2017-01-20: CNN.com has been unarchivable since November 1st, 2016
CNN.com has been unarchivable since 2016-11-01T15:01:31, at least by the common web archiving systems employed by the Internet Archive, archive.is, and webcitation.org. The last known correctly archived page in the Internet Archive's Wayback Machine is 2016-11-01T13:15:40, with all versions since then producing some kind of error (including today's; 2017-01-20T09:16:50). This means that the most popular web archives have no record of the time immediately before the presidential election through at least today's presidential inauguration.

Given the political controversy surrounding the election, one might conclude this is a part of some grand conspiracy equivalent to those found in the TV series The X-Files. But rest assured, this is not the case; the page was archived as is, and the reasons behind the archival failure are not as fantastical as those found in the show. As we will explain below, other archival systems have successfully archived CNN.com during this period (e.g, Perma.cc).
To begin the explanation of this anomaly, let's consider the raw HTML of the memento on 2016-11-01T15:01:31. At first glance, the HTML appears normal with few apparent differences (disregarding the Wayback injected tags) from the live web when comparing the two using only the browser's view-source feature. Only by looking closely at the body tag will you notice something out of place: the body tag has several CSS classes applied to it one of which seems oddly suspicious.
<body class="pg pg-hidden pg-homepage pg-section domestic t-light">

The class that should jump out is pg-hidden which is defined in the external style sheet page.css. Its definition seen below can be found on lines 28625-28631.
To begin the explanation of this anomaly, let's consider the raw HTML of the memento on 2016-11-01T15:01:31. At first glance, the HTML appears normal with few apparent differences (disregarding the Wayback injected tags) from the live web when comparing the two using only the browser's view-source feature. Only by looking closely at the body tag will you notice something out of place: the body tag has several CSS classes applied to it one of which seems oddly suspicious.
<body class="pg pg-hidden pg-homepage pg-section domestic t-light">

The class that should jump out is pg-hidden which is defined in the external style sheet page.css. Its definition seen below can be found on lines 28625-28631.
.pg-hidden { display: none }
As the definition is extremely simple a quick fix would be to remove it. So let's remove it.

What is revealed after removing the pg-hidden class is a skeleton page i.e. a template page sent by the server that relies on the client-side JavaScript to do the bulk of the rendering. A hint to confirm this can be found in the number of errors thrown when loading the archived page.
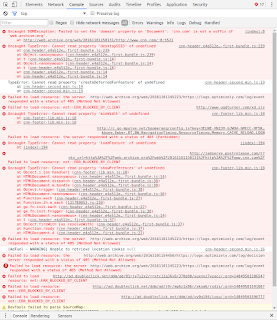
The first error occurs when JavaScript attempts the change the domain property of the document.
This is commonly done to allow a page on a subdomain to load resources from another page on the superdomain (or vice versa) in order to avoid cross-origin restrictions. In the case of cnn.com, it is apparent that this is done in order to communicate with their CDN (content delivery network) and several embedded iframes in the page (more on this later). To better understand this consider the following excerpt about Same-origin policy from the MDN (Mozilla Developer Network):
Seen below is the relevant portion of JavaScript that does not get executed after the document.domain exception.

What is revealed after removing the pg-hidden class is a skeleton page i.e. a template page sent by the server that relies on the client-side JavaScript to do the bulk of the rendering. A hint to confirm this can be found in the number of errors thrown when loading the archived page.

Uncaught DOMException: Failed to set the 'domain' property on 'Document'
'cnn.com' is not a suffix of 'web.archive.org'. at (anonymous) @ (index):8
This is commonly done to allow a page on a subdomain to load resources from another page on the superdomain (or vice versa) in order to avoid cross-origin restrictions. In the case of cnn.com, it is apparent that this is done in order to communicate with their CDN (content delivery network) and several embedded iframes in the page (more on this later). To better understand this consider the following excerpt about Same-origin policy from the MDN (Mozilla Developer Network):
A page may change its own origin with some limitations. A script can set the value of document.domain to a suffix of the current domain. If it does so, the shorter domain is used for subsequent origin checks. For example, assume a script in the document at http://store.company.com/dir/other.html executes the following statement:
document.domain = "company.com";
After that statement executes, the page would pass the origin check with http://company.com/dir/page.html. However, by the same reasoning, company.com could not set document.domain to othercompany.com.There are four other exceptions displayed in the console from three JavaScript files (brought in from the CDN)
- cnn-header.e4a512e…-first-bundle.js
- cnn-header-second.min.js
- cnn-footer-lib.min.js
Seen below is the relevant portion of JavaScript that does not get executed after the document.domain exception.
This portion of code sets up the global CNN object with the necessary information on how to load the assets for each section (zone) of the page and the manner by which to load them. What was not shown is the configurations for the sections, i.e the explicit definition of the content contained in them. This is important because these definitions are not added to the global CNN object due to the exception being thrown above (at window.document.domain). This causes the execution of the remaining portions of the script tag to halt before reaching them. Shown below is another inline script that is further in the document which does a similar setup.
In this tag the definitions that tell how the content model (news stories contained in the sections) are to be loaded along with further assets to be loaded. This code block does get executed in its entirety, which is important to note because the "lazy loading" definitions seen in the previous code block are added here. By defining that the content is to be lazily loaded (loadAllZonesLazy) the portion of Javascript responsible for revealing the page will not execute because the previous code blocks definitions are not added to the global CNN object. The section of code (from cnn-footer-lib.min.js) that does the reveal is seen below
As you can see the reveal code depends on two things: zone configuration defined in the section of code not executed and information added to the global CNN object in the cnn-header files responsible for the construction of the page. These files (along with the other cnn-*.js files) were un-minified and assignments to the global CNN object reconstructed to make this determination. For those interested, the results of this process can be viewed in this gist.
At this point, you must be wondering what changed between the time when the CNN archives could be viewed via the WaybackMachine and now. These changes can be summarized by considering the relevant code sections from the last correctly archived memento on 2016-11-01T13:15:40 seen below
 As you can see in the above image of the memento on 2016-11-01T13:15:40, the headline of the page and the first image from the top stories section of the page are visible. The remaining sections of the page are missing as they are the lazily loaded content. Now compare this to the first not correctly archived memento on 2016-11-01T15:01:3. The headline and the first image from the top stories are a part of the sections lazily loaded (loadAllZonesLazy); thus, they contain dynamic content. This is confirmed when the pg-hidden CSS class is removed from the body tag to reveal that only the footer of the page is rendered but without any of the contents.
As you can see in the above image of the memento on 2016-11-01T13:15:40, the headline of the page and the first image from the top stories section of the page are visible. The remaining sections of the page are missing as they are the lazily loaded content. Now compare this to the first not correctly archived memento on 2016-11-01T15:01:3. The headline and the first image from the top stories are a part of the sections lazily loaded (loadAllZonesLazy); thus, they contain dynamic content. This is confirmed when the pg-hidden CSS class is removed from the body tag to reveal that only the footer of the page is rendered but without any of the contents.


In short, the archival failure is caused by changes CNN made to their CDN; these changes are reflected in the JavaScript used to render the homepage. The Internet Archive is not the only archive experiencing the failure, archive.is and webcitation.org are also affected. Viewing a capture on 2016-11-29T23:09:40 from archive.is, the preserved page once again appears to be an about:blank page.







At this point, you must be wondering what changed between the time when the CNN archives could be viewed via the WaybackMachine and now. These changes can be summarized by considering the relevant code sections from the last correctly archived memento on 2016-11-01T13:15:40 seen below


Even today the archival failure is happening as seen in the memento on 2017-01-20T16:00:45 seen below


Removing the pg-hidden definition reveals that only the footer is visible which is the same result as the memento from the Internet Archive's on 2016-11-01T15:01:31.

But unlike the Internet Archive's capture the archive.is capture is only the body of CNN's homepage with the CSS styles inlined (style="...") on each tag. This happens because archive.is does not preserve any of the JavaScript associated with the page and performs the transformation previously described to the page in order to archive it. This means that cnn.com's JavaScript will never be executed when replayed thus the dynamic contents will not be displayed.
WebCitation, on the other hand, does preserve some of the page's JavaScript, but it is not immediately apparent due to how pages are replayed. When viewing a capture from WebCitation on 2016-11-13T33:51:09 the page appears to be rendered "properly" albeit without any CSS styling.
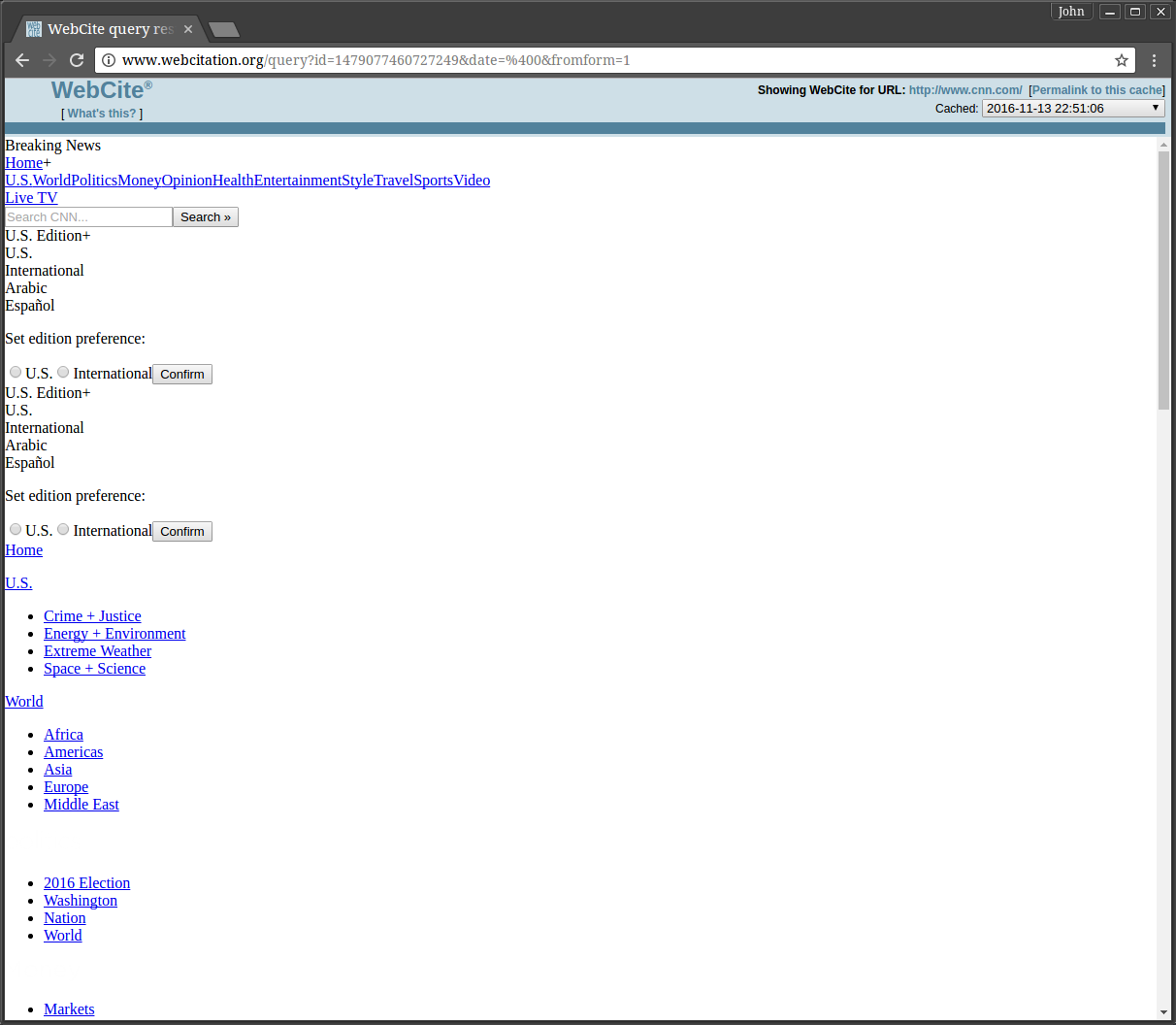
This happens because WebCitation replays the page using PHP and a frame. The replay frame's PHP script loads the preserved page into the browser; then, any of the preserved CSS and JavaScript is served from another PHP script. However, using this process of serving the preserved contents may not work successfully as seen below.

WebCitation sent the CSS style sheets with the MIME type of text/html instead of text/css. This would explain why the page looks as it does. But cnn.com's JavaScript was executed with the same errors occurring that were present when replaying the Internet Archive's capture. This begs the question, "How can we preserve cnn.com as cnn.com is unarchivable, at least by the most commonly used means?".
The solution is not as simple as one may hope, but a preliminary solution (albeit band-aid) would be to archive the page using tools such as WARCreate, Webrecorder or Perma.cc. These tools are effective since they preserve a fully rendered page along with all network requests made when rendering the page. This ensures that the JavaScript requested content and rendered sections of the page are replayable. Replaying of the page without the effects of that line of code is possible but requires the page to be replayed in an iframe. This method of replay is employed by Ilya Kreymer's PyWb (Python implementation of the Wayback Machine) and is used by Webrecorder and Perma.cc.
This is a fairly old hack used to avoid the avoid cross-origin restrictions. The guest page, brought in through the iframe, is free set the document.domain thus allowing the offending line code to execute without issue. A more detailed explanation can be found in this blog post but the proof is in the pudding by preservation and replay. I have created an example collection through Webrecorder that contains two captures of cnn.com.
The first is named "Using WARCreate" which used WARCreate for preservation on 2017-01-18T22:59:43,

and the second is named "Using Webrecorder" which used Webrecorders recording feature as the preservation means on 2017-01-13T04:12:34.

A capture of cnn.com on 2017-01-19T16:57:05 using Perma.cc for preservation is also available for replay here.

All three captures will be replayed using PyWb and when bringing up the console, the document.domain exception will no longer be seen.
The CNN archival failure highlights some of the issues faced when preserving online news and was a topic addressed at Dodging The Memory 2016. The whiteout, a function of the page itself not the archives, raises two questions "Is using web browsers for archiving the only viable option?" and "How much modification of the page is required in order to make replay feasible?".
- John Berlin
There's an awful lot of lack of keep-it-simple-stupid in the coding of the modern-day web.
ReplyDelete