2012-07-05: Web Crawler Animation

One of things I find myself showing to people every month or two are Joan Smith's animations of web crawlers visiting a series of synthetic web sites over the course of a year (February 2007 -- February 2008). Joan's dissertation was on the topic of web servers assisting the task of digital preservation, both by enumerating the valid URIs at a web site and by providing preservation metadata about the resource representations at the web site. One of the sub-questions in the URI enumeration section was "will all resources at site be visited by conventional web crawlers?"
Conventional wisdom at the time said that web crawlers did not prefer to go "deep" into a site, instead preferring to a broad skim of the "surface" of a site with only a sampling of pages from a site. To test this prevailing notion, we built synthetic web sites that were simultaneously 100 pages wide (i.e., "/1", "/2", "/3", ... , "/100") and 100 pages deep (i.e., "/1", "/1/2", "/1/2/3", ... , "/1/2/3/4/.../100") and watched how Google, Yahoo, and MSN (it was pre-Bing) crawled the site (Joan had some clever code for generating synthetic web sites, but I don't recall her releasing it). We actually had four sites:
- two depth linking policies:
- bread crumb: "/1" links to "/1/2" which links to "/1/2/3" etc.
- buffet: "/1", "1/2", "1/2/3", etc. are all linked from the root page
- two hosting policies:
- hosted on .com machines
- hosted on .edu machines

In the above graph (click on it to see the animations), the Google crawler rips through the .com buffet site, visiting all pages in about 3 weeks.
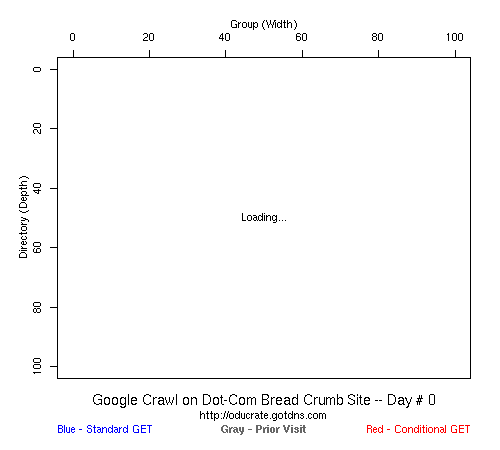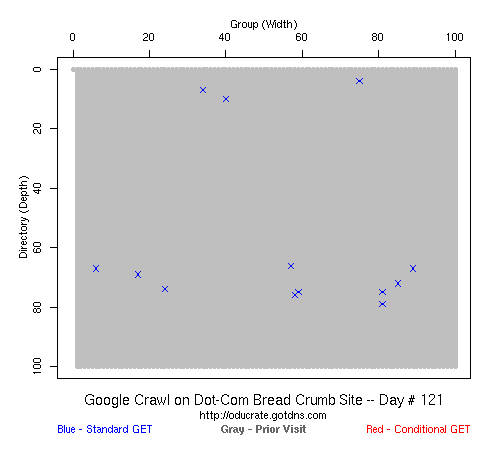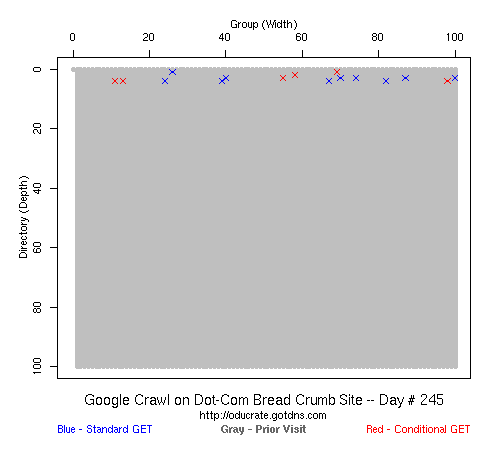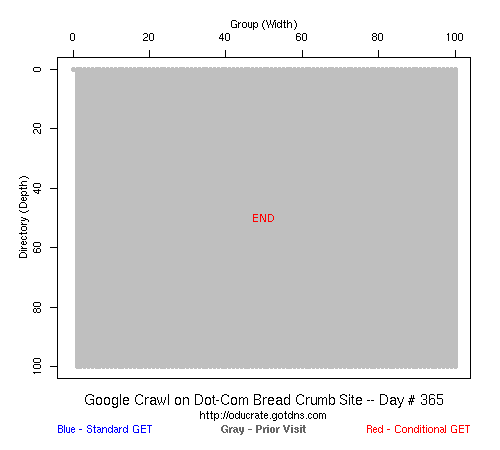
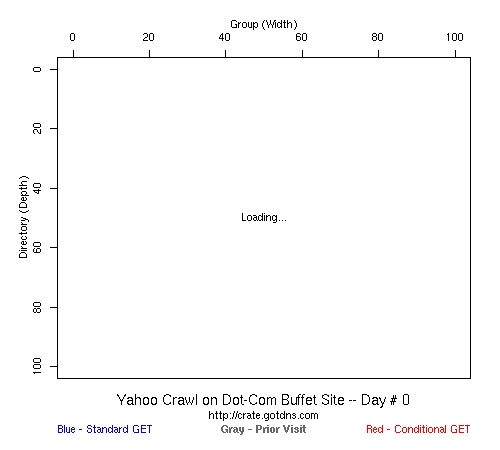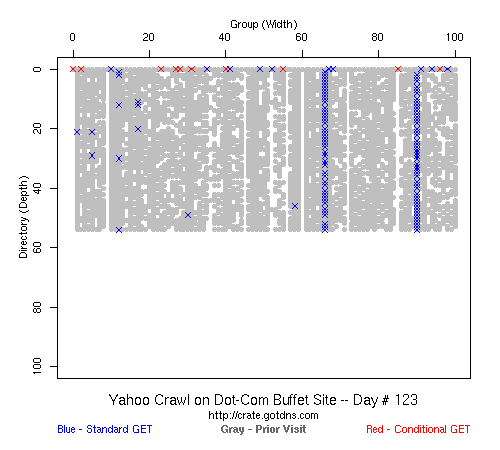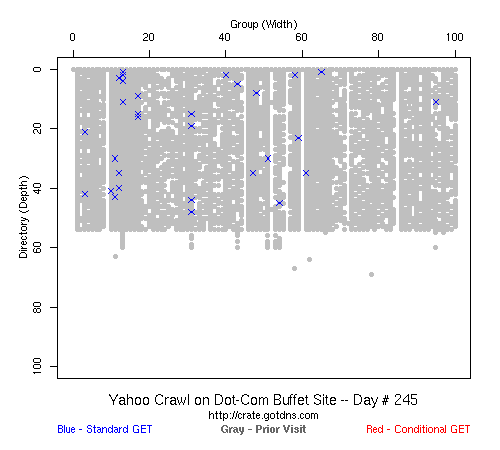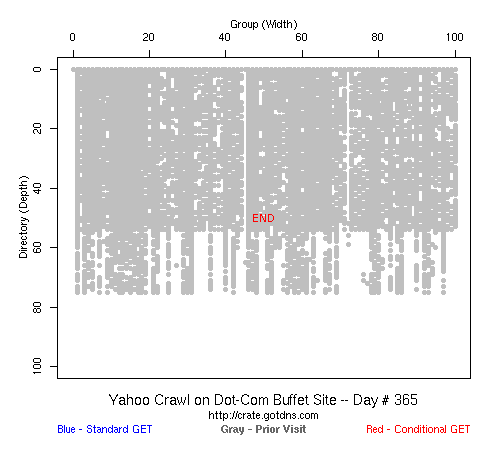
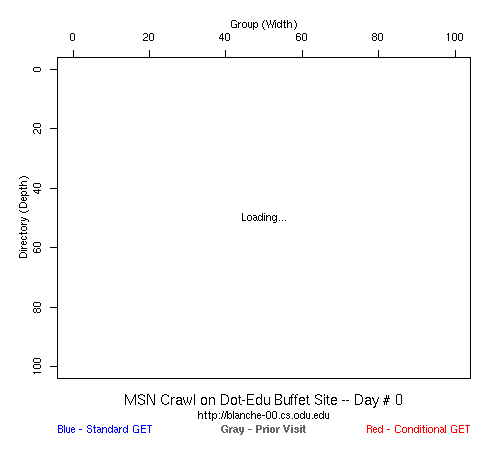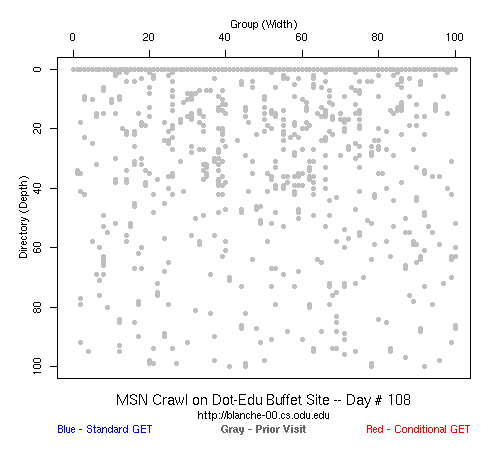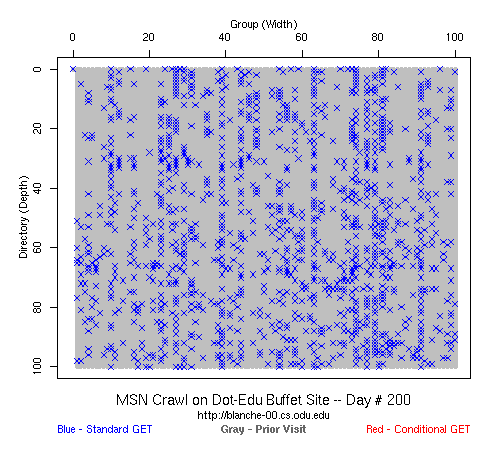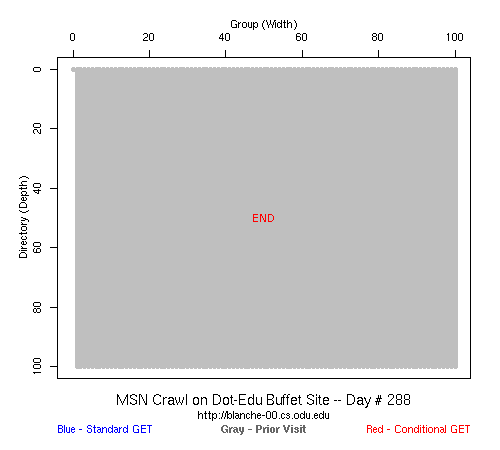
That is a typical problem with this kind of black-box experiment: without setting up many different web sites, it is hard to generalize the behavior that we saw. And even if it was an accurate description of the crawling strategies of the big three search engines, it was only accurate for the time period for which we took data (February 2007-- February 2008). All three could have changed their strategies in March 2008 and we would not have known. But it did answer our question: we could build large web sites (100x100) and every page would get crawled by someone if not everyone, and presumably the crawlers only get more aggressive over time.
It made a small buzz when the article came out but it has only received a single citation at the time of this writing, presumably because it addresses more of an engineering audience. It was never intended to be a primary result of Joan's research (we choose D-Lib Magazine as a suitable venue for animations), however the simple but effective animation has turned out to be the most fun part and it assuages my visualization envy.
Above I've selected four of the twelve animations; I highly recommend spending the time for all the animations in tables 3 and 6. The full citation for the work is:
Joan A. Smith, Michael L. Nelson, Site Design Impact on Robots: An Examination of Search Engine Crawler Behavior at Deep and Wide Websites, D-Lib Magazine, 14(3/4), 2008.--Michael
Comments
Post a Comment