]. However, the NSF-funded Digital Library Initiative (DLI, 1994–1998) co-occurred with the rapidly increasing interest in the web, which was accelerated by the late 1993 release of the NCSA Mosaic browser [4]. As a result, the story of the early web parallels the story of digital libraries and D-Lib Magazine. It is in this context of the nascent web that D-Lib Magazine should be understood, for it addressed a critical need in 1995. From the editorial of the first issue [31]:
``The magazine is itself an experiment in electronic publishing, which fulfills its communication function for the Digital Library Forum by testing the limits of writing in and for a wholly networked environment. We have no -- and propose no -- print analogue, and we will be most intrigued by substantive articles that take advantage of the power of hypermedia while retaining the strengths of traditional, print publishing.’’
The first issue had 14 “Clips and Pointers” – announcements, deadline reminders, calls for participation, requests for proposals and papers, and brief updates. Although email lists served these functions (and still continue to do so), this announcement and awareness function of a magazine has largely been replaced by blogs, social media. One no longer expects to learn of calls for papers or requests for proposals in a magazine, and event summaries are now easily discoverable via search engines with far more precision than those of the mid-1990s (e.g., Lycos [74]). For example, our conference report for the 2003 Joint Conference on Digital Libraries (JCDL) was published in D-Lib Magazine [82], but JCDL 2020 is best reviewed in blogs [48] or Twitter.
The first issue had three articles, then carried under the heading of “stories and briefings”, reflecting the early position of a “magazine” and not an online journal. In fact, they were summaries of existing conventional reports and publications:
- “Metadata: the foundations of resource description” – a summary of the OCLC/NCSA Metadata Workshop [123] that produced the Dublin Core Metadata Element Set, which continues today as the Dublin Core Metadata Initiative (dublincore.org).
- “An agent-based architecture for digital libraries” – a description of the distributed agent architecture explored in the University of Michigan Digital Library (UMDL) [12]; the University of Michigan was one of six participants in the first NSF/DARPA/NASA Digital Library Initiative (DLI).
As tentative steps in this new publishing experiment, all three articles are single authored (though they summarize multi-author publications), are relatively short, and have limited figures and references. Although D-Lib Magazine would soon evolve into a venue where original research was published (e.g., a 1999 editorial estimates that half of the contributions described original research [9]) and essentially functioned as an online journal, it was edited and never refereed. This produced a well-known problem: if you wanted your material to reach a wide audience, it needed to be in D-Lib Magazine, but if you wanted academic “credit”, it needed to be in a conventional journal or refereed conference proceedings. In the time before Google, Google Scholar, CiteSeer, Microsoft Academic et al., this was a binary choice. Now it is possible for authors to gain the imprimatur of a quality journal or conference proceedings, and at the same time leverage the permissive attitude regarding pre-prints and e-prints of many publishers (e.g., ACM) to ensure that articles are discoverable and freely available.
2 D-Lib Magazine as a publishing experiment
D-Lib Magazine was unique in many respects. First, although it clearly billed itself as a “magazine”, it quickly became a venue where original research was published. Second, although it initially offered additional services and categories, the real innovation came about because it embraced HTML, and only HTML, as the publication medium. HTML allowed the articles themselves to take advantage of a rapidly evolving medium, including links and multimedia in a way PDF-primary publications could not. Finally, with the vantage of 25 years, the decisions made in how D-Lib Magazine would be structured and maintained compare favorably to other Web-based publishing peers which began shortly after D-Lib Magazine.
2.1 More than a magazine, even if not quite a journal
Although early issues had unsuccessful experiments with HyperNews [16] for comments as well as a separate “technology playpen” / “technology spotlight” section [128], these features were eventually subsumed within the HTML publishing experiment itself, and D-Lib Magazine’s primary unit of currency became its articles. From 1995 through 2017, D-Lib Magazine published 265 issues and 1062 articles (D-Lib Magazine actually defined and evolved many different categories of contributions [127], but we refer to entries available from the title index as simply “articles”). The issues were published monthly through June, 2006 (with the July/August issues published simultaneously as “7/8”), and it switched to bimonthly publication from July/August 2006 through July/August 2017. D-Lib Magazine was always “a magazine, not a peer-reviewed journal” and aimed for “articles that are 1,500 to 3,000 words in length and seldom accept articles in excess of 5,000 words” [128]. To explore this, we took the title index:
- from the HTML extracted all links that begin with <p class="archive">, which includes the articles but excludes “in brief” and “opinion” entries.
- for each of the 1062 URLs, we used lynx -dump $URL > $filename, which saves only the result of rendering the HTML into plain text.
- used wc -w on each of the resulting files to count the number of words in the article.
Using lynx to render the HTML is not perfect, but it reasonably approximates the number of words in the article. Figure 1 shows the number of articles published each calendar year, and Figure 2 shows the average number of words per article for each calendar year. From Figure 2 we can see that although switching to bimonthly publication in 2006 reduced the number of articles per year, it did not halve it. Even though in 2017 D-Lib published only four issues (instead of six), the total number was only slightly down from 2016, perhaps indicating clearing the queue of remaining articles for the year.
Figure 2 shows a trend of shorter articles in the first three years, and then finally hitting its stride in 1998, perhaps corresponding with the acceptance of the format by both authors and editors. From 1998 on, the values fluctuate (we are unsure of why 2009 has a low value) but it is not until the last six years (2012–2017) that the word count approximates the early peak from 1998.

Figure 1: Total articles published per year (1995 and 2017 were incomplete years).
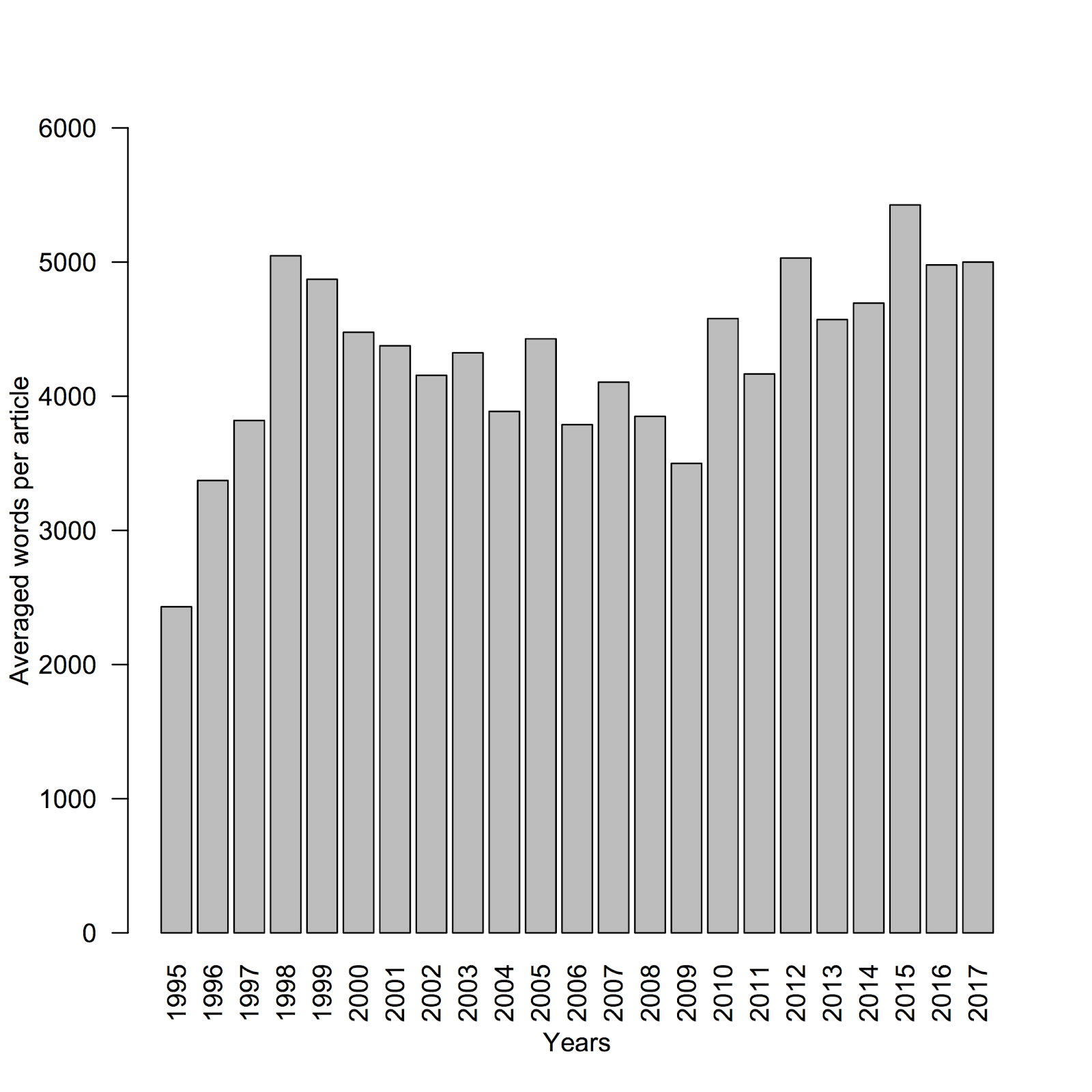
Figure 2: Average words per article per year.
Even though it was never peer-reviewed, and did not have an editorial board like a conventional journal (though it did have an advisory board), D-Lib Magazine had a significant impact in the conventional literature and served as a de facto journal. A ten year anniversary analysis (from 2005) showed that D-Lib Magazine had acquired 147 citations from the ACM/IEEE Joint Conference on Digital Libraries and its predecessor conferences [128]. A more detailed authorship and citation analysis showed over 1300 citations in the first 15 years [91].
A look at the 2020 Google Scholar rankings in “Library & Information Sciences” shows the top 20 venues in the field (Figure 3; note: “digital libraries” as a field awkwardly straddles “Library & Information Sciences” and “Databases & Information Systems” in Google Scholar’s classification). D-Lib Magazine is just outside the top 20, despite no new publications since 2017, with an h5-index of 17 (Figure 4), which is comparable to JCDL’s h5-index of 18 (Figure 5). Among its contemporaries (section 2.3), First Monday is doing well with an h5-index of 30 (Figure 6), but we cannot determine in which category Google Scholar places First Monday. Ariadne and the Journal of Digital Information are not included in Google Scholar’s 2020 rankings.

Figure 3: Library & Information Science, Google Scholar https://scholar.google.com/citations?view_op=top_venues&hl=en&vq=eng_libraryinformationscience (from 2020-07-19).
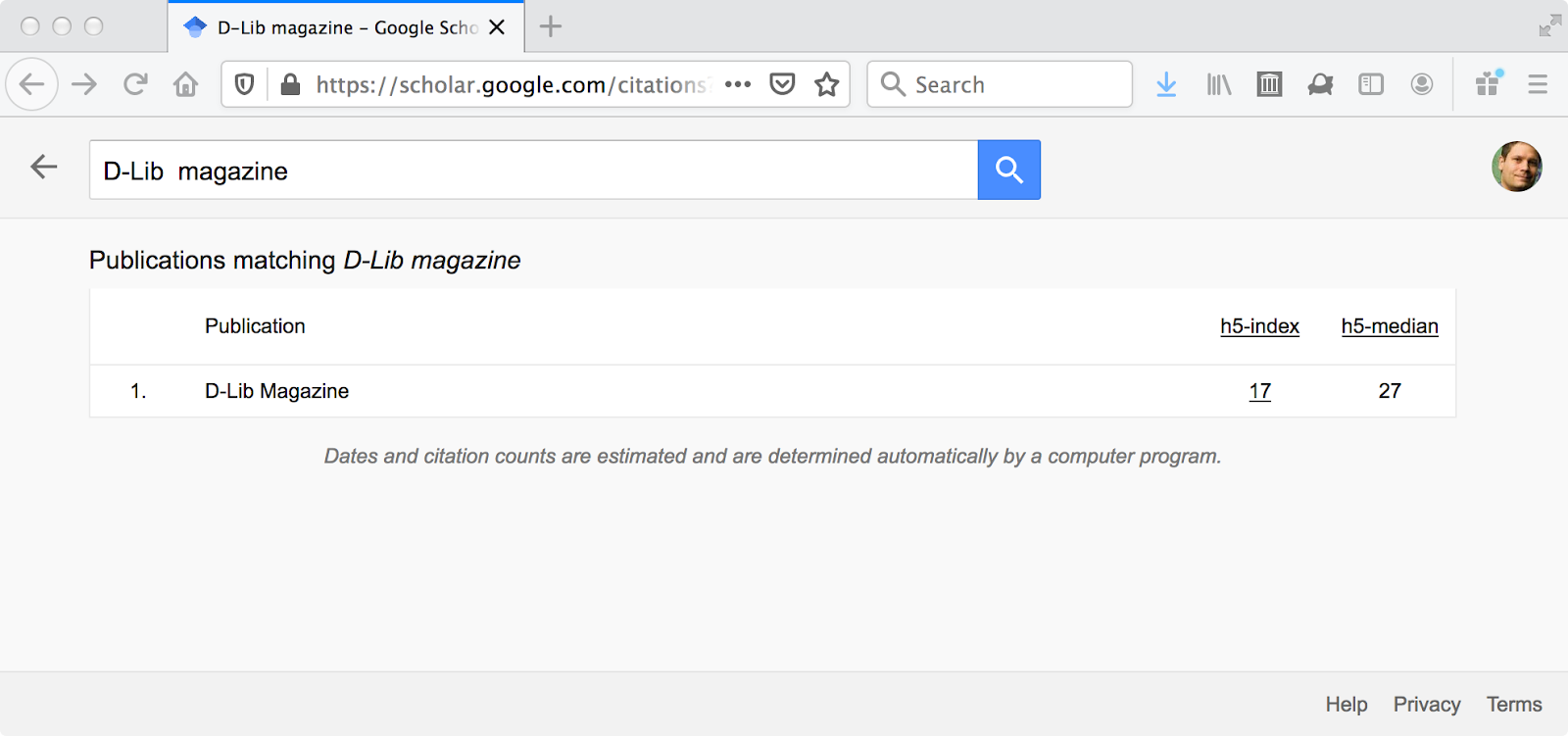
Figure 4: D-Lib Magazine, Google Scholar https://scholar.google.com/citations?hl=en&view_op=search_venues&vq=D-Lib++magazine&btnG= (from 2020-07-19).
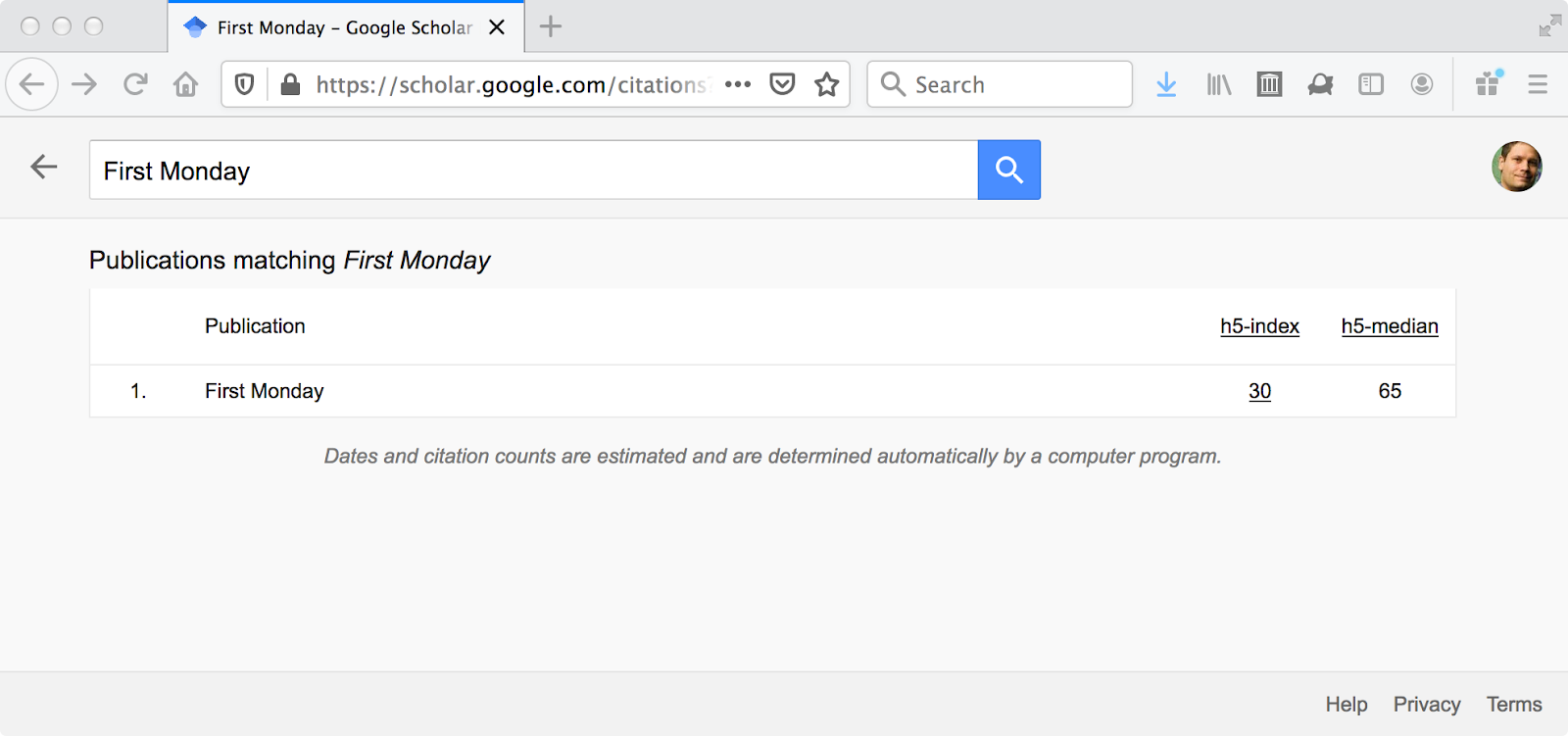
Figure 5: JCDL, Google Scholar https://scholar.google.com/citations? hl=en&view_op=search_venues&vq=joint+conference+on+digital+ libraries&btnG= (from 2020-07-19).
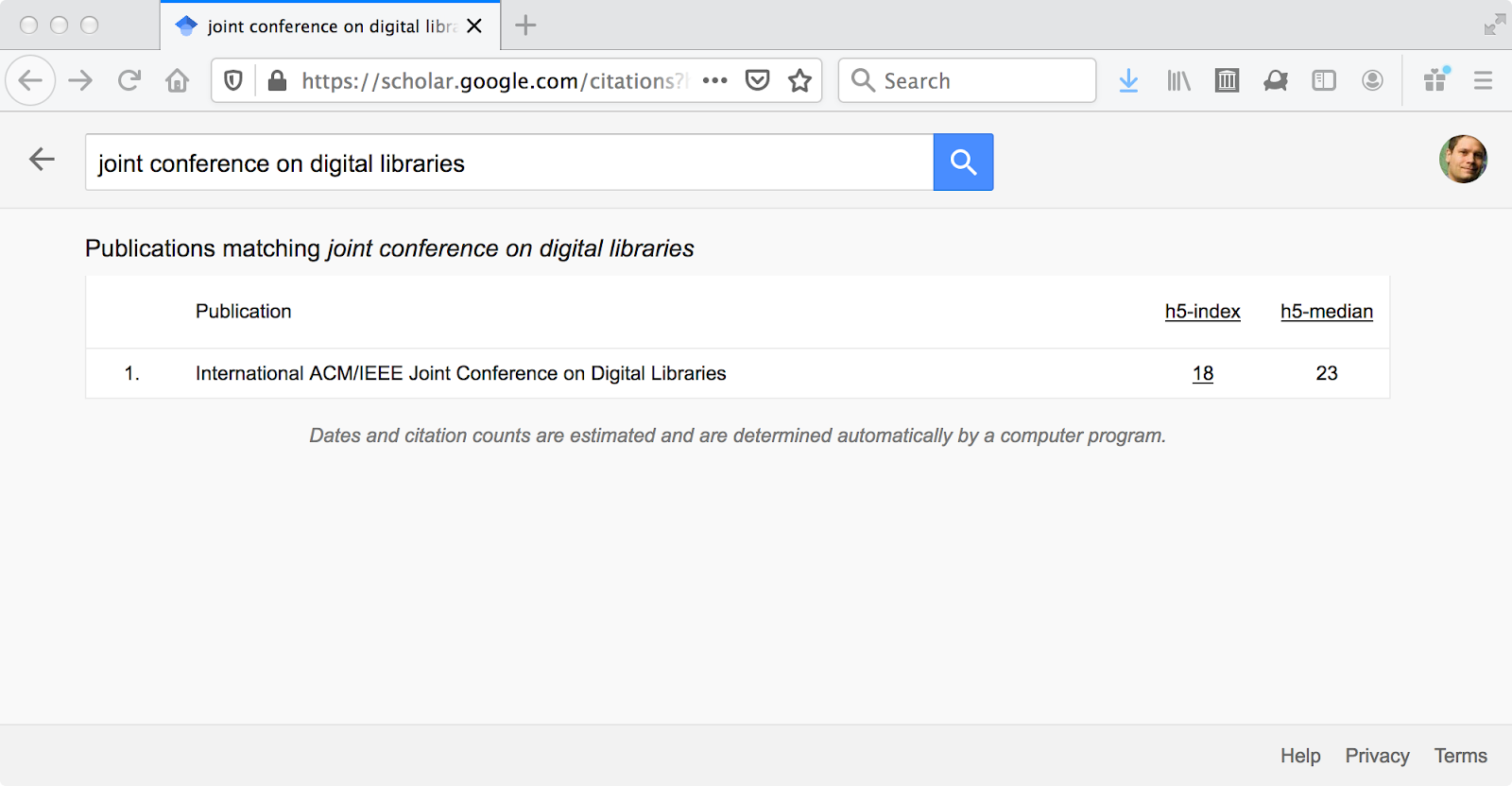
Figure 6: First Monday, Google Scholar https://scholar.google.com/ citations?hl=en&view_op=search_venues&vq=First+Monday&btnG= (from 2020-07-19).
2.2 Innovations in Web-based publishing
As the initial editorial makes clear, D-Lib Magazine was an ongoing experiment in “electronic publishing” itself, and as a result was an early adopter and proof-of-concept for a lot of conventions and techniques that are now best practices in the community. Perhaps most importantly, D-Lib Magazine was always published in HTML – and only in HTML: there was never a parallel PDF version. Submissions were encouraged in MS Word, but the editors handled the conversion to HTML themselves. Adopting an HTML-only publishing strategy seems obvious in retrospect, but considering the limitations of HTML ca. 1995 (cf. HTML5 [1] today) this was a bold strategy. Despite the dominance of the PDF in the scholarly publishing ecosystem, the HTML format allowed authors to experiment with multimedia and interactivity extensions not possible with PDFs. Quoting from the October, 1995 editorial, one gets a glimpse of the willingness to explore the boundaries of what an HTML-only publication could be [32]:
``You will see that the stories have varied in their treatment of images, for example, in the background color, and even in the organization of the text itself. But I do not believe that these individual treatments posed a problem for our readers, partly because the stories are unified by subject, partly because the medium is itself experimental and preconceptions are fairly few, and partly because in each case, the structure of the story reinforces and extends its informational content. Thus, the highly visual story that the Informedia team wrote on indexing video subtly embodies the notion of frames in its file structure. It offers readers multiple paths through the material and cues through buttons not unlike the signage found in museums and airports, and through menus that other writers for the magazine have also employed. In the same issue, the Netlib authors used a classic, straightforward narrative approach with an internal menu to explain the complex structure of a library of mathematical software.’’
As authors, we certainly appreciated the editors’ willingness to explore what new features were possible in an HTML scholarly publication. For example, in our 1999 article about the Universal Preprint Service [113], we included screen cams to show the now defunct ups.cs.odu.edu digital library in action. Those screen cams were stored in .exe format and would thus likely require emulation to run now, but those animations (stored at dlib.org) would not have been possible in a PDF. Another of our articles from 2002 used animations, but this time in a more web-friendly and standard MPEG format [83]. In a 2005 article, we did not use animations, but did have 377 images linked from the article, a feat that would have been unwieldy at best in PDF [17]. Our last article in D-Lib Magazine used JavaScript to make annotated hyperlinks in the article actionable, thereby serving as a demonstration of how “Robust Links” could work in practice [115].
Another significant decision was to fix the template and formatting of past issues, and not reformat earlier issues with updated templates. Updates were only made in the cases of errata and corrigenda1. D-Lib Magazine updated their design as tools and experience allowed, but the first issue looks the same today as it did 25 years ago, thereby serving as a monument to the best practices of the time. Indeed, the live web version of the first issue and the web archived version of the first issue are indistinguishable (Figures 7, 8, 9). Not only did they keep their HTML and style intact, but thanks to an ongoing commitment from CNRI all of D-Lib Magazine’s issues are still available on the live web, with no changes in their URIs since the fourth issue (October, 1995)2. Although we have long known “Cool URIs Don’t Change” [13], the reality is that most do, and persisting over 5,000 URIs for up to 25 years is an accomplishment in itself.

Figure 8: D-Lib Magazine, archived in 1997: https://web.archive.org/web/19971010044705/http://www.dlib.org/dlib/July95/07arms.html.
% date
Mon Jul 13 12:44:38 EDT 2020
% curl -s http://www.dlib.org/dlib/July95/07arms.html | md5sum
3cc0fb32a7fe8f1f4de9a40aa5069cfe -
% curl -s https://web.archive.org/web/19971010044705id_/http://www.dlib.org/dlib/July95/07arms.html | md5sum
3cc0fb32a7fe8f1f4de9a40aa5069cfe -
Figure 9: Using curl to download both the live web version and first archived version (from 1997 and in “raw” format, via id_) and show they produce the same md5 hash.
Another groundbreaking innovation for D-Lib Magazine was that it was open access before that term was even coined, with the authors retaining their copyright, and D-Lib requiring neither subscriptions for readers nor article processing charges from the authors. This ensured it reached a wide audience, both authors and readers, but it also resulted in chronic funding problems after the expiration of the initial grants that supported the D-Lib Forum ended. In an editorial for the ten year anniversary issue [54], Robert Kahn said:
“Producing a high quality magazine on the net each month turned out to be somewhat less difficult than I would have expected, due almost entirely to the quality of the editorial staff and the willingness of the readership to contribute interesting articles. Funding the continued production of the magazine has been, perhaps, its biggest challenge. While the initial funding from DARPA covered most of the early costs, DARPA was unable to continue the support indefinitely. Subsequent funding from NSF helped greatly, but covered perhaps half the ongoing costs, with CNRI picking up the other half.”
Although subscriptions and author fees were considered [64], they were never implemented. In 2007, the “D-Lib Alliance” membership organization was created [126] that assisted with funding, but the final issue in July 2017 acknowledged that decreased financial support was part of the reason for ceasing publication [66]:
“Financial support for the magazine has waned over recent years, the number of unsolicited high quality articles thrown over our transom has declined, and the very phrase 'Digital Libraries' has gone from sounding innovative to sounding a bit redundant. In short, it seemed like time to make a graceful exit.”
Another innovation that resulted from open access HTML-only publishing was D-Lib being the first venue to have its handles (and later DOIs, to be discussed further in section 3.3) resolve to articles themselves, not a landing page describing the article. By eschewing PDF, the format of paywalls, D-Lib Magazine was able to subtly reinforce that its content was part of the Web, and not something separate, to be downloaded via the Web. The ability to link and provide embedded multimedia enables the scholarly object to enjoy the same advances (and risks, such as link rot [49, 57, 75]) as the rest of the web. Another subtle result of embracing handles (and DOIs) is that although D-Lib Magazine was published as a conventional serial, it also embraced persistent identifiers for individual articles (owing from the computer science technical report heritage of CNRI’s technology), which facilitates the disaggregation of serials into articles that are directly and persistently identifiable, which reinforces them as being “on the Web” as first-class citizens.
Another innovation D-Lib Magazine embraced was the use of site mirrors allowing users in Europe and Asia to interact with geographically closer mirrors for faster response. That approach to address bandwidth limitations was common at the time and is now solved via content delivery networks (CDNs). Three of the D-Lib mirrors are still functioning, down from a peak of five. In addition to the utility the mirrors provide, they were also presumably intended as demonstrators for more advanced Handle resolution techniques, such as being able to resolve to one of multiple URLs [93].
2.3 Other contemporary Web-based journals and magazine
There were other contemporary experiments in on-line publishing from generally the same community as well. For example, Ariadne is an online magazine that began publishing in 1996 and is still publishing (78 issues since 1996). It was similarly not peer-reviewed, aimed at practitioners, and was initially funded by the Joint Information Systems Committee (JISC, since renamed Jisc), a UK activity that can be considered roughly analogous to the USA DLI program. Ariadne also had an HTML focus from the very beginning. It has changed publishers a few times, as well as changed its URIs and template through time (Figures 10, 11, 12). It does not use handles or DOIs.

Figure 10: An article from the first issue of Ariadne (published in 1996, archived in 1997 (http://web.archive.org/web/19970413121415/http://www.ariadne.ac.uk/ariadne/issue1/clic/)).
$ curl -I http://www.ariadne.ac.uk/ariadne/issue1/clic/
HTTP/1.1 404 Not Found
Date: Sun, 19 Jul 2020 22:29:16 GMT
Server: Apache/2.4.6 (CentOS) OpenSSL/1.0.2k-fips PHP/7.2.24
Content-Type: text/html; charset=iso-8859-1
Figure 12: The original URI for the first issue of Ariadne is 404.
First Monday began in 1996 as a monthly peer-reviewed journal, and is still being published. But over time, its URIs have changed (from firstmonday.dk to simultaneously firstmonday.org and a path within journals.uic.edu), and its template changed along the way. It uses DOIs, and we believe it adopted them in 2013.
There is more difference in the original First Monday (archived in 1998, Figure 13), the current live Web First Monday (Figure 14), and the inner frame of the live Web First Monday (Figure 15) than first appears, a result of significant reformatting of the articles over time. Figure 16 shows downloading the archived raw version (via id_), the live version, and the inner frame of the live version, respectively. The Unix utility wc (word count) respectively shows the lines, words, and characters of each file, all of which are significantly different.

Figure 13: An article from the first issue of First Monday, archived in 1998 (web.archive.org/web/19980205181322/http://firstmonday.dk/ issues/issue1/ecash/index.html).
Figure 14: A live Web version of the same article: https://journals.uic.edu/ojs/index.php/fm/article/view/465/386.

Figure 15: The inner frame of the live Web version: https://journals.uic.edu/ojs/index.php/fm/article/download/465/386?inline=1.
$ curl -sL web.archive.org/web/19980205181322id_/http://firstmonday.dk/issues/issue1/ecash/index.html > first-monday-old
$ curl -ksL https://journals.uic.edu/ojs/index.php/fm/article/view/465/386 > first-monday-now
$ curl -ksL https://journals.uic.edu/ojs/index.php/fm/article/download/465/386?inline=1 > first-monday-now-frame
$ wc first-monday-*
39 100 1941 first-monday-now
1 4521 34585 first-monday-now-frame
0 4379 32308 first-monday-old
40 9000 68834 total
Figure 16: The word count (wc) utility shows the differences in lines, words, and characters (respectively) for each version of the same article.
The Journal of Digital Information (JoDI) began as a peer-reviewed journal in 1997, and ceased publication in 2013 after irregular publication of 46 issues. While it was active it transitioned from the University of Southampton (jodi.ecs.soton.ac.uk and journals.ecs.soton.ac.uk (the former no longer resolves (Figure 17)) to Texas A&M University and Texas Digital Library (journals.tdl.org). The templates changed through time, and publication was always a hybrid of either HTML or PDF. It did not use handles or DOIs.
The web archives have archived registration walls, since JoDI originally required a (free) account and login to browse. Since the Internet Archive crawls only the surface web (i.e., no login credentials), the end result is the earliest versions of JoDI were not web archived around the time they were published. Eventually the requirement for logins ceased, and the earliest web archived pages without a registration wall are from 2000, including snapshots of the earliest articles created two years after their original publication. In Figure 18, we see an archived landing page for an article from the first issue of JoDI (1997). Clicking through (Figure 19) returns a 404 page from the Internet Archive since that article itself was not archived at that location because of login restrictions. Figure 20 shows an archived copy of that same article, meanwhile available at a different URI, created in 2000 when JoDI had removed the registration wall, and Figure 21 shows the same article now.
% curl -I http://jodi.ecs.soton.ac.uk/
curl: (6) Could not resolve host: jodi.ecs.soton.ac.uk
Figure 17: jodi.ecs.soton.ac.uk no longer resolves.

Figure 18: A landing page for an article from issue 1 (1997), archived in 1998: http://web.archive.org/web/19980715030423/http://jodi.ecs.soton.ac.uk/Abstracts/v01/01.berners-lee.html.
Figure 19: Clicking through to: http://web.archive.org/web/19980715030423/http://jodi.ecs.soton.ac.uk/jodi/Articles/v01/i01/BernersLee/ produces a 404 since this page was not on the surface web in 1998, and since the server jodi.ecs.soton.ac.uk is no longer on the live web, we cannot patch the archive.
Figure 20: In 2000 JoDI changed the URIs and removed login restrictions. http://web.archive.org/web/20000830084738/http://jodi.ecs.soton.ac.uk/Articles/v01/i01/BernersLee/.

Figure 21: The same article on the live web in 2020. https://journals.tdl.org/jodi/index.php/jodi/article/view/3/3.
3 Reflecting on the first issue’s articles
With the vantage point of 25 years, we can properly assess the significance of the first issue of D-Lib Magazine, especially the first three articles they published. Two of the articles introduced technologies that continue to shape the digital library community (Dublin Core and DOIs), and the other article is a testament to the significant funding that the NSF, DARPA, and NASA put into research in digital libraries, with one of the most prominent outcomes being Google [42].
3.1 Dublin Core
The first article, “Metadata: The Foundations of Resource Description” [122], is a summary of the OCLC/NCSA Metadata Workshop Report, which resulted from the workshop in Dublin, Ohio, only four months prior (March, 1995) [123]. The Dublin Core Metadata Element Set (DCMES, or “Dublin Core”) was still forming at this point, with only 13 metadata elements, not the final 15, defined, and “DCMES” becoming the Dublin Core Metadata Initiative (DCMI) Terms. While the DCMI has gone on to issue over 70 specifications, today’s DCMI Terms can trace their origin to the 1995 Metadata Workshop and the original DCMES (Table 1). The impact of Dublin Core is far beyond what we can cover here, but Figure 22 shows a search for “dublin core” in Google yields over 11M hits, and Figure 23 shows a similar search in Google Scholar yields over 98K hits.
Dublin Core would form its own community, complete with its own governance and document series. But D-Lib Magazine would continue to be a venue for conveying the status of Dublin Core [23, 58, 124, 111], and other related Web metadata efforts, such as PICS [78] and its progeny, RDF [77], and IEEE LOM [26].
While Dublin Core is abundantly used for the description of assets in a variety of content management systems, continues to this day to play a role in web-based discovery, co-existing with similar formats such as the Open Graph Protocol [44] (Figure 24) and Schema.org [39] (Figure 25), yet facing some significant competition from the latter when it comes to Search Engine Optimization [47].
Table 1: Original 1995 DC elements and the current terms.
Figure 22: 11M+ hits for a Google search for “dublin core”.
Figure 23: 98K+ hits for a Google Scholar search for “dublin core”.
% curl -s https://www.loc.gov/ | grep 'name=\"dc\.\|property=\"og:'<meta name="dc.identifier"
<meta name="dc.language" content="eng" />
<meta name="dc.source" content="Library of Congress, Washington, D.C. 20540 USA" />
<meta property="og:site_name" content="The Library of Congress"/>
<meta property="og:type" content="article" />
<meta name="dc.title"
<meta property="og:title"
<meta property="og:description" content="The world's largest library. View historic
photos, maps, books and more. Contact experts for help with research. Plan a visit.
Home of U.S. Copyright Office." />
<meta name="dc.rights" content="Text is U.S. Government Work" />
<meta property="og:image" content='http://www.loc.gov/static/images/favicons/open-graph-logo.png' />
<meta property="og:image:secure_url"
content='https://www.loc.gov/static/images/favicons/open-graph-logo.png' />
<meta property="og:image:width" content="1200"/>
<meta property="og:image:height" content="630"/>
Figure 24: The Library of Congress home page with both Dublin Core (dc.) and Open Graph (og:) support.
% curl -s https://search.datacite.org/works/10.5281/zenodo.2597274
<!DOCTYPE html>
<html>
<head>
<title data-conneg='https://api.datacite.org' id='site-title'>
DataCite Search
</title>
<meta content='width=device-width, initial-scale=1.0' name='viewport'>
<link href='//maxcdn.bootstrapcdn.com/font-awesome/4.6.1/css/font-awesome.min.css'
rel='stylesheet' type='text/css'>
<link href='//fonts.googleapis.com/css?family=Raleway:400,600,400italic,600italic'
rel='stylesheet' type='text/css'>
<link href='//cdnjs.cloudflare.com/ajax/libs/cc-icons/1.2.1/css/cc-icons.min.css'
rel='stylesheet' type='text/css'>
<script src='https://unpkg.com/vue/dist/vue.min.js'></script>
<script src='https://unpkg.com/datacite-components/dist/datacite-components.min.js'
type='text/javascript'></script>
<link href='https://assets.datacite.org/stylesheets/datacite.css' rel='stylesheet'
type='text/css'>
<link href='/stylesheets/usage.css' rel='stylesheet' type='text/css'>
<meta name="DC.identifier" content="10.5281/zenodo.2597274" />
<meta name="DC.type" content="work" />
<meta name="DC.publisher" content="Zenodo" />
<meta name="DC.date" content="2018" />
<script type='application/ld+json'>
{
"@context": "http://schema.org",
"@type": "ScholarlyArticle",
"@id": "https://doi.org/10.5281/zenodo.2597274",
"identifier": {
"@type": "PropertyValue",
"propertyID": "URL",
"value": "https://zenodo.org/record/2597274"
},
[deletia]
Figure 25: DataCite using both Dublin Core (in the meta elements) and schema.org (in JSON-LD format).
3.2 DLI and DLI2
The second article, “An Agent-Based Architecture for Digital Libraries” [15], is a high-level summary of the University of Michigan Digital Library (UMDL) project, one of the original six NSF/DARPA/NASA Digital Library Initiative (DLI) projects. The DLI ran from 1994–1998, so the 1995 article only summarizes the earliest results.
The architectural details of the UMDL are academically interesting, but the real value in 2020 is reading the article as a time capsule of 1990s perception of the Web, DLs, and DL architecture. A quote from near the beginning of the article describes a scenario that we have since seen come to pass:
“The WWW, while it probably contains more information than any single traditional library, is arguably not as useful as a traditional library because it lacks these services (particularly organization and sophisticated search support). No one is dismantling their libraries because of the WWW yet.”
The envisioned architecture focuses heavily on agents, which navigate a distributed, heterogeneous tapestry of distributed repositories on behalf of the user. The model of distributed search was dominant in early DL architecture thinking, and was reflected in the design of search protocols like Z39.50 and WAIS, as well as DLs such as WATERS [73], NCSTRL [21], NTRS [86], and many other examples3. The DL commitment to distributed searching on the Web culminated in the STARTS protocol [35], and dissatisfaction with the state of distributed searching DLs (cf. [97, 83]) was at the heart of the Universal Preprint Service prototype that demonstrated metadata harvesting and centralized searching, a design decision that would inform OAI-PMH [113, 114, 62] and later DLs based on it (e.g., [71, 3, 84]).
Typical of the time, the UMDL design is fully committed to distributed search and crawling, with personalized agents handling the foraging and negotiation with the various repositories (similar to CNRI’s Knowbots [55]). After 25 years and with a post-Google perspective, we can now see that most meta-search / distributed search architectures have been retired, in part by the hegemony of Google-style crawling and searching4. In the end, (logically) centralized architectures won. HTTP servers were (and are) broadly distributed, but the complexity of crawling and indexing turned out to be centralized. The search engines now dictate to the web servers how to expose and structure their site, instead of the anticipated model where sites instructed the best way to access their holdings.
The DLI ran from 1994 through 1998, and its $30M supported six projects, each of which is summarized in the one year anniversary issue (July/August 1996) of D-Lib Magazine:
- "The University of Michigan Digital Libraries Research Project" led by the University of Michigan [12]
- "Building the Interspace: Digital Library Infrastructure for a University Engineering Community" led by the University of Illinois [43]
- "The Environmental Electronic Library: A Prototype of a Scalable, Intelligent, Distributed Electronic Library" led by the University of California, Berkeley [88]
- "Informedia: Integrated Speech, Image and Language Understanding for Creation and Exploration of Digital Video Libraries" led by Carnegie Mellon University [120]
- "The Stanford Integrated Digital Library Project" led by Stanford University [89]
- "The Alexandria Project: Towards a Distributed Digital Library with Comprehensive Services for Images and Spatially Referenced Information" led by the University of California, Santa Barbara [30]
DLI2 ran from 1999--2005, and the $55M from the NSF, DARPA, National Library of Medicine, Library of Congress, NASA, and the National Endowment for the Humanities (with additional participation from the National Archives and the Smithsonian Institution) supported 36 projects. Despite the importance of the DLI and DLI2 funding efforts in the early days of the web, very little about DLI and DLI2 remains on the live web outside of what is hosted at dlib.org. Sites like www.dli2.nsf.gov and www.cise.nsf.gov/iis/dli_home.html are no longer on the live web, with only a single page left at nsf.gov to mark 12 years of research and $85M in funding. Although the former pages are accessible in web archives and the individual, specific technical contributions resulting from the DLI work are widely described in the broader literature, D-Lib Magazine was a prime venue for program-level reflection [36, 37, 70, 46, 10, 67, 38, 90].
3.3 KWF and DOIs
The final article from the first issue, “Key Concepts in the Architecture of the Digital Library” [8], was a summary by Bill Arms of “A framework for distributed digital object services”, which would later be known as the “Kahn-Wilensky Framework” (KWF) [51]. Although it is just an abstract framework and not tied to a specific implementation, the KWF has had a significant impact on the architectural design of digital libraries, especially concerning the identification and structure of ‘digital objects” and their relationship with the repositories in which they reside. In 2006, we edited a special issue of the International Journal on Digital Libraries (IJDL) on “Complex Digital Objects” [87], which also featured a reprint and of the KWF along with commentary from Robert Kahn [52].
The KWF provided the architecture for the initial CS-TR project [53], which in combination with WATERS [73] formed the basis for the Dienst protocol and NCSTRL [21] as a distributed digital library for computer science technical reports. Lessons learned from Dienst were incorporated in OAI-PMH [113, 114, 62]. The KWF also had an impact in the Dublin Core community, resulting in the Warwick Framework [60], which was later extended with “distributed active relationships” [20], which itself later evolved into Fedora [95]. The management of Fedora and DSpace [110] were merged into Duraspace in 2009 [80], and in 2019 LYRASIS absorbed Duraspace. The separate Fedora and DSpace open source products continue to be offered.
KWF specified the role of repositories in mediating access to their digital objects via the Repository Access Protocol (RAP). Over the years, numerous papers have been published, many of them in D-Lib Magazine, that pertain to RAP, including [7, 94, 99]. The design of RAP was repository-centric [115] and explicitly decoupled the protocol for expressing interactions with digital objects from the transport protocol used to transfer interaction requests between client and server. Such a choice was not uncommon in the days preceding the dominance of the web and its now omnipresent HTTP protocol and can, for example, also be observed in the design of OAI-PMH [115]. Many transport protocols (TCP, SMTP, FTP, Gopher, HTTP, IIOP, etc.) overlapped in time and there was a predisposition to viewing them as impermanent, interchangeable; something on which one built richer, domain-specific protocols. Also, Roy Fielding did not publish his dissertation about Representational State Transfer (REST), which made the resource-centric [115] semantics and potential of HTTP explicit, until 2000 [27, 29]. By that time, the state of thinking and practice in digital libraries had already diverged from that of the web. In this way, RAP was the initial manifestation of an architectural fault line between digital libraries and the web that continues to this day5. As a prominent example, the FAIR Digital Object effort [22] that fits under the broad umbrella of the European Open Science Cloud program and is supported by activities of the Research Data Alliance, considers two approaches to devise rich interactions with digital objects that are stored in cooperating repositories. One aligns with the RAP line of thought [24]. The other embraces a webby approach and advocates leveraging a range of HTTP-based standards that have become available over the years, including the Open Archives Initiative Object Reuse and Exchange (OAI-ORE) [61] for the representation of digital objects as aggregations of web resources, the Memento Framework [117, 116] for temporal versioning of web resources, Linked Data Platform [108] and the Fedora API [6] for CRUD operations on digital objects and their constituent resources, Web Annotation [103, 101], RO-Crate for packaging digital objects [106]. It is interesting to note that several of these specifications were co-authored by people with roots in the Digital Library community.
The most visible contribution from the KWF is Digital Object Identifiers (DOIs). Handles [63], of which DOIs are a subset, were part of the technical infrastructure for digital libraries built by CNRI. Although frequently considered a URN implementation [100], they are not registered as URN namespaces and their status as URIs remains unresolved [109]. D-Lib Magazine used handles beginning with the first issue, and, as the DOI effort matured, D-Lib Magazine was naturally an early adopter, starting in January, 1999 [125]. Figure 26 shows a current resolution of a handle from Arms’s description of KWF (hdl:cnri.dlib/july95-arms), and Figure 27 shows the resolution of that handle converted to DOI format (doi:10.1045/july95-arms, with: hdl → doi and cnri.dlib → 10.1045). In fact, all DOIs are also resolvable as handles, as Figure 28 shows. But since DOIs are a proper subset of handles, not all handles are resolvable as DOIs (Figure 29).
$ curl -I http://hdl.handle.net/cnri.dlib/july95-arms
HTTP/1.1 302
Location: http://www.dlib.org/dlib/July95/07arms.html
Expires: Tue, 21 Jul 2020 15:30:58 GMT
Content-Type: text/html;charset=utf-8
Content-Length: 171
Date: Mon, 20 Jul 2020 15:30:58 GMT
Figure 26: Resolution of a handle from the first issue of D-Lib Magazine.
% curl -IL https://doi.org/10.1045/july95-arms
HTTP/2 302
date: Mon, 20 Jul 2020 15:55:01 GMT
content-type: text/html;charset=utf-8
content-length: 171
set-cookie: __cfduid=da38cfa9ab1b68408e00ad2c5d8c678541595260501; expires=Wed, 19-Aug-20 15:55:01 GMT; path=/; domain=.doi.org; HttpOnly; SameSite=Lax; Secure
vary: Accept
location: http://www.dlib.org/dlib/July95/07arms.html
expires: Mon, 20 Jul 2020 16:25:51 GMT
cf-cache-status: DYNAMIC
cf-request-id: 040e8894eb0000f11e27b76200000001
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
strict-transport-security: max-age=31536000; includeSubDomains; preload
server: cloudflare
cf-ray: 5b5ddd34add1f11e-IAD
Figure 27: Resolution of a DOI formed from the handle shown in Figure 26.
% curl -I https://doi.org/10.1002/cpe.1594
HTTP/2 302
date: Fri, 24 Jul 2020 17:14:50 GMT
content-type: text/html;charset=utf-8
content-length: 159
set-cookie: __cfduid=d3e73c3df617628234c082278fdcc7f1a1595610890; expires=Sun, 23-Aug-20 17:14:50 GMT; path=/; domain=.doi.org; HttpOnly; SameSite=Lax; Secure
vary: Accept
location: http://doi.wiley.com/10.1002/cpe.1594
expires: Fri, 24 Jul 2020 17:20:12 GMT
cf-cache-status: DYNAMIC
cf-request-id: 04236b1a080000031614326200000001
expect-ct: max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/expect-ct"
strict-transport-security: max-age=31536000; includeSubDomains; preload
server: cloudflare
cf-ray: 5b7f47a34c260316-IAD
% curl -I http://hdl.handle.net/10.1002/cpe.1594
HTTP/1.1 302
Vary: Accept
Location: http://doi.wiley.com/10.1002/cpe.1594
Expires: Fri, 24 Jul 2020 18:03:23 GMT
Content-Type: text/html;charset=utf-8
Content-Length: 159
Date: Fri, 24 Jul 2020 17:15:08 GMT
Figure 28: All DOIs are also handles.
% curl -I https://www.doi.org/cnri.dlib/july95-arms
HTTP/1.1 404 Not Found
Content-Type: text/html
Content-Length: 3065
Connection: keep-alive
Last-Modified: Wed, 01 Mar 2017 01:16:05 GMT
Server: AmazonS3
Date: Thu, 06 Aug 2020 13:28:05 GMT
ETag: "39bf1abd89479be3047e0cc48f631b42"
Vary: Accept-Encoding
X-Cache: Error from cloudfront
Via: 1.1 6784ac36b8d920a78daf15294a50025f.cloudfront.net (CloudFront)
X-Amz-Cf-Pop: IAD79-C3
X-Amz-Cf-Id: oPtjDhhUnKYjw4pCALyY5ECCPcQeuRd5lyl40T6mUTzd5HefGSnIWQ==
Age: 1988
Figure 29: Not all handles are DOIs.
4 Progress over 25 years
The last part of the first issue we would like to review is a page entitled “To the editor: What’s needed in future research?”, in which the D-Lib editors polled five prominent digital library researchers and administrators and asked them to briefly identify and discuss areas that warranted further research. Although the purpose was to generate discussion about a near-term research agenda (and perhaps establish D-Lib Magazine’s credentials through adding additional voices to the first issue), this page now serves as a time capsule and allows us to reassess progress in the field since 1995. In the page the editors stated “Now, we would like to know what you think; send [us] your thoughts, reactions, and comments”, which we now do 25 years later.
"An interoperable national and global information web" -- Barry M. Leiner, Deputy Director, ARPA/CSTO
The world-wide web technology, infrastructure, and protocols that Barry Leiner credited for an explosion in the availability of accessible and viewable information have persisted and have given rise to a global networked environment that we can hardly imagine living without anymore. Over time, numerous open standards have been specified to support interoperability beyond the basic level provided by the core ingredients of the web, HTTP and HTML. In the Web 2.0 era, some of these acted as catalysts for the frictionless creation of value-added services across web platforms, both for and not for profit. But since interoperability is not a significant concern for companies that want to protect their turf or establish monopolies, a trend has emerged to support rich access by means of bespoke APIs rather than open protocols, significantly increasing the investment for the development and management of services that require cross-platform interactions. This trend has become so prominent that platforms routinely claim to be interoperable because they expose a self-defined API, and, to add insult to injury, touting its RESTful-ness while many times it is not [28].
In the digital library community, the dream to achieve interoperability based on open standards remains alive and actively pursued. Despite the aforementioned ongoing debate regarding which path to take – repository-centric or resource-centric – most community driven specification efforts of the past decade have chosen to embrace the ways of the web, many times aiming for approaches that have applicability beyond the digital library community. In the realm of technologies to support digital libraries of multimedia information on which Barry Leiner zoomed in, prominent examples include the Fedora API [6] that leverages the W3C Linked Data Platform recommendation [108], the W3C Web Annotation recommendations [103, 101], and the specifications that resort under the International Image Interoperability Framework. Because of its growing global adoption by GLAM institutions, especially the latter stands as a testimony that rich interoperability for distributed resource collections is effectively achievable. But other promising specifications that aim for the same holy grail are struggling for adoption, and, many times, lack of resources is mentioned as a reason. While that undoubtedly plays a role, it did not stand in the way of rapid adoption of protocols that have emerged from large corporations, such as the Google-dominated [5] schema.org. This consideration re-emphasizes that a core ingredient of a successful interoperability specification, and hence of achieving an interoperable global information web, is a large megaphone, either in the guise of commercial power or active community engagement [102].
"Integration between electronic and non-electronic forms of communications and publications" -- Ann L. Okerson, Director, Office of Scientific & Academic Publishing, Association of Research Libraries (ARL)
The dichotomy between print and digital resources that Ann Okerson describes was a major concern in the mid nineties. Despite large-scale digitization efforts (see below) and the exponential growth of born-digital materials, analog collections will remain. But these worlds are no longer perceived as being radically distinct because the analog world has largely been absorbed by the digital one. This did not necessarily happen by making both discoverable through library OPACs. Rather, it has become commonplace to cater to the crawl-driven discovery paradigm of major search engines by exposing resource descriptions for materials of both types of collections to the web using Search Engine Optimization techniques such as the Sitemap protocol and, more recently, schema.org. For many analog GLAM collections doing so requires making traditional catalog systems web savvy, a task that is still ongoing. So while “electronic and non-electronic forms of communications and publications” will remain parallel worlds for the foreseeable future, the percentages have shifted, as Lannom’s note from the final D-Lib editorial makes clear: “the very phrase ‘Digital Libraries’ has gone from sounding innovative to sounding a bit redundant.” [66]
"'Foreground' information stores, or personal digital libraries" -- William L. Scherlis, Senior Research Computer Scientist, Department of Computer Science, Carnegie Mellon University
The personal digital libraries envisioned in this piece have not become mainstream. Instead creators have embraced a myriad of web productivity portals to share both their intellectual artifacts and daily activities. As a result, assets created by individuals and information pertaining to their comings and goings are distributed across the web, to such an extent that both research (e.g., [40]) and development efforts have considered approaches to aggregate it into a personal environment that provides a concise representation of the self on the distributed web. In the realm of scholarly communication, the experimental myresearch.institute effort tracks, collects, and archives assets created by researchers in a variety of web portals, including GitHub, Slideshare, Wikipedia. The plethora of APIs used by these portals and the lack of support for protocols such as W3C ActivityPub [121] and W3C ActivityStreams2 [107] make such an aggregation task far from trivial. The result of gathering the distributed information could be considered a proxy personal digital library. But maybe the days of the actual personal digital library are still to come. Motivated and frustrated by the monopolies certain web portals have established over the years, and the concerns regarding privacy and data abuse that result, the Decentralized Web movement is aiming for alternatives, with a focus on giving individuals back control over their personal assets. As part of this movement, the Solid effort led by Tim Berners-Lee introduces the notion of a pod [14], a personal storage space that complies with a stack of open standards and allows its owner to grant or deny applications and users access rights to stored resources. Clearly, these pods are conceived as a technology that can help information producers manage foreground information, to put it in the words of William L. Scherlis.
"Diversifying and access" and "the distribution chain" -- Paul Evan Peters, Executive Director, Coalition for Networked Information
As far as “diversifying and access”, we believe Peters is criticizing researchers’ emphasis on the “attributes of the resources and services”, as manifested in Leiner’s assessment, as well as the prevalent distributed searching paradigm described in section 3.3, and instead we should be focusing on the “attributes of the users and uses”, which we interpret to be in harmony with Scherlis’s vision of personal DLs. Most siloed repositories have been flattened and exposed for crawling by search engines. Google, for example, showed little appetite for even simple protocols such as OAI-PMH [76, 41], and officially retired support for it in 2008 [81].
Initially we struggled with understanding Peters’s description of “the distribution chain.” Eventually we decided that part of the ambiguity is that he is describing something that is so common now but for which the language did not exist in 1995, resulting in a terminology gap that we had to bridge to understand what he meant. When he says we need to focus on “closing the gap between creators and users of resources and services”, we understand that to be an admonishment that the point of DLs should not be merely the automation of the existing publication process. Unfortunately, 2020 still resembles 1995, with the distribution chain largely paralleling the value chain, just now with PDFs instead of paper. Instead of reenvisioning / reengineering the scholarly communication process (e.g., [118]), we have a confusing array of open access options (“gold”, “green”, “hybrid”, etc.) and by retaining the publisher at the center of distribution, they still fail to address the broader needs of scholarly communication (e.g., [18]).
We have now long had the ability to “link creators and users” as Peters’s calls for, but have lacked the collective will to make the transition [19, 112]. Web 2.0, blogs, and social media provided some hope initially, but as noted in section 4, platforms have since moved away from Atom and RSS in favor of bespoke APIs that provide more functionality at the expense of interoperability. Add to this Elsevier buying various platforms that “link creators and users” (e.g., SSRN [96], Mendeley [72], bepress [105], and Peters’s vision, while technically feasible, seems no closer than it did in 1995.
"Retrospective capture of content" -- James Michalko, President, The Research Libraries Group, Inc.
Michalko, in a statement that aligns with Okerson’s, observes “[t]here’s a major opportunity and demand for the retrospective capture of content”, but in 1995 “[t]here are few service bureaus that can do the scanning and capture of maps, manuscripts, and other primary research materials.” However, Michalko was writing at a time when these projects either did not exist or were just beginning: JSTOR [104], Google Books [68], Open Content Alliance [50], Internet Archive [56], HathiTrust [129], National Digital Newspaper Program [2], museum mass digitization projects [98], etc. Mass digitization of primary research materials remains incomplete, and it is not always clear how the digitized models will fit within a search engine-centric model of crawling and searching. But the momentum is there, and what is digitized exists at a scale that we could only dream of in 1995.
5 Conclusions
D-Lib Magazine was published from 1995 through 2017. During this time, it helped shape the digital library community, via the information published in articles, the ancillary awareness and informational updates now largely provided by social media, and as an ongoing experiment in web(-only) publishing. Although it ceased publication three years ago, the entire site is still on the live web as an unchanged time capsule, and as a serial it still accrues many citations. The 1,062 articles and 5,000+ web pages available at www.dlib.org offer many opportunities for reflection about the DL community, but we took the first issue as our point of reference to review the last 25 years.
Of the three articles in the first issue, all were summaries of work described elsewhere. However, only the article about the DLI-funded UMDL project summarized information in conventional, peer-reviewed publications. The other two articles, about Dublin Core and the Kahn-Wilensky Framework, summarized “unpublished” (i.e., grey literature) reports, providing a more formal and citable surrogate for standards, practitioner, engineering work that was crucial in the early days of DLs, which the conventional, peer-reviewed publication venues would largely ignore.
D-Lib Magazine would cease publishing due in part to an unsustainable funding model, the maturity of the field, and the rise of blogs and social media. However, its role in shaping the then emerging DL community is hard to overstate. Given the perspective of 25 years, one would be hard pressed to retroactively construct a more prescient first issue: Dublin Core is an ongoing initiative and suite of standards that DLs and the general web still employ today, the $30M from the DLI bootstrapped the DL community and eventually gave us Google, and the Kahn-Wilensky Framework have influenced the design of repositories (e.g., Fedora), interoperability (e.g., OAI-PMH), and provided the proof-of-concept to help launch the DOI ecosystem that provides a fundamental level of interoperability across scholarly publishing.
Acknowledgements
We would like to thank everyone who contributed to D-Lib Magazine’s success, first of which is Robert Kahn, who applied the resources of CNRI (and DARPA) to make D-Lib Magazine possible. We appreciate the work of all the editors through the years: Bill Arms, Amy Friedlander, Barry Leiner, Bonnie Wilson, Peter Hirtle, Allison Powell, Larry Lannom, and Cathy Rey.
We are grateful that D-Lib Magazine existed during the maturation of the field of digital libraries as well as during the pivotal points in our respective careers. Although we are happy to publish this paper as both an arXiv eprint and a blog post, we note with a tinge of sadness that this paper would have been best suited for publication in D-Lib Magazine.
Notes
- Although we thought we remembered this policy being explicitly stated somewhere, we could find no record of it. In emails with former editors Larry Lannom and Cathy Rey, neither could recall such a document. The closest we could find was “Once the issue has been released, only vital corrections or changes will be made to the file. These changes will be noted and dated at the end of the file.” in the Author Guidelines: http://web.archive.org/web/20000613151426/http://www.dlib.org/dlib/author-guidelines.html.
- The first three issues were published at http://www.cnri.reston.va.us/home/dlib.html (cf. https://www3.wcl.american.edu/cni/9507/6207.html), and it was not until the October, 1995 issue that www.dlib.org was adopted (“Please note that D-Lib has a new address: http://www.dlib.org” – http://www.dlib.org/dlib/october95/10contents.html).
- An excellent review of the complex relationship between DLs and the Web is Carl Lagoze’s 2010 dissertation, “Lost Identity: The Assimilation Of Digital Libraries Into The Web” [59].
References
- [1] P. Aas, S. Dixit, T. Eden, S. Faulkner, B. Lawson, S. Moon, and X. Wu. HTML 5.3, 2018. W3C Working Draft, 18 October 2018. https://www.w3.org/TR/html53/.
- [3] H. Anan, X. Liu, K. Maly, M. Nelson, M. Zubair, J. C. French, E. Fox, and P. Shivakumar. Preservation and transition of NCSTRL using an OAI-based architecture. In JCDL ’02: Proceedings of the 2nd ACM/IEEE-CS Joint Conference on Digital Libraries, pages 181–182, 2002. https://doi.org/10.1145/544220.544256.
- [4] M. Andreessen and E. Bina. NCSA Mosaic: a global hypermedia system. Internet Research, 4(1):7–17, 1994. https://doi.org/10.1108/10662249410798803.
- [5] M. Andrews. Time to end Google’s domination of schema.org, 2020. https://storyneedle.com/time-to-end-googles-domination-of-schema-org/.
- [6] B. Armintor, E. C. D. Lamb, S. Warner, and A. Woods. Fedora API Specification 1.0, 2018. Candidate Recommendation 21 November 2018. https://fcrepo.github.io/fcrepo-specification/.
- [7] W. Arms, C. Blanchi, and E. Overly. An Architecture for Information in Digital Libraries. D-Lib Magazine, 3(2), 1997. http://hdl.handle.net/cnri.dlib/february97-arms.
- [8] W. Y. Arms. Key concepts in the architecture of the digital library. D-Lib Magazine, 1(1), 1995. http://hdl.handle.net/cnri.dlib/july95-arms.
- [9] W. Y. Arms. From the Publisher: Scholarly Communication, Digital Libraries, and D-Lib Magazine. D-Lib Magazine, 5(4), 1999. https://doi.org/10.1045/april99-editorial.
- [10] W. Y. Arms. Editorial: The European Connection. D-Lib Magazine, 6(7/8), 2000. https://doi.org/10.1045/july2000-editorial.
- [11] W. Y. Arms. A viewpoint analysis of the digital library. D-Lib Magazine, 11(7/8), 2005. https://doi.org/10.1045/july2005-arms.
- [12] D. E. Atkins. The University of Michigan Digital Library Project: The Testbed. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-atkins.
- [14] T. Berners-Lee. Socially aware cloud storage, 2009. https://www.w3.org/DesignIssues/CloudStorage.html.
- [15] W. P. Birmingham. An agent-based architecture for digital libraries. D-Lib Magazine, 1(1), 1995. https://hdl.handle.net/cnri.dlib/july95-birmingham.
- [16] D. A. Black. Introducing HyperNews. Linux Journal, (27), 1996. https://www.linuxjournal.com/article/1281.
- [17] J. Bollen, M. L. Nelson, G. Manepalli, G. Nandigam, and S. Manepalli. Trend Analysis of the Digital Library Community. D-Lib Magazine, 11(1), 2005. https://doi.org/10.1045/january2005-bollen.
- [18] B. Bremb. Scholarship has bigger fish to fry than access, 2019. http://bjoern.brembs.net/2019/10/scholarship-has-bigger-fish-to-fry-than-access.
- [19] S. Capadisli. Linked Research on the Decentralised Web. PhD thesis, University of Bonn, 2020. http://hdl.handle.net/20.500.11811/8352.
- [20] R. Daniel Jr and C. Lagoze. Extending the Warwick Framework. D-Lib Magazine, 3, 1997. http://hdl.handle.net/cnri.dlib/november97-daniel.
- [21] J. R. Davis and C. Lagoze. NCSTRL: Design and deployment of a globally distributed digital library. Journal of the American Society for Information Science, 51(3):273–280, 2000. https://doi.org/10.1002/(SICI)1097-4571(2000)51:3%3C273::AID-ASI6%3E3.0.CO;2-6.
- [22] K. De Smedt, D. Koureas, and P. Wittenburg. FAIR digital objects for science: From data pieces to actionable knowledge units. Publications, 8(2), 2020. https://doi.org/10.3390/publications8020021.
- [23] L. Dempsey and S. L. Weibel. The Warwick Metadata Workshop: A Framework for the Deployment of Resource Description. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/january96-weibel.
- [24] DONA Foundation. Digital Object Interface Protocol Specification Version 2.0, 2018. https://www.dona.net/sites/default/files/2018-11/DOIPv2Spec_1.pdf.
- [25] J. J. Dongarra and E. Grosse. Distribution of mathematical software via electronic mail. Communications of the ACM, 30(5):403–407, 1987. https://doi.org/10.1145/22899.22904.
- [26] E. Duval, W. Hodgins, S. Sutton, and S. L. Weibel. Metadata Principles and Practicalities. D-Lib Magazine, 8(4), 2002. https://doi.org/10.1045/april2002-weibel.
- [27] R. T. Fielding. Architectural Styles and the Design of Network-based Software Architectures. PhD thesis, University of California, Irvine Department of Computer Science, 2000. http://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm.
- [28] R. T. Fielding. REST APIs must be hypertext-driven, 2008. https://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven.
- [29] R. T. Fielding and R. N. Taylor. Principled design of the modern web architecture. ACM Transactions on Internet Technology (TOIT), 2(2):115– 150, 2002. https://doi.org/10.1145/337180.337228.
- [30] J. Frew, M. Freeston, R. B. Kemp, J. Simpson, T. Smith, A. Wells, and Q. Zheng. The Alexandria Digital Library Testbed. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-frew.
- [31] A. Friedlander. From the Editor: A Word (or Two) of Welcome. D-Lib Magazine, 1(1), 1995. https://hdl.handle.net/cnri.dlib/july95-friedlander.
- [32] A. Friedlander. From the Editor: Where Are We in Space? D-Lib Magazine, 1(4), 1995. http://hdl.handle.net/cnri.dlib/october95-friedlander.
- [33] C. L. Giles, K. D. Bollacker, and S. Lawrence. CiteSeer: An automatic citation indexing system. In Proceedings of the third ACM conference on Digital libraries, pages 89–98, 1998. https://doi.org/10.1145/276675.276685.
- [34] P. Ginsparg. First steps towards electronic research communication. Computers in Physics, 8(4):390–396, 1994. https://doi.org/10.1063/1.4823313.
- [35] L. Gravano, C. Chang, H. Garc ́ıa-Molina, and A. Paepcke. STARTS: Stanford proposal for Internet meta-searching. In Proceedings of the 1997 ACM SIGMOD international conference on Management of data, pages 207–218, 1997. https://doi.org/10.1145/253260.253299.
- [36] S. M. Griffin. NSF/DARPA/NASA Digital Libraries Initiative: A Program Manager’s Perspective. D-Lib Magazine, 4(7/8), 1998. https://hdl.handle.net/cnri.dlib/july98-griffin.
- [37] S. M. Griffin. Digital Libraries Initiative - Phase 2: Fiscal Year 1999 Awards. D-Lib Magazine, 5(7/8), 1999. https://doi.org/10.1045/july99-griffin.
- [38] S. M. Griffin. Funding for Digital Libraries Research: Past and Present. D-Lib Magazine, 11(7/8), 2005. https://doi.org/10.1045/july2005-griffin.
- [39] R. V. Guha, D. Brickley, and S. Macbeth. Schema.org: evolution of structured data on the web. Communications of the ACM, 59(2):44–51, 2016. https://doi.org/10.1145/2857274.2857276.
- [40] A. Guy. The Presentation of Self on a Decentralised Web. PhD thesis, University of Edinburgh, 2017. http://hdl.handle.net/1842/29537.
- [41] K. Hagedorn and J. Santelli. Google Still Not Indexing Hidden Web URLs. D-Lib Magazine, 14(7/8), 2008. https://doi.org/10.1045/july2008-hagedorn.
- [42] D. Hart. On the Origins of Google, 2004. https://www.nsf.gov/discoveries/disc_summ.jsp?cntn_id=100660.
- [43] S. L. Harum, W. H. Mischo, and B. R. Schatz. Federating Repositories of Scientific Literature: An Update on the Digital Library Initiative at the University of Illinois at Urbana-Champaign. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-harum.
- [44] A. Haugen. The Open Graph Protocol design decisions. In International Semantic Web Conference, pages 338–338. Springer, 2010. https://doi.org/10.1007/978-3-642-17749-1_25.
- [45] M. V. Heyningen. The unified computer science technical report index: Lessons in indexing diverse resources. In Proceedings of the Second International World Wide Web Conference, pages 535–543, 1994. http://archive.ncsa.uiuc.edu/SDG/IT94/Proceedings/Day/vanheyningen/paper.html.
- [46] P. B. Hirtle. Editorial: A New Generation of Digital Library Research. D-Lib Magazine, 5(7/8), 1999. https://doi.org/10.1045/july99-editorial.
- [47] howard-go. Dublin Core vs Schema.org: A Head-To-Head Metadata Comparison, 2015. https://seopressor.com/blog/dublin-core-vs-schemaorg-metadata-comparison/.
- [48] Y. Jayawardana and G. Jayawardena. Joint Conference on Digital Libraries (JCDL) 2020 Trip Report, 2020. https://ws-dl.blogspot.com/2020/08/2020-08-16-joint-conference-on-digital.html.
- [49] S. M. Jones, H. Van de Sompel, H. Shankar, M. Klein, R. Tobin, and C. Grover. Scholarly context adrift: three out of four URI references lead to changed content. PloS one, 11(12):e0167475, 2016. https://doi.org/10.1371/journal.pone.0171057.
- [50] B. Kahle. Announcing the Open Content Alliance, 2005. http://www.ysearchblog.com/archives/000192.html.
- [51] R. Kahn and R. Wilensky. A framework for distributed digital object services. Technical Report cnri.dlib/tn95-1, CNRI, 1995. http://www.cnri.reston.va.us/home/cstr/arch/k-w.html.
- [52] R. Kahn and R. Wilensky. A framework for distributed digital object services. International Journal on Digital Libraries, 6(2):115–123, 2006. https://doi.org/10.1007/s00799-005-0128-x.
- [53] R. E. Kahn. An Introduction to the CS-TR Project, 1995. http://www.cnri.reston.va.us/home/describe.html.
- [54] R. E. Kahn. Ten Years of D-Lib Magazine and Counting. D-Lib Magazine, 11(7/8), 2000. https://doi.org/10.1045/july2005-editorial.
- [55] R. E. Kahn and V. G. Cerf. An open architecture for a digital library system and a plan for its development. Technical report, Corporation for National Research Initiatives, 1988. https://www.cnri.reston.va.us/kahn-cerf-88.pdf.
- [56] J. Kaplan. Over 1 million digital books now available free to the blind and print-disabled, 2010. http://blog.archive.org/2010/05/06/over-1-million-digital-books-now-available-free-to-the-blind-and-print-disabled/.
- [57] M. Klein, H. Van de Sompel, R. Sanderson, H. Shankar, L. Balakireva, K. Zhou, and R. Tobin. Scholarly context not found: one in five articles suffers from reference rot. PloS one, 9(12):e115253, 2014. https://doi.org/10.1371/journal.pone.0115253.
- [58] C. Lagoze. The Warwick Framework: A Container Architecture for Diverse Sets of Metadata. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-lagoze.
- [59] C. Lagoze. Lost Identity: The Assimilation Of Digital Libraries Into The Web. PhD thesis, Cornell University, 2010. https://hdl.handle.net/1813/14813.
- [61] C. Lagoze, H. Van de Sompel, P. Johnston, M. Nelson, R. Sanderson, and S. Warner. ORE Specification and User Guide - Table of Contents, 2008. http://www.openarchives.org/ore/1.0/toc.
- [62] C. Lagoze, H. Van de Sompel, M. L. Nelson, and S. Warner. The Open Archives Initiative Protocol for Metadata Harvesting, 2002. http://www.openarchives.org/OAI/openarchivesprotocol.html.
- [64] L. Lannom. D-Lib Funding. D-Lib Magazine, 12(7/8), 2006. https://doi.org/10.1045/july2006-editorial.
- [65] L. Lannom. Editorial: Twenty Years and Counting. D-Lib Magazine, 21(7/8), 2015. https://doi.org/110.1045/july2015-editorial.
- [66] L. Lannom. Editorial: The End of an Era. D-Lib Magazine, 23(7/8), 2017. https://doi.org/10.1045/july2017-editorial.
- [67] R. L. Larsen. Whence Leadership? D-Lib Magazine, 11(7/8), 2005. https://doi.org/10.1045/july2005-larsen.
- [68] H. Lee. 15 years of Google Books, 2019. https://www.blog.google/products/search/15-years-google-books/.
- [69] M. Lesk. The CORE electronic chemistry library. In Proceedings of the 14th annual international ACM SIGIR conference on Research and development in information retrieval, pages 93–112, 1991. https://doi.org/10.1145/122860.122870.
- [70] M. Lesk. Perspectives on DLI-2 - Growing the Field. D-Lib Magazine, 5(7/8), 1999. https://doi.org/10.1045/july99-lesk.
- [71] X. Liu, K. Maly, M. Zubair, and M. L. Nelson. Arc-An OAI Service Provider for Digital Library Federation. D-Lib Magazine, 7(4), 2001. https://doi.org/10.1045/april2001-liu.
- [72] I. Lunden. For 69M −100M Data Efforts, Confirmed: Elsevier Has Bought Mendeley To Expand Its Open, Social Education 2013. https://techcrunch.com/2013/04/08/confirmed-elsevier-has-bought-mendeley-for-69m-100m-to-expand-open-social-education-data-efforts/.
- [73] K. Maly, J. French, E. Fox, and A. Selman. Wide area technical report service: technical reports online. Communications of the ACM, 38(4):45, 1995. https://doi.org/10.1145/205323.205330.
- [74] M. I. Mauldin. Lycos: Design choices in an internet search service. IEEE Expert, 12(1):8–11, 1997. https://doi.org/10.1109/64.577466.
- [75] F. McCown, S. Chan, M. L. Nelson, and J. Bollen. The availability and persistence of web references in D-Lib Magazine. In 5th International Web Archiving Workshop (IWAW’05), September 2005. http://www.iwaw.net/05/papers/iwaw05-mccown1.pdf.
- [76] F. McCown, X. Liu, M. L. Nelson, and M. Zubair. Search engine coverage of the OAI-PMH corpus. IEEE Internet Computing, 10(2), 2006. https://doi.org/10.1109/MIC.2006.41.
- [77] E. Miller. An Introduction to the Resource Description Framework. D-Lib Magazine, 4(5), 1998. https://doi.org/10.1045/may98-miller.
- [78] J. S. Miller. W3C and Digital Libraries. D-Lib Magazine, 2(11), 1996. https://hdl.handle.net/cnri.dlib/november96-miller.
- [79] W. H. Mischo. Digital libraries: Challenges and influential work. D-Lib Magazine, 11(7/8), 2005. https://doi.org/10.1045/july2005-mischo.
- [80] C. M. Morris. Doing So Much More: The Fourth Annual International Conference on Open Repositories (OR09). D-Lib Magazine, 15(7/8), 2009. https://doi.org/10.1045/july2009-morris.
- [81] J. Mueller. Retiring support for OAI-PMH in Sitemaps, 2008. https://webmasters.googleblog.com/2008/04/retiring-support-for-oai-pmh-in.html.
- [82] M. L. Nelson. Report on the Third ACM/IEEE Joint Conference on Digital Libraries (JCDL). D-Lib Magazine, 9(7/8), 2003. https://doi.org/10.1045/july2003-nelson.
- [83] M. L. Nelson and B. D. Allen. Object persistence and availability in digital libraries. D-Lib Magazine, 8(1), 2002. https://doi.org/10.1045/january2002-nelson.
- [84] M. L. Nelson, J. R. Calhoun, and C. E. Mackey. The OAI-PMH NASA technical report server. In JCDL ’04: Proceedings of the 4th ACM/IEEE-CS Joint Conference on Digital Libraries, page 400, 2004. https://doi.org/10.1145/996350.996466.
- [85] M. L. Nelson and G. L. Gottlich. Electronic document distribution: Design of the anonymous FTP Langley Technical Report Server. Technical Report NASA TM-4567, NASA Langley Research Center, 1994. http://hdl.handle.net/2060/19940023070.
- [86] M. L. Nelson, G. L. Gottlich, D. J. Bianco, S. S. Paulson, R. L. Binkley, Y. D. Kellogg, C. J. Beaumont, R. B. Schmunk, M. J. Kurtz, A. Accomazzi, and O. Syed. The NASA technical report server. Internet Research: Electronic Network Applications and Policy, 5(2):25–36, 1995. https://doi.org/10.1108/10662249510094768.
- [87] M. L. Nelson and H. Van de Sompel. IJDL special issue on complex digital objects: Guest editors’ introduction. International Journal on Digital Libraries, 6(2):113–114, 2006. https://doi.org/10.1007/s00799-005-0127-y.
- [88] V. Ogle and R. Wilensky. Testbed Development for the Berkeley Digital Library Project. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-ogle.
- [89] A. Paepcke. Summary of Stanford’s Digital Library Testbed Design and Status. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-paepcke.
- [90] A. Paepcke, H. Garcia-Molina, and R. Wesley. Dewey Meets Turing: Librarians, Computer Scientists, and the Digital Libraries Initiative. D-Lib Magazine, 11(7/8), 2005. https://doi.org/10.1045/july2005-paepcke.
- [91] T. K. Park. D-Lib Magazine: Its First 13 Years. D-Lib Magazine, 16(1/2), 2010. https://doi.org/10.1045/january2010-park.
- [92] N. Paskin. DOI: Current Status and Outlook. D-Lib Magazine, 5(5), 1999. https://doi.org/10.1045/may99-paskin.
- [94] S. Payette, C. Blanchi, C. Lagoze, and E. A. Overly. Interoperability for Digital Objects and Repositories: The Cornell/CNRI Experiments. D-Lib Magazine, 5(5), 1999. https://doi.org/10.1045/may99-payette.
- [95] S. Payette and C. Lagoze. Flexible and extensible digital object and repository architecture (FEDORA). In ECDL ’98: Proceedings of the Second European Conference on Research and Advanced Technology for Digital Libraries, pages 41–59, 1998. https://doi.org/10.1007/3-540-49653-X_ 4.
- [96] G. H. Pike. Elsevier buys SSRN.com: What it means for scholarly publication. Technical Report SSRN 2963709, 2016. https://doi.org/10.2139/ssrn.2963709.
- [97] A. Powell and J. French. Growth and server availability of the NCSTRL digital library. In Proceedings of the fifth ACM conference on Digital libraries, pages 264–265, 2000. https://doi.org/10.1145/336597.336696.
- [99] S. Reilly and R. Tupelo-Schneck. Digital object repository server: A component of the digital object architecture. D-Lib Magazine, 16(1/2), 2010. https://doi.org/10.1045/january2010-reilly.
- [100] P. Saint-Andre and J. Klensin. Uniform Resource Names (URNs), Internet RFC 8141, 2017. http://tools.ietf.org/html/rfc8141.
- [101] R. Sanderson. Web Annotation Data Model, 2017. W3C Recommendation 23 February 2017. https://www.w3.org/TR/annotation-protocol/.
- [102] R. Sanderson. Keynote: Standards and communities: Connected people, consistent data, usable applications. In 2019 ACM/IEEE Joint Conference on Digital Libraries (JCDL),
pages 28–28, 2019. https://www.slideshare.net/azaroth42/standards-and-communities-connected-people-consistent-data-usable-applications. - [103] R. Sanderson, P. Ciccarese, and B. Young. Web Annotation Data Model, 2017. W3C Recommendation 23 February 2017. https://www.w3.org/TR/annotation-model/.
- [105] R. C. Schonfeld. Elsevier acquires bepress, 2017.
https://scholarlykitchen.sspnet.org/2017/08/02/elsevier-acquires-bepress/. - [106] P. Sefton, E. Carragi, S. Soiland-Reyes, O. Corcho, D. Garijo, R. Palma, F. Coppens, C. Goble, J. M. Fernnde, K. Chard, J. M. Gomez-Perez, M. R. Crusoe, I. Eguinoa, N. Juty, K. Holmes, J. A. Clark, S. Capella-Gutierrez, A. J. G. Gray, S. Owen, A. R. Williams, G. Tartari, F. Bacall, and T. Thelen. RO-Crate Metadata Specification 1.0, 2019. https://w3id.org/ro/crate/1.0.
- [107] J. M. Snell and E. Prodromou. Activity Streams 2.0, 2017. W3C Recommendation 23 May 2017. https://www.w3.org/TR/activitystreams-core/.
- [108] S. Speicher, J. Arwe, and A. Malhotra. Linked Data Platform 1.0, 2015. W3C Recommendation 26 February 2015. https://www.w3.org/TR/ldp/.
- [109] S. Sun, S. Reilly, L. Lannom, and J. Petrone. Handle System Protocol (ver 2.1) Specification, Internet RFC 3652, 2017. http://tools.ietf.org/html/rfc3652.
- [110] R. Tansley, M. Bass, D. Stuve, M. Branschofsky, D. Chudnov, G. McClellan, and M. Smith. The DSpace institutional digital repository system: current functionality. In JCDL ’03: Proceedings of the 3rd ACM/IEEE-CS Joint Conference on Digital Libraries, pages 87–97, 2003. https://doi.org/10.1109/JCDL.2003.1204846.
- [111] H. Thiele. The Dublin Core and Warwick Framework: A Review of the Literature, March 1995 - September 1997. D-Lib Magazine, 4(1), 1998. https://hdl.handle.net/cnri.dlib/january98-thiele.
- [112] H. Van de Sompel. Paul Evan Peters Lecture: Scholarly Communication: Deconstruct & Decentralize?, 2017. https://www.slideshare.net/ hvdsomp/paul-evan-peters-lecture.
- [113] H. Van de Sompel, T. Krichel, M. L. Nelson, P. Hochstenbach, V. M. Lyapunov, K. Maly, M. Zubair, M. Kholief, X. Liu, and H. O’Connell. The UPS prototype: An experimental end-user service across e-print archives. D-Lib Magazine, 6(2), 2000. https://doi.org/10.1045/february2000-vandesompel-ups.
- [114] H. Van de Sompel and C. Lagoze. The Santa Fe Convention of the Open Archives Initiative. D-Lib Magazine, 6(2), 2000. https://doi.org/10.1045/february2000-vandesompel-oai.
- [115] H. Van de Sompel and M. L. Nelson. Reminiscing about 15 years of interoperability efforts. D-Lib Magazine, 21(11/12), 2015. https://doi.org/10.1045/november2015-vandesompel.
- [116] H. Van de Sompel, M. L. Nelson, and R. Sanderson. HTTP framework for time-based access to resource states – Memento, Internet RFC 7089, 2013. http://tools.ietf.org/html/rfc7089.
- [117] H. Van de Sompel, M. L. Nelson, R. Sanderson, L. L. Balakireva, S. Ainsworth, and H. Shankar. Memento: Time Travel for the Web. Technical Report arXiv:0911.1112, 2009. https://arxiv.org/abs/0911.1112.
- [118] H. Van de Sompel, S. Payette, J. Erickson, C. Lagoze, and S. Warner. Rethinking scholarly communication: Building the system that scholars deserve. D-Lib Magazine, 10(9), 2004. https://doi.org/10.1045/september2004-vandesompel.
- [119] A. Verstak, A. Acharya, H. Suzuki, S. Henderson, M. Iakhiaev, C. C. Y. Lin, and N. Shetty. On the shoulders of giants: The growing impact of older articles. Technical Report arXiv:1411.0275, Google, 2014. https://arxiv.org/abs/1411.0275.
- [120] H. D. Wactlar. Informedia Digital Video Library: Technology Outreach. D-Lib Magazine, 2(7/8), 1996. https://hdl.handle.net/cnri.dlib/july96-wactlar.
- [121] C. L. Webber, J. Tallon, E. Shepherd, and A. G. E. Prodromou. ActivityPub, 2018. W3C Editor’s Draft 23 January 2018. https://w3c.github.io/activitypub/.
- [122] S. Weibel. Metadata: The foundations of resource description. D-Lib Magazine, 1(1), 1995. https://doi.org/10.1045/july95-weibel.
- [123] S. Weibel, J. Godby, E. Miller, and R. Daniel. OCLC/NCSA Metadata Workshop Report, 1995. http://www.oclc.org:5046/conferences/metadata/dublin_core_report.html.
- [124] S. Weibel, R. Iannella, and W. Cathro. The 4th Dublin Core Metadata Workshop Report. D-Lib Magazine, 3(6), 1997. https://hdl.handle.net/cnri.dlib/june97-weibel.
- [125] B. Wilson. From the Editor: An Introduction and an Invitation. D-Lib Magazine, 5(1), 1999. https://doi.org/10.1045/january99-editorial.
- [126] B. Wilson. Introducing the D-Lib Alliance. D-Lib Magazine, 13(3/4), 2007. https://doi.org/10.1045/march2007-editorial.
- [127] B. Wilson. What’s in a Name? Categories of D-Lib Content Defined. D-Lib Magazine, 14(3/4), 2008. https://doi.org/10.1045/march2008-editorial.
- [128] B. Wilson and A. L. Powell. A Tenth Anniversary for D-Lib Magazine. D-Lib Magazine, 11(7/8), 2005. https://doi.org/10.1045/july2005-wilson.
- [129] J. York. This library never forgets: Preservation, cooperation, and the making of HathiTrust digital library. In Archiving Conference, pages 5–10, 2009. https://www.hathitrust.org/documents/This-Library-Never-Forgets.pdf.
Comments
Post a Comment