Popular Storytelling service,
Storify,
will be shut down on May 16, 2018. Storify has been used by journalists and researchers to create stories about events and topics of interest. It has a wonderful interface, shown below, that allows one to insert text, but also add social cards and other content from a variety of services, including Twitter, Instagram, Facebook, YouTube, Getty Images, and of course regular HTTP URIs.
 |
| This screenshot displays the Storify editing Interface. |
As shown below, Storify is used by news sources to build and publish stories about unfolding events, as seen below for the
Boston NPR Station WBUR.
It is also the visualization platform used for summarizing Archive-It collections in
the Dark and Stormy Archives (DSA) Framework, developed by WS-DL members Yasmin AlNoamany, Michele Weigle, and Michael Nelson. In
a previous blog post, I covered why this visualization technique works and why many other tools fail to deliver it effectively. An example story produced by the the DSA is shown below.
Ian Milligan provides
an excellent overview of the importance of Storify and the issues surrounding its use. Storify stories have been painstakingly curated and the aggregation of content is valuable in and of itself, so before Storify disappears, how do we save these stories?
Saving the Content from Storify
Manually
Storify does allow a user to save their own content, one story at a time. Once you've logged in, you can perform the following steps:
 |
| 1. Click on My Stories |
|
 |
| 2. Select the story you wish to save |
|
 |
| 3. Choose the ellipsis menu from the upper right corner |
|
 |
| 4. Select Export |
|
 |
| 5. Choose the output format: HTML, XML, or JSON |
|
Depending on your browser and its settings, the resulting content may display in your browser or a download dialog may appear.
URIs for each file format do match a pattern. In our example story above, the slug for the story is
2823spst0s and our account name is
ait_stories. The different formats for our example story reside at the following URIs.
- JSON file format:
https://api.storify.com/v1/stories/ait_stories/2823spst0s
- XML file format:
https://storify.com/ait_stories/2823spst0s.xml
- Static HTML file format:
https://storify.com/ait_stories/2823spst0s.html
If one already has the slugs and the account names, they can save any public story. Private stories, however, can only be saved by the owner of the story.
What if we do not know the slugs of all of our stories? What if we want to save someone else's stories?
Using Storified From DocNow
For saving the HTML, XML, and JSON formats of Storify stories,
Ed Summers, creator of
twarc, has created the
storified utility as part of the
DocNow project. Using this utility, one can save public stories from any Storify account in the 3 available formats.
I used the utility to save the stories from the DSA's own ait_stories account. After ensuring I had installed
python and
pip, I was able to install and use the utility as follows:
git clone https://github.com/DocNow/storified.gitpip install requestscd storifiedpython ./storified.py ait_stories # replace ait_stories with the name of the account you wish to save
Update: Ed Summers mentions that one can now run pip install storified, replacing these steps. One only needs to then run storified.py ait_stories, again replacing ait_stories with the account name you wish to save.
Storified creates a directory with the given account name containing sub-directories named after each story's slug. For our Russia Plane crash example, I have the following:
~/storified/ait_stories/2823spst0s % ls -al
total 416
drwxr-xr-x 5 smj staff 160 Dec 13 16:46 .
drwxr-xr-x 48 smj staff 1536 Dec 13 16:47 ..
-rw-r--r-- 1 smj staff 58107 Dec 13 16:46 index.html
-rw-r--r-- 1 smj staff 48440 Dec 13 16:46 index.json
-rw-r--r-- 1 smj staff 98756 Dec 13 16:46 index.xml
I compared the content produced by the manual process above with the output from storified and there are slight differences in metadata between the authenticated manual export and the anonymous export generated by storified. Last seen dates and view counts are different in the JSON export, but there are no other differences. The XML and HTML exports of each process have small differences, such as
<canEdit>false</canEdit> in the storified version versus
<canEdit>true</canEdit> in the manual export. These small differences are likely due to the fact that I had to authenticate to manually export the story content whereas storified works anonymously. The content of the actual stories, however, is the same. I have created
a GitHub gist showing the different exported content.
Update: Nick B pointed out that the JSON files — and only the JSON files — generated either by manual export or via the storified tool are incomplete. I have tested his assertion with our example story (2823spst0s) and can confirm that the JSON files only contain the first 19 social cards. To acquire the rest of the metadata about a story collection in JSON format, one must use the Storify API. The XML and static HTML outputs do contain data for all social cards and it is just the JSON export that appears to lack completeness. Good catch!
Using storified, I was able to
extract and save our DSA content to Figshare for posterity. Figshare provides persistence as part of its work with the
the Digital Preservation Network, and
used CLOCKSS prior to March 2015.
That covers extracting the base story text and structured data, but what about the images and the rest of the experience? Can we use web archives instead?
Using Web Archiving on Storify Stories
Storify Stories are web resources, so how well can they be archived by web archives? Using our example Russia Plane Crash story, with a screenshot shown below, I submitted its URI to several web archiving services and then used the
WS-DL memento damage application to compute the memento damage of the resulting memento.
 |
| A screenshot of our Storify story served from webrecorder.io. |
 |
| A screenshot of our Storify story served via WAIL version 1.2.0-beta3. |
| Platform |
Memento Damage Score |
Visual Inspection Comments |
| Original Page at Storify |
0.002 |
- All social cards complete
- Views Widget works
- Embed Widget works
- Livefyre Comments widget is present
- Interactive Share Widget contains all images
- No visible pagination animation
|
| Internet Archive with Save Page Now |
0.053 |
- Missing the last 5 social cards
- Views Widget does not work
- Embed Widget works
- Livefyre Comments widget is missing
- Interactive Share Widget contains all images
- Pagination animation runs on click and terminates with errors
|
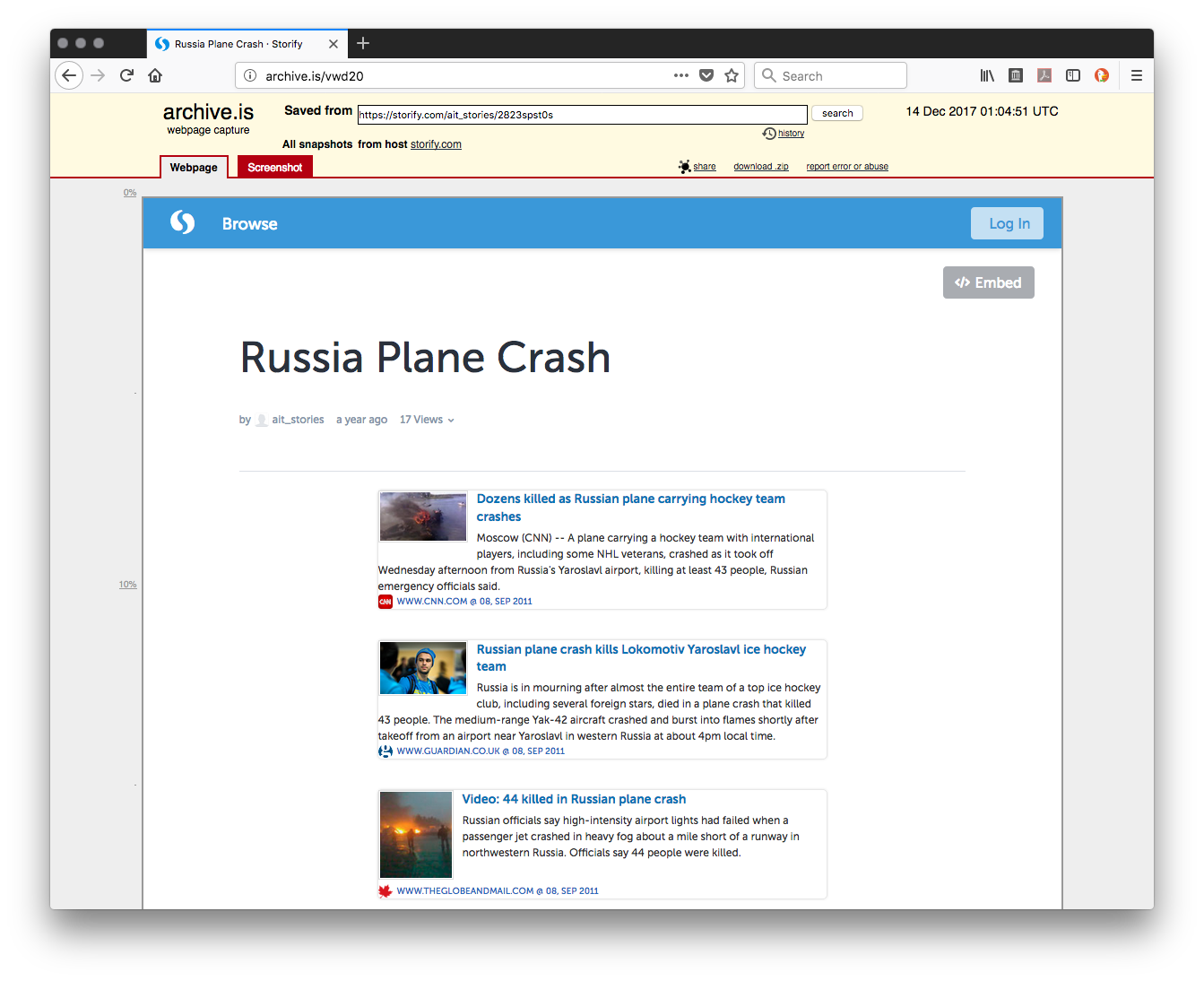
| Archive.is |
0.000 |
- Missing the last 5 social cards
- Views Widget does not work
- Embed Widget does not work
- Livefyre Comments widget is missing
- Interactive Share Widget is missing
- Pagination animation is replaced by "Next Page" which goes nowhere
|
| Webrecorder.io |
0.051* |
- Missing the last 5 social cards, but can capture all with user interaction while recording
- Views Widget works
- Embed Widget works
- Livefyre Comments widget is missing
- Interactive Share Widget contains all images
- No visible pagination animation
|
| WAIL |
0.025 |
- All social cards complete
- Views Widget works, but is missing downward arrow
- Embed Widget is missing images, but otherwise works
- Livefyre Comments widget is missing
- Interactive Share Widget is missing images
- Pagination animation runs and does not terminate
|
Out of these platforms, Archive.is has the lowest memento damage score, but in this case the memento damage tool has been misled by how Archive.is produces its content. Because Archive.is takes a snapshot of the DOM at the time of capture and does not preserve the JavaScript on the page, it may score low on Memento Damage, but also has no functional interactive widgets and is also missing 5 social cards at the end of the page. The memento damage tool crashed while trying to provide a damage score for Webrecorder.io; its score has been extracted from logging information.
I visually evaluated each platform for the authenticity of its reproduction of the interactivity of the original page. I did not expect functions that relied on external resources to work, but I did expect menus to appear and images to be present when interacting with widgets. In this case, Webrecorder.io produces the most authentic reproduction, only missing the Livefyre comments widget. Storify stories, however, do not completely display the entire story at load time. Once a user scrolls down, JavaScript retrieves the additional content. Webrecorder.io will not acquire this additional paged content unless the user scrolls the page manually while recording.
WAIL, on the other hand, retrieved all of the social cards. Even though it failed to capture some of the interactive widgets, it did capture all social cards and, unlike webrecorder.io, does not require any user interaction once seeds are inserted. On playback, however, it does still display the animated pagination widget as seen below, misleading the user to believe that more content is loading.
 |
| A zoomed in screenshot from WAIL's playback engine with the pagination animation outlined in a red box. |
WAIL also has the capability of crawling the web resources linked to from the social cards themselves, making them suitable choices if linked content is more important than complete authentic reproduction.
The most value comes from the social cards and the text of the story, and not the interactive widgets. Rather than using the story URIs themselves, one can avoid the page load pagination problems by just archiving the static HTML version of the story mentioned above — use
https://storify.com/ait_stories/2823spst0s.html rather than
https://storify.com/ait_stories/2823spst0s. I have tested the static HTML URIs in all tools and have discovered that all social cards were preserved.
 |
| The static HTML page version of the same story, missing interactive widgets, but containing all story content. |
Unfortunately, other archived content probably did not link to the static HTML version. Because of this, if one were trying to browse a web archive's collection and followed a link intended to reach a Storify story, they would not see it, even though the static HTML version may have been archived. In other words, web archives would not know to canonicalize
https://storify.com/ait_stories/2823spst0s.html and
https://storify.com/ait_stories/2823spst0s.
Summary
As with most preservation, the goal of the archivist needs to be clear before attempting to preserve Storify stories.
Using the manual method or DocNow's storified, we can save the information needed to reconstruct the text of the social cards and other text of the story, but with missing images and interactive content. Aiming web archiving platforms at the Storify URIs, we can archive some of the interactive functionality of Storify, with some degree of success, but also with loss of story content due to automated pagination.
For the purposes of preserving the visualization that is the story, I recommend using a web archiving tool to archive the static HTML version, which will preserve the images and text as well as the visual flow of the story so necessary for successful storytelling. I also recommend performing a crawl to preserve not only the story, but the items linked from the social cards. Keep in mind that web pages likely link to the Storify story URI and not its static HTML URI, hampering discovery within large web archives.
Even though we can't save Storify the organization, we can save the content of Storify the web site.
--
Shawn M. Jones
Updated on 2017/12/14 at 3:30 PM EST with note about pip install storified thanks to Ed Summers' feedback.
Updated on 2017/12/15 at 11:20 PM EST with note about the JSON formatted export missing stories thanks to Nick B's feedback.














Comments
Post a Comment