2018-01-02: Link to Web Archives, not Search Engine Caches
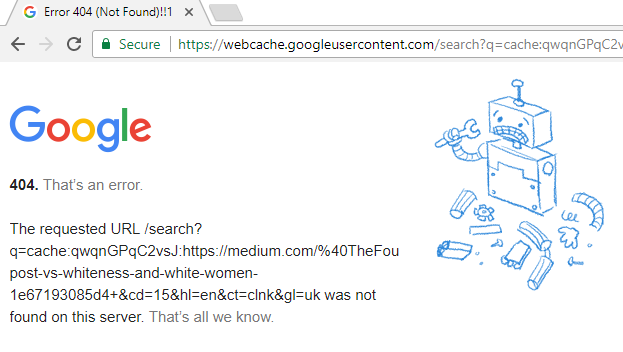 |
| Fig.1 Link TheFoundingSon Web Cache |
 |
| Fig.2 TheFoundingSon Archived Post |
 |
| Fig.3 TheFoundingSon Suspended Medium Account |
With regards to the recent reporting around Russian accounts specifically, we’re paying close attention and working to ensure that our trust and safety processes continue to evolve and identify any accounts that violate our rules.
Unfortunately, to provide evidence of the pages' former content, Burgess
links to Google caches instead of web archives. At the time of this writing, two of the three links for @TheFoundingSon's blog posts, which were included in Wired's article, produced a 404 response code from Google (the search engine containing the cached page) when clicking on the link (see Fig.1).
Only one link (Fig. 4), related to science and politics, was still available a few days after the article was written.
Doing so provides a list of ten archived URIs:
Another advantage of web archives over search engine caches is that web archives allow us to analyze changes of a web page through time. For example, @TheFoundingSon on 2016-06-16 had 14,253 followers, and on 2017-09-01 it had 41,942 followers.
 |
| Fig.4 TheFoundingSon Medium Post Related to Science and Politics |
Why is only one out of three web cache links still available? Search Engine (SE) caches are useful for covering transient errors in the live web, but they are not archives and thus not suitable for long-term access. In previous work our group has studied SE caches ("Characterization of Search Engine Caches") and the rate at which SE caches are purged ("Observed Web Robot Behavior on Decaying Web Subsites"). SE caches used to play a larger role in providing access to the past web (e.g., "How much of the web is archived?"), but improvements in the Internet Archive (i.e., no longer has a quarantine period, has a "save page now" function) and restrictions on SE APIs (e.g., monetization of the Yahoo BOSS API) have greatly reduced the role of SE caches in providing access to the past web.
To answer our original question of why two of the three links were not useful can be explained in that since Burgess is using SE caches to provide evidence of web pages that are removed from Medium's servers, and scientific research studies have proven SE’s will purge the index and cache of resources that are no longer available, we can expect that all links in the Wired's article pointing to SE caches will eventually decay.
If I were going to inquire about the type of blog @TheFoundingSon was writing, I could query https://medium.com/@TheFoundingSon from the IA's Wayback machine at web.archive.org (Fig.5). |
| Fig.5 TheFoundingSon Web Archived Pages |
Doing so provides a list of ten archived URIs:
- https://web.archive.org/web/20170223230217/https://medium.com/@TheFoundingSon/5-things-hillary-is-going-to-do-on-debate-night-81412f6878ab
- https://web.archive.org/web/20170223012115/https://medium.com/@TheFoundingSon/blindfolded-election-2016-bc269463dc7
- https://web.archive.org/web/20170626021233/https://medium.com/@TheFoundingSon/catholicism-is-evil-and-islam-is-religion-of-peace-74f2d7947162
- https://web.archive.org/web/20170222145442/https://medium.com/@TheFoundingSon/gun-control-absurdity-34cabd52f0e4
- https://web.archive.org/web/20170120073029/https://medium.com/@TheFoundingSon/hillarys-actions-vs-trump-s-words-what-is-louder-92798789eaf6
- https://web.archive.org/web/20170119183629/https://medium.com/@TheFoundingSon/lessons-huffpost-wants-us-to-learn-from-orlando-ac74f2a27922
- https://web.archive.org/web/20170222224659/https://medium.com/@TheFoundingSon/making-america-deplorable-37b9cea48b4b
- https://web.archive.org/web/20170223094335/https://medium.com/@TheFoundingSon/one-missed-wake-up-call-6cb87200cc2a
- https://web.archive.org/web/20170120021905/https://medium.com/@TheFoundingSon/see-something-say-nothing-b144aa5d4d39
- https://web.archive.org/web/20170807072351/https://medium.com/@TheFoundingSon/votes-that-count-7766810f0809
The archived web pages are in a time capsule preserved for generations to come, in contrast to SE caches which decay in a very short period of time. It is interesting to see that for @WadeHarriot, the account with the smallest number of Twitter followers before its suspension, Wired resorted to the IA for the 'lies' from Hillary Clinton posting; the other link was a Web search engine cache. Both web pages are available on the IA.
Another advantage of web archives over search engine caches is that web archives allow us to analyze changes of a web page through time. For example, @TheFoundingSon on 2016-06-16 had 14,253 followers, and on 2017-09-01 it had 41,942 followers.
The data to plot @JennAbrams and @TheFoundingSon Twitter follower counts over time were obtained by utilizing a tool created by Orkun Krand while working at ODU Web Science Digital Library Group (@WebSciDL). Our tool, which will be release in the near future (UPDATE [2018-03-15]: The tool was completed by Miranda Smith, and it is now available for download), makes use of the IA and Mementos. Ideally, we would like to capture as many copies (mementos) as possible of available resources, not only in the IA, but in all the web archives around the world. However, our Follower-Count-History tool only uses the IA, because some random Twitter pages most likely will not be found in the other web archives, and since our tool is using HTML scraping to extract the data, other archives may store their web pages in a different a format than the IA.
The IA allows us to analyze our Twitter accounts in greater detail. We could not graph the count over time for @WadeHarriot's Twitter followers because only one memento was available in the web archives. However, multiple mementos were found for the other two accounts. The Followers-Count-Over-Time tool provided the data to plot the two graphs shown above. We notice by looking at the graph of @TheFoundingSon that its Twitter followers doubled from around 15K to around 30K in only six months, and it continued an accelerated ascend reaching over 40K followers before its suspension. Similar analysis can be made with the @jenn_abrams account. Before October of 2015 @jenn_abrams had around 30K followers, and a year later, it almost doubled to around 55K followers, topping over 70K followers before its suspension. We could question if the followers of these accounts are real people, or if the rate of accumulation of followers followed a normal rate on Twitter, but we will leave these questions for another post.
SE caches are an important part of the Web Infrastructure, but using them as a link is a bad idea since they are expected to decay. Instead we should link to web archives. They are more stable, and as shown in the Twitter-Followers-Count-Over-Time graphs, they allow us time series analysis if we can find multiple mementos for the same URI.
- Plinio Vargas
UPDATE [2018-03-15]: The tool was completed by Miranda Smith, and it is now available for download
SE caches are an important part of the Web Infrastructure, but using them as a link is a bad idea since they are expected to decay. Instead we should link to web archives. They are more stable, and as shown in the Twitter-Followers-Count-Over-Time graphs, they allow us time series analysis if we can find multiple mementos for the same URI.
- Plinio Vargas
HTTP responses for some links found in the Wired article.
UPDATE [2018-02-19]: CNN said "cache" when it meant "archive". A CNN article made used of the IA to show the website (not longer available in the live Web) of a company accused of selling stolen identities of personnel living in the United States to Russian agents in order to facilitate banking transactions in the US. CNN used the term "cached version" to describe how they were able to make a link the past. CNN meant to use the term "archive".UPDATE [2018-03-15]: The tool was completed by Miranda Smith, and it is now available for download
Comments
Post a Comment