A thesis or dissertation is one type of scholarly work that shows a student pursuing higher education and has successfully met the partial requirement of a degree. An electronic thesis or dissertation can be found from either a university's electronic theses and dissertations (ETDs) digital library or
ProQuest (a third party ETD repository). ETDs contain lots of rich metadata that can be used for searching ETDs from the repository. However, not all ETD metadata are available. Therefore, it is necessary to extract metadata from scholarly ETDs. Also, extracting metadata could be challenging, mainly when it is found as scanned academic ETDs. Although many open-source tools exhibit satisfying performance in certain types of documents, experiments indicate that they tend to produce unacceptable errors or fail on scanned ETDs. In this blog post, I introduce one of the widely used optical character recognition (OCR) tools called
tesseract-OCR and show how tesseract-OCR performs on scanned ETDs.
Since 1997,
pioneered by Virginia Tech, more universities started supporting ETD submissions. Nevertheless, many ETDs before then and since then are published in non-born digital formats, usually generated by scanning physical copies. Extracting metadata from these scanned ETDs are challenging due to poor image resolution, typewritten text, and the imperfection of OCR techniques. For the OCR experiment, primarily, we considered downloading 50 scanned ETDs (i.e., ETDs published before 1980) by crawling the
MIT DSpace repository using
wget command. Firstly I used
ACHE — a web crawler to collect the downloadable links of the PDFs. Later, I used wget to download 50 scanned pdfs. Usage of the wget command can be found below:
I started experimenting with one of the MIT samples (Fig-1) using
OpenCV OCR. OpenCV OCR utilizes deep learning algorithms (Long Short-Term Memory and Recurrent Neural Network) to detect the text region. First, the
OpenCV's EAST text detector will apply to find the text region of interest (ROIs). Later, the ROIs will feed through the tesseract to extract the text. Although OpenCV was successfully captured ROIs (Fig-2), the OCR technique (Fig-3) was failed to extract the text correctly.
 |
| Fig-1: MIT sample in PNG format |
 |
| Fig-2: OpenCV EAST text detector |
 |
| Fig-3: Result of the OpenCV OCR |
Out of curiosity, I also ran some tests using OpenCV OCR on blurry natural images that consist of text. It turns out the OpenCV OCR performs very well on natural images.
We assumed that OpenCV OCR could be designed for extracting text from natural images since it was unable to extract text from the scanned documents. Therefore, we decided to apply only
tesseract-OCR (tesseract.py) on the scanned ETDs. We chose tesseract-OCR because it is a widely adopted open-source tool that takes any printed or scanned fonts, supports more than 100 languages, and returns the output in text, hOCR, PDF, and other formats. To apply tesseract-OCR on the scanned ETDs, I converted a few PDFs to PNG and JPEG format. Fig-4 is the result of the tesseract-OCR on PNG or JPEG format. We can see the result seems better than OpenCV OCR but with misspellings. For example, If we look at the result, we will see the title is fully misspelled, and the words "IEEE" and "oral" have been extracted as "TERE" and "@ral" respectively.
 |
| Fig-4: tesseract-OCR result on PNG format |
According to this
website, I found that the TIFF format is better than both PNG and JPEG format because primarily this format was developed for scanned documents or scanned images in the mid-1980s. Thus, I converted the cover page of the ETD to TIFF format and applied tesseract-OCR on it. Fig-5 shows the result of the tesseract-OCR on the TIFF format. We can see the result seems much more satisfying than the other two formats and it tends to produce fewer misspellings for further added samples.
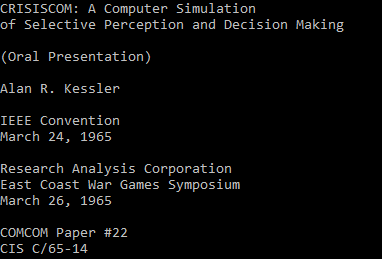 |
| Fig-5: tesseract-OCR on TIFF format |
Moreover, for further research on scanned ETDs, I collected another 50 ETDs from Virginia Tech and wrote a bash script to automate the process of converting only the cover page of each ETD to TIFF format. Afterward, I applied tesseract-OCR on the cover page of each ETD and saved the extracted result into text format. The script can be found in the code snippet below.
In this blog post, we have seen the performance of tesseract-OCR and compared its result with the OpenCV OCR technique. In a later
blog post, I will discuss how the heuristic-based model achieves significant performance on the extracted metadata.
-- Muntabir Choudhury





Comments
Post a Comment