While researching
my dissertation topic (slides 2--28) on social media profile discovery, I encountered a related paper titled
Gathering Alumni Information from a Web Social Network written by
Gabriel Resende Gonçalves,
Anderson Almeida Ferreira, and
Guilherme Tavares de Assis, which was published in the proceedings of the
9th IEEE Latin American Web Congress (LA-WEB). In this paper, the authors detailed their approach to define a semi-automated method to gather information regarding alumni of a given undergraduate program at Brazilian higher education institutions. Specifically, they use the
Google Custom Search Engine (CSE) to identify candidate
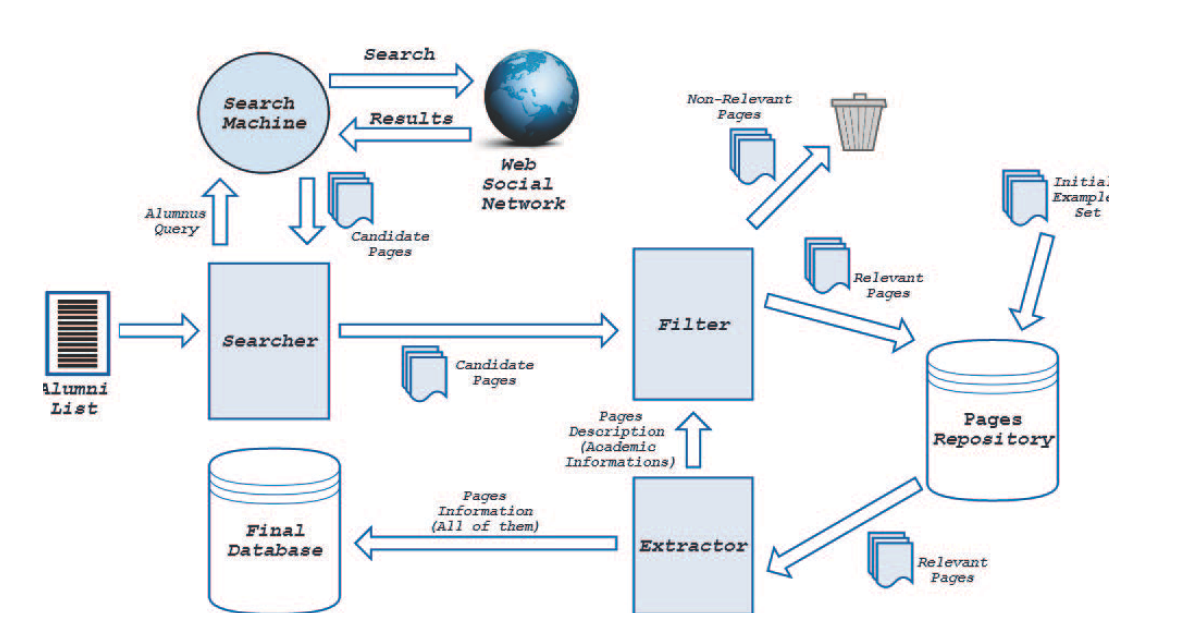
LinkedIn pages based on a comparative evaluation of similar pages in their training set. The authors contend alumni are efficiently found through their process, which is facilitated by focused crawling of data publicly available on social networks posted by the alumni themselves. The proposed methodology consists of three main modules and two data repositories, which are depicted in Figure 1. Using this functional architecture, the authors constructed a tool that gathers professional data on the alumni in undergraduate programs of interest, then proceeds to classify the associated HTML page to determine relevance. A summary of their methodology is presented here.
 |
| Figure 1 - Functional architecture of the proposed method |
Repositories
The first repository,
Pages Repository, stores the web pages from the initial set of data samples which are used to start the classification process. This set is comprised of alumni lists obtained from five universities across Brazil. The lists contain the names of students enrolled between 2000 and 2010 in undergraduate programs, namely Computer Science at three institutions, Metallurgical Engineering at one institution, and Chemistry at one institution. The total number of alumni available on all lists is 6,093. For the purpose of validation, a random set of 15 alumni are extracted from each list as training examples during each run of their classifier. The second repository,
Final Database, is the database where academic data on each alumnus is stored for further analysis.
Modules
The first module,
Searcher, determines the candidate pages from a Google result set that might belong to the alumni group. LinkedIn is the social network of choice from which the authors leverage public pages on the web which have been indexed by a search engine. The search is initiated using a combination of the first, middle and last names of a given alumnus, then, relevant data concerning the undergraduate program, program degree, and institution are extracted from the candidate pages. The authors chose not to search using LinkedIn's
Application Programming Interface (API) due to its inherent limitations. Specifically, the API requires authentication by a registered LinkedIn user and searches are restricted to the first degree connections of the user conducting the search. As an alternative, the authors use the Google Custom Search Engine which provides access to Google's massive repository of indexed pages, but is limited to 100 daily free searches returning 100 results per query.
We should note in the years since this paper was published in 2014, LinkedIn has instituted a number of security measures to impede data harvesting of public profiles. They employ a series of automated tools,
FUSE,
Quicksand,
Sentinel, and Org Block, that are used to monitor suspicious activity and block web scraping. Requests are throttled based on the requester's IP address (see
HIQ Labs V. LinkedIn Corporation). Anonymous viewing of a large number of public LinkedIn profile pages, even if retrieved using Google's boolean search criteria, is not always possible. After an undisclosed number of public profile views, LinkedIn forces the user to either sign up or log in as a way to thwart scraping by 3rd party applications (Figure 2).
 |
| Figure 2 - LinkedIn Anonymous Search Limit Reached |
The second module,
Filter, determines the significance of the candidate pages provided by the
Searcher module via the
Pages Repository. The classification process determines the similarity among pages using the academic information on the LinkedIn page as terms which are then separated into categories that describe the undergraduate program, institution, and degree. The authors proceed to use
Cosine Similarity to build a relationship between candidate pages from the
Searcher module and the initial training set based on term frequency and specify a 30% threshold for the minimum percentage of pages on which a term must appear.
The third module,
Extraction, extracts the demographic and academic information from the HTML pages returned by the
Filter module using regular expressions as shown in Figure 3. The extracted information is stored in the
Final Database for further analysis using the Naive Bayes
bag-of-words model to identify specific alumni of the desired undergraduate program.
 |
| Figure 3 - Regular Expressions Used by Extraction Module |
Results and Takeaways
The authors acknowledge that obtaining an initial list of alumni names is not a major obstacle. However, collecting the initial set of sample pages from a social network, such as LinkedIn, may be time consuming and labor intensive even with small data sets. Their evaluation, as shown in Figure 4, indicates satisfactory precision and the methodology proposed in their paper is able to find an average of 7.5% to 12.2% of alumni for undergraduate programs with more than 1,000 alumni.
 |
| Figure 4 - Pages Retrieved and Precision Results For Proposed Method and Baseline |
Given the highly structured design of LinkedIn HTML pages, we would expect the
Filter and
Extraction modules to identify and successful retrieve a higher percentage of alumni; even without applying a machine learning technique. The bulk of this paper's research is predicated upon access to public data on the web. If social media networks choose to present barriers that impede the collection of this public information, continued research by these authors and others will be significantly impacted. With regards to LinkedIn public profiles, we can only anticipate the imminent outcome of pending litigation which will determine
who controls publicly available data.
--Corren McCoy (
@correnmccoy)
Gonçalves, G. R., Ferreira, A. A., de Assis, G. T., & Tavares, A. I. (2014, October). Gathering alumni information from a web social network. In Web Congress (LA-WEB), 2014 9th Latin American (pp. 100-108). IEEE.



Comments
Post a Comment