2019-11-18: The 28th ACM International Conference on Information and Knowledge Management (CIKM)

Students, professors, industry experts, and others came to Beijing to attend the 28th ACM International Conference on Information and Knowledge Management (CIKM). This was the first time CIKM had accepted a long paper from the Old Dominion University Web Science and Digital Libraries Research Group (WS-DL) and I was happy to represent us at this prestigious conference.



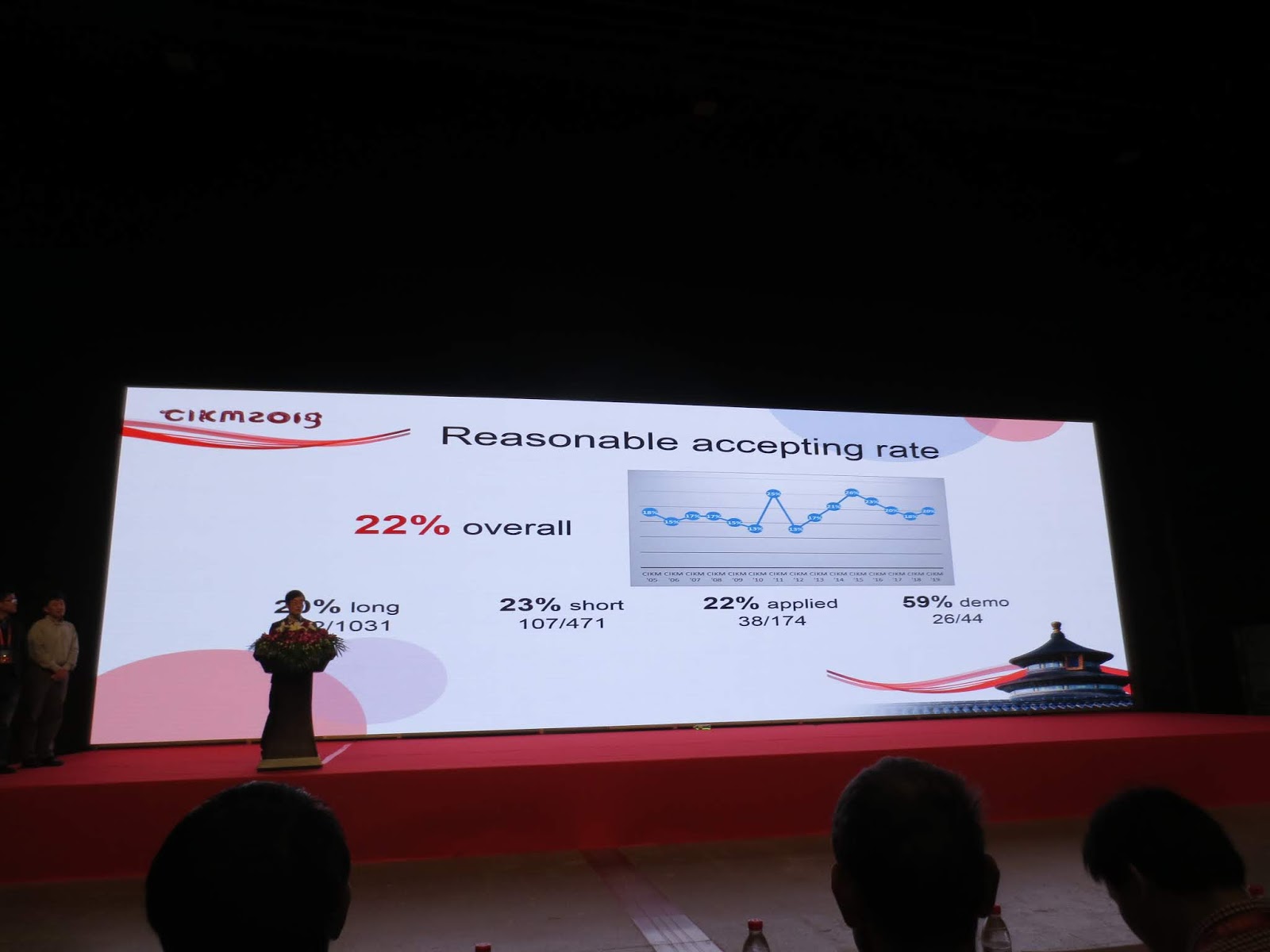
There were multiple tracks going in five different rooms across three days. There were 202 long papers, 107 short papers, 38 applied research papers, and 26 demos. I will not be able to summarize all of the impressive work present at this conference, but I will try to convey my wonderful CIKM experiences.
Keynote Speakers

Our first day's keynote was delivered by Professor Steve Maybank from the Department of Computer Science and Information Systems at Birkbeck College in the University of London. He is also a Fellow of the Institute of Mathematics and its Applications, a Fellow of the IEEE, a Fellow of the Royal Statistical Society, and a Fellow of the Higher Education Academy. In his keynote, "The Fisher-Rao Metric in Computer Vision", Maybank covered the mathematics behind one method used to detect curves and circles in computer images. To paraphrase Maybank, his solution is better because it uses simple structures in the image, but creates exact calculations. This has implications in biometrics and facial recognition for more precisely detecting irises and other circular features.

ACM and IEEE Fellow Jian Pei, from Simon Fraser University, delivered our second day keynote on "Practicing the Art of Data Science." He stressed that "as data scientists we are responsible for helping people obtain domain knowledge (from data)." He cautioned against merely using machine learning results as "it is not right to take a black box and try to explain it, instead we should build a model that is interpretable." Jian Pei discussed his own research team's work during his keynote, focusing on citations as a proxy for how generalizable a given paper's work must be. He detailed his team's work on using data science to assist programmers in discovering API methods, finding gangs of war in social networks, discovering the fastest changing portion of a graph over time, network embedding, developing piecewise linear neural networks, and more. He mentioned that a specialized solution for one type of problem may not be scalable and that his team tried to find solutions that covered many different types of problems. Jian Pei closed by stating "if given 1 hour to solve a problem, we should send 50 minutes trying to figure out what the problem is really about."

On our third day, Jiawei Han, Abel Bliss Professor from the Department of Computer Science at the University of Illinois at Urbana-Champaign, discussed methods of converting unstructured data to knowledge in "From Unstructured Text to TextCube: Automated Construction and Multidimensional Exploration." As with previous speakers, Jiawei Han is also an ACM Fellow and an IEEE Fellow and is the author of the popular textbook Data Mining: Concepts and Techniques, 3rd Edition. He spoke of the challenges of converting unstructured text to meaningful content. He covered many of his research team's projects. TopMine uses statistical measure to find groups of words from text and requires on training. Autophrase detects phrases in text via supervised learning. ClusType detects named entities. TaxoGen clusters documents to build a taxonomy from corpora. TextCube allows users to extract summaries and knowledge graphs from corpora. EventCube allows users to apply TextCube to events. WeSTClass classifies text with minimal data. JoSE provides better word embeddings than Word2Vec. Doc2Cube for creating TextCubes in an unsupervised way, without human annotators. Jiawei Han showed how such tools had real world applications. He demonstrated an analysis that provided further evidence that Malaysia Airlines Flight 17 was shot down by Ukrainian separatists. He finished with an analysis of the 2019 Hong Kong protests.

Jianping Shi introduced our fourth day with "Autonomous Driving Towards Mass Production". Jianping Shi is the Executive Research Director of SenseTime. She develops algorithms that facilitate autonomous driving by incorporating data from sensors, maps, and many other sources. Deep learning allows machines to acquire knowledge and skills and China has a lot of data on its people to offer to AI systems. They are currently trying to build the largest dataset ever to advance deep learning. Autonomous driving requires this same level of knowledge to work properly. Using this knowledge, an autonomous driving system can make decisions based on data collected by its sensors. Such sensors are not merely cameras taking in the same information as humans, but also incorporate data from systems such as LiDAR to measure distances and detect objects not visible to normal cameras. The solutions at SenseTime combine information from cameras and LiDAR to produce features for neural networks that are processed via hardware such as FPGAs. With this architecture, their systems can detect issues such as lane departures, potential pedestrian collisions, forward collisions, and correctly recognizing signs and traffic lights in all weather conditions. SenseTime also provides systems that open doors for drivers via facial recognition, determine if children or pets have left their seat, and cover blind spots by providing screens where windows are blocked by parts of the car.

Paper Presentations
As I state in other trip reports, conference presentations contain far more content than can be summarized in a single blog post. The full proceedings from CIKM are available for viewing. Below, I will discuss my own work and also feature some brief summaries of interesting work from CIKM.
My Work
As noted in my previous blog post, I have been evaluating the effectiveness of different types of surrogates for use in understanding web archive collections. CIKM accepted the paper from that work, "Social Cards Probably Provide Better Understanding of Web Archive Collections", and I presented it at CIKM on November 5, 2019. Thanks to Dr. Jian Wu for posting my picture to Twitter and thanks to the original photographer for taking the photo.
— Jian Wu (@fanchyna) November 5, 2019
In this work, we provide results from an analysis of the existing Archive-It interface and how well it might provide information for consumers of an Archive-It collection. We then take curator generated stories and visualize each using six different surrogate types, the Archive-It interface, browser thumbnails (screenshots), social cards, and three combinations of social cards and thumbnails. We present these visualized stories to Mechanical Turk participants and found that participants scored best on our test question when presented with social cards. In addition, participants clicked on browser thumbnails to view the content beneath them and interacted much with social cards the least. Thus, social cards probably provide better understanding of web archive collections.
Selected Work From Others
Some sessions, like LR15: Search & Retrieval, I could not attend because there was no more room. Please visit the ACM Digital Library website for access to the freely available proceedings for more detail. Here I will try to quickly summarize some of the work I witnessed.

Because I am trying to ultimately summarize web archive collections, several colleagues have recommended that I become more familiar with recommender systems. I attended Jun Liu's presentation of "BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer" where the author described the issue of evolving user interests and trying to predict their interests using using concepts from Google's BERT language model. Shaoyun Shi provided some insight into a solution to the cold start problem as part of "Adaptive Feature Sampling for Recommendation with Missing Content Feature Values". In that work, the authors detailed the problems with supplying random feature values to neural networks for recommendations and showed how their adaptive feature sampling system produced better results. Wayun Chen presented "A Dynamic Co-Attention Network for Session-based Recommendation" whereby the authors propose breaking a user's preferences into a long term and short term preferences before using a neural network to provide better recommendations based on this model. As a one of the authors of "A Hierarchical Self-Attentive Model for Recommended User-Generated Item Lists", Yun He discussed recommendations in environments containing playlists (e.g., YouTube, Goodreads, Spotify) and how user-generated playlists could be used to recommend other items to those users' followers. I'm intrigued by Yun He's work because it makes me wonder if Archive-It collections by the same curator can provide insight into each other. Di You mentioned how most users get their news from social media and even scholars have issues separating fake from real news. As part of "Attributed Multi-Relational Attention Network for Fact-checking URL Recommendation", Di You and her authors apply neural networks to a model that takes into account the user's social network in order to recommend fact-checking URLs to users. Any WS-DL member interested in studying fake news should look at Di You's (links: to advisor's homepage, advisor's Google Scholar) work.

We often employ Natural Language Processing (NLP) at WS-DL for solving a variety or problems, with Alexander Nwala's sumgram being a recent contribution to this area. To assist in this effort, I tried to attend the session on NLP. Natural language contains nested relations whereby concepts relating to the same entity are expressed within the same clause. For example: "the GDP of the United States in 2018 grew 2.9% compared with 2017" contains at multiple relations (GDP growth rate in 2018, compared to 2017, GDP of the US). As part of "Nested Relation Extraction with Iterative Neural Network", Yixuan Cao and co-authors model nested relations from text as directed acyclic graphs and then employ iterative neural networks to help the system to identify these relations. Word and document embeddings have a variety of uses in digital libraries, from expanding search terms to document clustering, and Tyler Derr builds on the state of the art in "Beyond word2vec: Distance-graph Tensor Factorization for Word and Document Embeddings." Derr and his co-authors identify the problem of comparing word and document embeddings to each other and propose a solution by modeling the entire corpus. In "Learning Chinese Word Embeddings from Stroke, Structure and Pinyin of Characters", Yun Zhang provided a solution for Chinese that cannot be applied to English because each character contains within it additional features that can be used to produce better embeddings. Chen Shiyun employed sequential neural networks and tagging to improve sentiment analysis of text in "Sentiment Commonsense Induced Sequential Neural Networks for Sentiment Classification" and showed that their solution performed better on three datasets. In "Interactive Multi-Grained Joint Model for Targeted Sentiment Analysis", Da Yin and co-authors employ neural networks to tackle the issue of polarization of sentiment where different parts of a sentence may contain different sentiments. WS-DL members seeking to understand sentiment in longer form text like news articles should examine either of these last papers.

As we study the graphs in social networks and perform link analysis on web content, network science becomes an important part of the WS-DL's work. In "Discovering Interesting Cycles in Directed Graphs", Florian Adriaens detailed how interesting cycles can be identified and measured using different measures and that finding interesting cycles is NP-hard. To assist users trying to find interesting cycles, they propose a number of heuristics. Bipartite graphs joining two sets can be used to model a number of problems. As part of "FLEET: Butterfly estimation from a Bipartite Graph Stream", the authors present FLEET, a suite of algorithms for estimating the number of butterflies, a specific type of bipartite graph. Tyler Derr presented "Balance in Signed Bipartite Networks", where he and his co-authors perform an analysis of signed butterflies in bipartite networks, develop methods to predict the signs of edges, and evaluate these methods on real-world signed bipartite networks. Albert Bifet presented his groups work on estimating the betweenness centrality of a node in the graph as part of "Adaptive Algorithms for Estimating Betweenness and k-path Centralities." The centrality of a node may indicate its importance (e.g., most important person in a social network) and estimating its centrality may help a system more quickly focus on specific nodes of interest. Of potentially interest to my work is Chen Zhang's "Selecting the Optimal Groups: Efficiently Computing Skyline k-Cliques." The skyline of a graph consists of objects that may dominate but are not dominated by other objects, and hence may be similar to the authorities in the HITS algorithm. Her work has implications in identifying members to assign to teams as well as product recommendations.

A variety of solutions exist in various algorithmic techniques that may be of interest to our future research. As part of "On VR Spatial Query for Dual Entangled Words", the authors explore the issue of spatial queries, those queries relevant based on the location of the user, that apply to both the real and VR world at the same time. Quang-Huy Duong presented "Sketching Streaming Histogram Elements using Multiple Weighted Factors" which provides solutions for estimating a histogram from a stream of incoming data. Such a histogram can be used to computer the similarities of two streams and predict when one may diverge. As part of "Improved Compressed String Dictionaries", Guillermo de Bernardo presented a novel solution to compressing the names of nodes in a network and providing for fast lookup times during network analysis. With IR research, participants are typically asked about the relevance of documents to a query and are asked to employ some scale estimating that relevance. Unfortunately, not all scales have the same number of points. Lei Han analyzed the TREC datasets to address the problem of transforming scales for comparison as part of "On Transforming Relevance Scales." In "Streamline Density Peak Clustering for Practical Adoption", the authors discuss the 2014 general purpose Density Peak Clustering (DPC) algorithm and roadblocks that have prevented its practical adoption. The authors propose a drop-in replacement for DPC, Streamlined DPC, that has enhanced speed and scalability. From this section, the spatial query work, histogram estimation, and node compression may be of interest to other WS-DL students. I may be able to apply the scale transformation and SDPC to my own summarization work.

My session was titled "User Behavior" and included a lot of other interesting work. Dustin Arendt identified problems with performing graph analysis on social networks, specifically that real-world graphs are dynamic and forecasting future behavior using existing static "snapshots" fails to incorporate information from the history of the graph. In "Learning from Dynamic User Interaction Graphs to Forecast Diverse Social Behavior", Arendt and his co-authors provide solutions for forecasting directly over dynamic graphs. Their solution is generalizable across social platforms and can do more than just predict new edges. WS-DL members investigating social networks should review Arendt's work. In "Exploring The Interaction Effects for Temporal Spatial Behavior Prediction", the authors create a model that creates representations of a user's action, location, time, and other user information int the same latent space. This way they can provide better recommendations based on predicted user behavior. As part of "Understanding Default Behavior in Online Lending", the authors are interested in using social networking to identify borrowers who are more likely to default on their microcredit loans. While analyzing data provided by lending platform PPDai, the authors identified "cheating agents", a new type of user who teachers borrowers how to cheat the system. They propose a framework for predicting both cheating agents and those who will default. Of some interest to the user study portion of my dissertation work is that of Anna Squicciarini, who, in "Rating Mechanisms for Sustainability of Crowdsourcing Platforms", identifies the issues in ensuring that Crowdsourcing platforms not only remain fair to crowd workers, but also sustainable. The authors introduce rating mechanisms and show how their new model can be used to improve Amazon's Mechanical Turk.

I attended a second natural language processing session that had some interesting ideas both for me and other WS-DL members. Topic modeling is one of the possible methods I will use to select representative samples from web archive collections. In "Federated Topic Modeling", the authors explore the issues with separating proprietary and sensitive training data for topic modeling. Their solution guarantees privacy protection while also limiting network communications, allowing for their solution to be used on high latency or low bandwidth networks. Chuhuan Wu presented "Sentiment Lexicon Ehanced Neural Sentiment Classification" whereby the authors employ sentiment lexicons to improve sentiment analysis with neural networks. They demonstrate two approaches with experimental results showing improvement of the state of the art. Wei Huang discussed a hierarchical multi-label text classification problem for organizing documents as part of "Hierarchical Multi-label Text Classification: An Attention-based Recurrent Network Approach." The authors employ a Hierarchical Attention-based Recurrent Neural Network, which means that it requires training data. I am particularly interested in this work and would like to see how I might be able to apply it to web archive collections, but do not yet have training data to start with. In "Multi-Turn Response Selection in Retrieval-Based Chatbots with Iterated Attentive Convolution Matching Network", the authors cover the issues of developing chatbots that are capable of not only responding to the last question asked, but also the whole context of the conversation. They employ an Iterative Attentive Convolution Matching Network (IACM) to solve the issue of context and are inspired by existing work with reading comprehension. Almost all of the work I encountered at CIKM employed some type of neural network, so I was pleasantly surprised by Md Zahidul Islam's presentation on "A Semantics Aware Random Forest for Text Classification" which provided an improvement over a different, but familiar classifier. The authors propose an improvement over how the Random Forest classifier selects its decision trees. I look forward to evaluating their new SARF algorithm the next time I need to use Random Forest to classify text.

Computer Vision is the name given to the act of computers trying to provide understanding of images. It is an area that the WS-DL group has little expertise in. I attended a session on this topic in hopes that I might gain some insight into how we might apply this area to web archive collections. Xiaomin Wang presented "Video-level Multi-model Fusion for Action Recognition" where her team worked with a convolutional neural networks to identify actions (e.g., a person throwing a ball) from video. On top of being impressed with their accomplishments, I am also intrigued by their solution because it incorporates a support vector machine at some point to process one of the layers of the neural network. Andrei Boiarov tried to address the problem of identifying landmarks in photos as part of "Large Scale Landmark Recognition via Deep Metric Learning." Their solution tries to overcome the problem of classification of a landmark (i.e., when is it a building, a statue, a wall?) via a novel scoring mechanism applied to their neural network. The world known to a classifier can be closed, but increasingly we want systems that can deal with and classify the open world in which we live. Xiaojie Guo tackles this problem with her coauthors in "Multi-stage Deep Classifier Cascades for Open World Recognition" whereby they propose a classifier architecture that provides a generic framework for solving this problem. Humans infer context from complex images, but neural networks cannot do the same from pixels. Manan Shah and his coauthors attempt to provide a solution for incorporating and predicting text for images as part of "Inferring Context from Pixels for Multimodal Image Classification." While these other researchers focused on acquiring meaning from image data, Mingkun Wang presented a different concept in "Multi-Target Multi-Camera Tracking with Human Body Part Semantic Features" whereby the authors combine content from multiple cameras to track individual people across different views, improving on previous efforts. Mingkun Wang's work does not yet have implications for web archives, but can be employed for security and AR applications.

I was quite impressed with the content that I viewed from all presenters and was not able to provide a summary of all short papers or long papers sessions. I was intrigued with Phillipp Christmann's work in "Look before you Hop: Conversational Question Answering over Knowledge Graphs Using Judicious Context Expansion" on improving the conversational ability of systems like Siri and Alexa by employing localized information from a knowledge graph to ensure that the system understands follow-up questions. Sarah Oppold provided a demonstration of "LuPe: A System for Personalized and Transparent Data-driven Decisions", a personalized transparent decision support system for evaluating the credit worthiness of a user without employing a single model for all users, thus avoiding unfairness inherent with other systems. I intend to read through the proceedings to find all of the items I missed.
Tutorial Sessions
Prior to the conference, multiple tutorials were offered on a variety of topics. Each tutorial lasted half of a day, so I could only choose two of the eight available. These tutorials provided each presenter an opportunity to cover each topic's state of the art, including the presenter's work.

Abdullah Mueen from the University of New Mexico presented "Taming Social Bots: Detection, Exploration And Measurement." Mueen covered the behaviors of social media bots, specifically with an eye toward identifying them based on their behavior. Bots have signatures from multiple feature categories: time, space, text, content, and network. Building on this, Mueen covered many different research projects for detecting bots. Botornot tries to classify bots based on these features. DeBot tries to detect bots based on the frequency and synchronicity of posts on a topic. Mueen's BotWalk relies upon the concept that bots form cliques in social networks and uses these cliques to identify them. BotWalk is able to detect 6,000 Twitter bots per day compared to 1,619 bots/day with DeBot and 1,469 bots/day with Botornot. Other research projects for detecting bots include the Rest Sleep Comment Model, CopyCatch, and Bot Dynamics. WS-DL members who focus on social media should further investigate this tutorial and other parts of Mueen's work.

My second tutorial, "Learning-Based Methods with Human-in-the-Loop for Entity Resolution", was developed by Lucian Popa and Siaram Gurajada, both from IBM Research. Popa and Gurajada covered the complex problem that I have referred to before as disambiguation - essentially determining if two entities are the same (e.g., Obama and Barack Obama). They covered different models for solving the problem. Explainable representation languages for this topic include Dedupalog, Markov Logic Networks, Declarative Entity Linking, and HIL. Learning based methods that incorporate machine learning and other techniques include Corleone/Falcon, MLN Learning, SystemER, and ExplainER. They discussed how one can improve results by incorporating crowdsourcing via tools like Amazon's Mechanical Turk, but also highlighted the shortcomings of these tools as crowd workers are often not experts on the entities being resolved. I am interested in these concepts because I seek to improve collection understanding of web archive collections and entities help provide meaning.
BigScholar 2019

BigScholar is a workshop that allows academics and practitioners to discuss ideas and concepts concerning big scholarly data. The goal is to focus on problems and solutions for knowledge discovery, data science, machine learning and more. I attended this workshop in the hopes that I would learn more about the intersection of git data and scholarly communications. BigScholar had taken place alongside WWW from 2014 - 2017, moved with KDD in 2018, and was part of CIKM in 2019. In 2020, the conference will unify several other workshops of the same type at ACL in Seattle.

Mattia Albergante, from the publisher Frontiers, gave the keynote for BigScholar 2019. The goal of Frontiers is to provide open access publishing across 71 journals covering more than 600 academic disciplines. They are the 14th largest publisher in the World and the 5th most cited publisher. Submissions to a Frontiers journal have an average review time of 92 days. Albergante spent the bulk of his talk highlighting the digital products that Frontiers developed in order to keep this review time reasonable while also maintaining quality. Key to assisting in peer review is their Artificial Intelligence Review Assistant (AIRA). AIRA speeds up their process by: (1) electronically evaluating the quality of submissions, and (2) identifies reviewers. Other systems may handle identifying plagiarism, but AIRA goes farther to identify potential personally identifiable images that violate privacy, issues with language quality, and images that may be mistakes. Once these issues have been mitigated, AIRA can move on to identifying which reviewers would best match the submission. Often reviewers are contacted by publishers to review a paper and tell the publisher that the paper is "not my field." AIRA employs text analysis, information from Microsoft Academic, various neural networking, and other technologies. Frontiers has reduced the "not my field" declination rate from 47% based on keywords alone to 15% using AIRA, setting themselves apart in quality from other open-access publishers like PLoS.

BigScholar also had four presentations. Yu Zhang presented "From Big Scholarly Data to Solution-Oriented Knowledge Repository" whereby he discussed using natural language processing to mine solutions from high impact papers so that scholars can more quickly solve research problems. Hyeon-Jo Jeon discussed "Is Performance of Scholars Correlated to their Research Collaboration Patterns?" where she covered her work on how co-authorship networks reflect different research styles and collaboration patterns have a high correlation to research performance, but this correlation does not always hold. Zhuoya Fan represented her team's work from "ScholarCitation: Chinese Scholar Citation Analysis Based on ScholarSpace in the Field of Computer Science" which examined cross-language citations between Chinese and English speaking scholars and found that even though there are different patterns in each field, Chinese Scholars tend to favor citing English papers. Kei Kurakawa presented his team's work in "Application of a Novel Subject Classification Scheme for a Bibliographic Database Using a Data-Driven Correspondence" (link not found) whereby they create an approach that allows for generating a new classification scheme using existing bibliographic databases.
Social

Our hosts treated us to lunch each day, a wonderful reception on Monday, and a fantastic banquet on Tuesday. During the banquet we were entertained with various traditional Chinese art forms including lion dances and brief Beijing opera.

Summary
A lot happened at CIKM. The conference is a very different venue than this research group regularly attends, and that is a good thing. My horizons were expanded quite a bit during this trip. I was able to acquaint myself with a number of students on the other side of the Pacific Ocean as well as many in Europe and North America that I would never have met otherwise. I now understand things about natural language processing, networks, computer vision, and a host of other topics. Next year, CIKM 2020 will be in Galway, Ireland where Brian Wall assures me they have an exciting new program planned for all attendees.
-- Shawn M. Jones
Comments
Post a Comment