2019-08-03: TweetedAt: Finding Tweet Timestamps for Pre and Post Snowflake Tweet IDs
 |
Figure 1: Screenshot from TweetedAt service showing timestamp for a deleted tweet from @SpeakerPelosi
|
Previous implementations of Snowflake in different programming languages such as Python, Ruby, PHP, Java, etc. have implemented finding the timestamp of a Snowflake tweet ID but none provide for estimating timestamps of pre-Snowflake IDs.
The reasons for implementing TweetedAt are:
- It is the only web service which allows users to find the timestamp of Snowflake tweet IDs and estimate tweet timestamps for pre-Snowflake Tweet IDs.
- Twitter developer API has access rate limits. It acts as a bottleneck in finding timestamps for a data set of tweet IDs. This bottleneck is not present in TweetedAt because we do not interact with Twitter's developer API for finding the timestamps.
- Deleted, suspended, and private tweets do not have their metadata accessible from Twitter's developer API. TweetedAt is the solution to finding the timestamps for any of these inaccessible tweets.
Snowflake
In 2010, Twitter migrated its database from MySQL to Cassandra. Unlike MySQL, Cassandra does not support sequential ID generation technique, so Twitter announced Snowflake, a service to generate unique IDs for all the tweet IDs and other objects within Twitter like lists, users, collections, etc. Snowflake generates unsigned-64 bit integers which consist of:
- timestamp - 41 bits (millisecond precision w/ a custom epoch gives us 69 years)
- configured machine ID - 10 bits - gives us up to 1024 machines
- sequence number - 12 bits - rolls over every 4096 per machine (with protection to avoid rollover in the same ms)
According to Twitter's post on Snowflake, the tweet IDs are k-sorted within a second bound but the millisecond bound cannot be guaranteed. We can extract the timestamp for a tweet ID by right shifting the tweet ID by 22 bits and adding the Twitter epoch time of 1288834974657.
Python code to get UTC timestamp of a tweet ID
def get_tweet_timestamp(tid): offset = 1288834974657 tstamp = (tid >> 22) + offset utcdttime = datetime.utcfromtimestamp(tstamp/1000) print(str(tid) + " : " + str(tstamp) + " => " + str(utcdttime))
Twitter released Snowflake on November 4, 2010 but it has been around since March, 2006. Pre-Snowflake IDs do not have their timestamps encoded in the IDs, but we can uncover the value from the 2362 tweet IDs with known timestamps.
Tweet ID 20 by @jack is the earliest tweet still available. https://t.co/rTSmxkVL51#ProTip:— Sawood Alam (@ibnesayeed) 30 June 2019
* #cURL supports URL globbing/patterns https://t.co/cMiEO4njSf
* @Twitter redirects to the right user for accessible IDs
* #Linux nl command adds line numbers to the output pic.twitter.com/CU9pFzLHfV
Estimating tweet timestamps for pre-Snowflake tweet IDs
TweetedAt estimates the timestamps for pre-Snowflake IDs with an approximate error of 1 hour. For our implementation, we collected 2362 tweet IDs and their timestamps at a daily interval between March 2006 and November 2010 to create a ground truth data set. The ground truth data set is used for estimating the timestamp of any tweet ID prior to Snowflake. Using the weekly interval as ground truth data set resulted in an approximate error of 3 hours and 23 minutes.
Batch cURL command to find first tweet
msiddique@wsdl-3102-03:/$ curl -Is "https://twitter.com/foobarbaz/status/[0-21]"| grep "^location:" location: https://twitter.com/jack/status/20 location: https://twitter.com/biz/status/21
The ground truth data set ranges from tweet ID 20 to 29700859247. The first non-404 tweet ID found using the cURL batch command is 20. We found a memento which contains pre-Snowflake ID of 29548970348 from Internet Archive for @nytimes close to Snowflake release date time. We performed all possible digits combinations on the tweet ID, 29548970348, using the cURL batch command to uncover the largest non-404 tweet ID known to us, 29700859247.
 |
| Figure 2: Exponential tweet growth rate in pre-Snowflake time range |
 |
| Figure 3: Semi-log scale of tweet growth in pre-Snowflake time range |
 |
| Figure 4: Pre-Snowflake time range graph showing two close on the curve (upper bound and lower bound) and a point between upper and lower bound for which timestamp is to be estimated. Each point on the graph is represented by a tuple of Tweet Timestamp (T) and Tweet ID (I). |

We know the tweet ID (I) for a tweet and want to estimate the timestamp (T) for it which can be estimated using the formula:

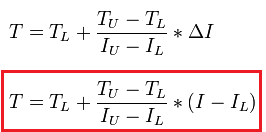
 |
| Summary of error difference between the estimated timestamp and the true Tweet timestamp (in minutes) generated on 1000 pre-Snowflake random Tweet IDs |
We can replace the Tweet Generation estimation formula by using a segmented curve fitting technique on the graph shown in figure 2 and reduce the program size by excluding all the 2362 data points.
 |
| Figure 5: Box plot of error range for Pre-Snowflake IDs conducted over a weekly test set. |
 |
| Summary of error difference between the estimated timestamp and the true Tweet timestamp (in minutes) generated on weekly pre-Snowflake random Tweet IDs |
Estimating the timestamp of a deleted pre-Snowflake ID
Figure 7 shows a pre-Snowflake deleted tweet from @barackobama which can be validated by the cURL response of the tweet ID. The timestamp of tweet in the memento is in Pacific Daylight Time (GMT -07). Upon converting the timestamp to GMT, it changes from Sun, 19 October 2008 10:41:45 PDT to Sun, 19 October 2008 17:41:45 GMT. Figure 8 shows TweetedAt returning the estimated timestamp of Sun, 19 October 2008 17:29:27 GMT which is off by approximately 12 minutes.
 |
Figure 7: Memento from Internet Archive for @barackobama having a pre-Snowflake deleted tweet ID
|
cURL response for @barackobama deleted Tweet ID
msiddique@wsdl-3102-03:~/WSDL_Work/Twitter-Diff-Tool$ curl -IL https://twitter.com/barackobama/966426142 HTTP/1.1 301 Moved Permanently location: /barackobama/lists/966426142 ... HTTP/1.1 404 Not Found content-length: 6329 last-modified: Wed, 31 Jul 2019 22:00:56 GMT ...
 |
| Figure 8: TweetedAt timestamp response for @barackobama's pre-Snowflake deleted tweet ID 966426142 which is off by 12 minutes |
To summarize, we released TweetedAt, a service to find the timestamp of any tweet ID from 2006 through today. We created a ground truth data set of pre-Snowflake IDs collected on daily interval for estimating timestamp of any tweet ID prior to Snowflake (November 4, 2010). We tested our pre-Snowflake tweet estimation formula on 1000 test data points and reported an approximate mean error of 45 minutes. We also tested our pre-Snowflake tweet estimation formula on 1932 test data points collected weekly and reported an approximate mean error of 59 minutes.
Comments
Post a Comment