2017-01-15: Summary of "Trusty URIs: Verifiable, Immutable, and Permanent Digital Artifacts for Linked Data"
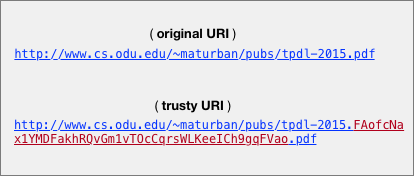 |
| Example: original URI vs. trusty URI |
Kuhn, T., Dumontier, M.: Trusty URIs: Verifiable, immutable, and permanent digital artifacts for linked data. Proceedings of the European Semantic Web Conference (ESWC) pp. 395–410 (2014).
A trusty URI is a URI that contains a cryptographic hash value of the content it identifies. The authors introduced this technique of using trusty URIs to make digital artifacts, specially those related to scholarly publications, immutable, verifiable, and permanent. With the assumption that a trusty URI, once created, is linked from other resources or stored by a third party, it becomes possible to detect if the content that the trusty URI identifies has been tampered with or manipulated on the way (e.g., trusty URIs to prevent man-in-the-middle attacks). In addition, trusty URIs can verify the content even if it is no longer found at the original URI but still can be retrieved from other locations, such as Google's cache, and web archives (e.g., Internet Archive).
The core contribution of this paper is the ability of creating trusty URIs on different kind of content. Two modules are proposed: in the module F, the hash is calculated on the byte-level file content while in the second module R the hash is calculated on RDF graphs. The paper introduced an algorithm to generate the hash value on RDF graphs independent of any serialization syntax (e.g., N-Quads or TriX). Moreover, they investigated how trusty URIs work on the structured documents (nanopublications). Nanopublications are small RDF graphs (named graphs -- one of the main concepts of Semantic Web) to describe information about scientific statements. The nanopublication as a Named Graph itself consists of multiple Named Graphs: the "assertion" has the actual scientific statement like "malaria is transmitted by mosquitos" in the example below; the "provenance" has information about how the statement in the "assertion" was originally derived; and the "publication information" has information like who created the nanopublication and when.
 |
Nanopublications may cite other nanopublications resulting in having complex citation tree. Trusty URIs are designed not only to validate nanopublications individually but also to validate the whole citation tree. The nanopublication example shown below, which is about the statement "malaria is transmitted by mosquitos", is from the paper ("The anatomy of a nanopublication") and it is in TRIG format:
@prefix swan: < http://swan.mindinformatics.org/ontologies/1.2/pav.owl> .
@prefix cw: < http://conceptwiki.org/index.php/Concept>.
@prefix swp: <http://www.w3.org/2004/03/trix/swp-1/>.
@prefix : <http://www.example.org/thisDocument#> .
:G1 = { cw:malaria cw:isTransmittedBy cw:mosquitoes }
:G2 = { :G1 swan:importedBy cw:TextExtractor,
:G1 swan:createdOn "2009-09-03"^^xsd:date,
:G1 swan:authoredBy cw:BobSmith }
:G3 = { :G2 ann:assertedBy cw:SomeOrganization }
In addition to the two modules, they are planning to define new modules for more types of content (e.g., hypertext/HTML) in the future.
The example below illustrates the general structure of trusty URIs:

The artifact code, everything after r1, is the part that make this URI a trusty URI. The first character in this code (R) is to identify the module. In the example, R indicates that this trusty URI was generated on a RDF graph. The second character (A) is to specify any version of this module. The remaining characters (5..0) represents the hash value on the content. All hash values are generated by SHA-256 algorithm. I think it would be more useful to allow users to select any preferred cryptographic hash function instead of enforcing a single hash function. This might result in adding more characters to the artifact code to represent the selected hash function. InterPlanetary File System (IPFS), for example, uses Multihash as mechanism to prefix the resulting hash value with an id that maps to a particular hash function. Similar to trusty URIs, resources in the IPFS network are addressed based on hash values calculated on the content. For instance, the first two characters "Qm" in the IPFS address "/ipfs/QmZTR5bcpQD7cFgTorqxZDYaew1Wqgfbd2ud9QqGPAkK2V" indicates that SHA256 is the hash function used to generate the hash value "ZTR5bcpQD7cFgTorqxZDYaew1Wqgfbd2ud9QqGPAkK2V".
Here are some differences between the approach of using trusty URIs and other related ideas as mentioned in the paper:
The same authors published a follow-up version to their ESWC paper ("Making digital artifacts on the web verifiable and reliable") in which they described in some detail how to generate trusty URIs on content of type RA for multiple RDF graphs and RB for a single RDF graph (RB was not included in the original paper). In addition, in this recent version, they graphically described the structure of the trusty URIs.
While calculating the hash value on the content of type F (byte-level file content) is a straightforward task, multiple steps are required to calculate the hash value on content of type R (RDF graphs), such as converting any serialization (e.g, N-Quads or TriG) into RDF triples, sorting of RDF triples lexicographically, serializing the graph into a single string, replacing newline characters with "\n", and dealing with self-references and empty nodes.
To evaluate their approach, the authors used the Java implementation to create trusty URIs for 156,026 of small structured data files (nanopublications) which are in different serialization format (N-Quads and TriX). By testing these files, again using the Java implementation, they all were successfully verified as they matched to their trusty URIs. In addition, they tested modified copies of these nanopublications. Results are shown in the figure below:

Examples of using trusty URIs:
[1] Trusty URI for byte-level content
Let say that I have published my paper on the web at http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.pdf, and somebody links to it or saves the link somewhere. Now, if I intentionally (or not) change the content of the paper, for example, by modifying some statistics, adding a chart, correcting a typo, or even replacing the PDF with something completely different (read about content drift), anyone downloads the paper after these changes by dereferencing the original URI will not be able to realize that the original content has been tampered with. Trusty URIs may solve this problem. For testing, I used Trustyuri-python, the Python implementation, to first generate the artifact code on the PDF file "tpdl-2015.pdf":
%python ProcessFile.py tpdl-2015.pdf
The file (tpdl-2015.pdf) is renamed to (tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf) containing the artifact code (FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao) as a part of its name -- in the paper, they call this file a trusty file. Finally, I published this trusty file on the web at the trusty URI (http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf). Anyone with this trusty URI can verify the original content using the the library Trustyuri-python, for example:
%python CheckFile.py http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf
Correct hash: FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao
As you can see, the output "Correct hash: FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao" indicates that the hash value in the
trusty URI is identical to the hash value of the content which means that this resource contains the correct and the desired content.
To see how the library detects any changes in the original content available at http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf, I replaced all occurrence of the number "61" with the number "71" in the content. Here is the commands I used to apply these changes:
%pdftk tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf output tmp.pdf uncompress
%sed -i 's/61/71/g' tmp.pdf
%pdftk tmp.pdf output tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf compress
The figures below show the document before and after the changes:
The library detected that the original resource has been changed:
$python CheckFile.py http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf
*** INCORRECT HASH ***
[2] Trusty URIs for RDF content
I downloaded this nanopublication serialized in XML from "https://github.com/trustyuri/trustyuri-java/blob/master/src/main/resources/examples/nanopub1-pre.xml":
This nanopublication (RDF file) can be transformed into a trusty file using:
$python TransformRdf.py nanopub1-pre.xml http://trustyuri.net/examples/nanopub1
The Python script "TransformRdf.py" performed multiple steps to transform this RDF file into the trusty file "nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml". The steps as mentioned above include generating RDF triples, sorting those triples, handling self-references, etc. The Python library used the second argument "http://trustyuri.net/examples/nanopub1", considered as the original URI, to manage self-references by replacing all occurrences of "http://trustyuri.net/examples/nanopub1" with "http://trustyuri.net/examples/nanopub1. " in the original XML file. You may have noticed that this ends with '.' and blank space. Once the artifact code is generated, the new trusty file is created "nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml". In this trusty file all occurrences of "http://trustyuri.net/examples/nanopub1. " are replaced with "http://trustyuri.net/examples/nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg#pubinfo". The trusty file is shown below:
To verify this trusty file we can use the following command which resulting in having "Correct hash" --the content is verified to be correct. Again, to handle self-references, the Python library replaces all occurrences of "http://trustyuri.net/examples/nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg#pubinfo" with "http://trustyuri.net/examples/nanopub1. " before recomputing the hash.
%python CheckFile.py nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml
Correct hash: RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg
Or by the following command if the trusty file is published on the web:
%python CheckFile.py http://www.cs.odu.edu/~maturban/nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml
Correct hash: RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg
What we are trying to do with trusty URIs:
We are working on a project, funded by the Andrew W. Mellon Foundation, to automatically capture and archive the scholarly record on the web. One part of this project is to come up with a mechanism through which we can verify the fixity of archived resources to ensure that these resources have not been tampered with or corrupted. In general, we try to collect information about the archived resources and generate manifest file. This file will then be pushed into multiple archives, so it can be used later. Herbert Van de Sompel, from Los Alamos National Laboratory, pointed to this idea of using trusty URIs to identify and verify web resources. In this way, we have the manifest files to verify archived resources, and trusty URIs to verify these manifests.
Resources:
--Mohamed Aturban
@prefix swan: < http://swan.mindinformatics.org/ontologies/1.2/pav.owl> .
@prefix cw: < http://conceptwiki.org/index.php/Concept>.
@prefix swp: <http://www.w3.org/2004/03/trix/swp-1/>.
@prefix : <http://www.example.org/thisDocument#> .
:G1 = { cw:malaria cw:isTransmittedBy cw:mosquitoes }
:G2 = { :G1 swan:importedBy cw:TextExtractor,
:G1 swan:createdOn "2009-09-03"^^xsd:date,
:G1 swan:authoredBy cw:BobSmith }
:G3 = { :G2 ann:assertedBy cw:SomeOrganization }
In addition to the two modules, they are planning to define new modules for more types of content (e.g., hypertext/HTML) in the future.
The example below illustrates the general structure of trusty URIs:
The artifact code, everything after r1, is the part that make this URI a trusty URI. The first character in this code (R) is to identify the module. In the example, R indicates that this trusty URI was generated on a RDF graph. The second character (A) is to specify any version of this module. The remaining characters (5..0) represents the hash value on the content. All hash values are generated by SHA-256 algorithm. I think it would be more useful to allow users to select any preferred cryptographic hash function instead of enforcing a single hash function. This might result in adding more characters to the artifact code to represent the selected hash function. InterPlanetary File System (IPFS), for example, uses Multihash as mechanism to prefix the resulting hash value with an id that maps to a particular hash function. Similar to trusty URIs, resources in the IPFS network are addressed based on hash values calculated on the content. For instance, the first two characters "Qm" in the IPFS address "/ipfs/QmZTR5bcpQD7cFgTorqxZDYaew1Wqgfbd2ud9QqGPAkK2V" indicates that SHA256 is the hash function used to generate the hash value "ZTR5bcpQD7cFgTorqxZDYaew1Wqgfbd2ud9QqGPAkK2V".
Here are some differences between the approach of using trusty URIs and other related ideas as mentioned in the paper:
- Trusty URIs can be used to identify and verify resources on the web while in systems like Git version control system, hash values are there to verify "commits" in Git repositories only. The same applies to IPFS where hashes in addresses (e.g., /ipfs/QmZTR5bcpQD7cFgTorqxZDYaew1Wqgfbd2ud9QqGPAkK2V) are used to verify files within the IPFS network only.
- Hashes in trusty URIs can be generated on different kinds of content while in Git or ni-URI, hash values are computed based on the byte level of the content.
- Trusty URIs support self-references (i.e., when trusty URIs are included in the content).
The same authors published a follow-up version to their ESWC paper ("Making digital artifacts on the web verifiable and reliable") in which they described in some detail how to generate trusty URIs on content of type RA for multiple RDF graphs and RB for a single RDF graph (RB was not included in the original paper). In addition, in this recent version, they graphically described the structure of the trusty URIs.
While calculating the hash value on the content of type F (byte-level file content) is a straightforward task, multiple steps are required to calculate the hash value on content of type R (RDF graphs), such as converting any serialization (e.g, N-Quads or TriG) into RDF triples, sorting of RDF triples lexicographically, serializing the graph into a single string, replacing newline characters with "\n", and dealing with self-references and empty nodes.
To evaluate their approach, the authors used the Java implementation to create trusty URIs for 156,026 of small structured data files (nanopublications) which are in different serialization format (N-Quads and TriX). By testing these files, again using the Java implementation, they all were successfully verified as they matched to their trusty URIs. In addition, they tested modified copies of these nanopublications. Results are shown in the figure below:

Examples of using trusty URIs:
[1] Trusty URI for byte-level content
Let say that I have published my paper on the web at http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.pdf, and somebody links to it or saves the link somewhere. Now, if I intentionally (or not) change the content of the paper, for example, by modifying some statistics, adding a chart, correcting a typo, or even replacing the PDF with something completely different (read about content drift), anyone downloads the paper after these changes by dereferencing the original URI will not be able to realize that the original content has been tampered with. Trusty URIs may solve this problem. For testing, I used Trustyuri-python, the Python implementation, to first generate the artifact code on the PDF file "tpdl-2015.pdf":
%python ProcessFile.py tpdl-2015.pdf
The file (tpdl-2015.pdf) is renamed to (tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf) containing the artifact code (FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao) as a part of its name -- in the paper, they call this file a trusty file. Finally, I published this trusty file on the web at the trusty URI (http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf). Anyone with this trusty URI can verify the original content using the the library Trustyuri-python, for example:
%python CheckFile.py http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf
Correct hash: FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao
As you can see, the output "Correct hash: FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao" indicates that the hash value in the
trusty URI is identical to the hash value of the content which means that this resource contains the correct and the desired content.
To see how the library detects any changes in the original content available at http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf, I replaced all occurrence of the number "61" with the number "71" in the content. Here is the commands I used to apply these changes:
%pdftk tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf output tmp.pdf uncompress
%sed -i 's/61/71/g' tmp.pdf
%pdftk tmp.pdf output tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf compress
The figures below show the document before and after the changes:
 |
| Before changes |
 |
| After changes |
$python CheckFile.py http://www.cs.odu.edu/~maturban/pubs/tpdl-2015.FAofcNax1YMDFakhRQvGm1vTOcCqrsWLKeeICh9gqFVao.pdf
*** INCORRECT HASH ***
[2] Trusty URIs for RDF content
I downloaded this nanopublication serialized in XML from "https://github.com/trustyuri/trustyuri-java/blob/master/src/main/resources/examples/nanopub1-pre.xml":
This nanopublication (RDF file) can be transformed into a trusty file using:
$python TransformRdf.py nanopub1-pre.xml http://trustyuri.net/examples/nanopub1
The Python script "TransformRdf.py" performed multiple steps to transform this RDF file into the trusty file "nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml". The steps as mentioned above include generating RDF triples, sorting those triples, handling self-references, etc. The Python library used the second argument "http://trustyuri.net/examples/nanopub1", considered as the original URI, to manage self-references by replacing all occurrences of "http://trustyuri.net/examples/nanopub1" with "http://trustyuri.net/examples/nanopub1. " in the original XML file. You may have noticed that this ends with '.' and blank space. Once the artifact code is generated, the new trusty file is created "nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml". In this trusty file all occurrences of "http://trustyuri.net/examples/nanopub1. " are replaced with "http://trustyuri.net/examples/nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg#pubinfo". The trusty file is shown below:
To verify this trusty file we can use the following command which resulting in having "Correct hash" --the content is verified to be correct. Again, to handle self-references, the Python library replaces all occurrences of "http://trustyuri.net/examples/nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg#pubinfo" with "http://trustyuri.net/examples/nanopub1. " before recomputing the hash.
%python CheckFile.py nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml
Correct hash: RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg
Or by the following command if the trusty file is published on the web:
%python CheckFile.py http://www.cs.odu.edu/~maturban/nanopub1.RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg.xml
Correct hash: RAq2P3suae730r_PPkfdmBhBIpqNO6763sJ0yMQWm6xVg
What we are trying to do with trusty URIs:
We are working on a project, funded by the Andrew W. Mellon Foundation, to automatically capture and archive the scholarly record on the web. One part of this project is to come up with a mechanism through which we can verify the fixity of archived resources to ensure that these resources have not been tampered with or corrupted. In general, we try to collect information about the archived resources and generate manifest file. This file will then be pushed into multiple archives, so it can be used later. Herbert Van de Sompel, from Los Alamos National Laboratory, pointed to this idea of using trusty URIs to identify and verify web resources. In this way, we have the manifest files to verify archived resources, and trusty URIs to verify these manifests.
Resources:
- Kuhn, T., Dumontier, M.: Trusty URIs: Verifiable, immutable, and permanent digital artifacts for linked data. Proceedings of European Semantic Web Conference (ESWC) pp. 395–410 (2014). [video, slides shown below]
- Kuhn, Dumontier. "Making Digital Artifacts on the Web Verifiable and Reliable." arXiv preprint arXiv:1507.01697 (2015)
- Kuhn, Tobias. "nanopub-java: A Java Library for Nanopublications." arXiv preprint arXiv:1508.04977 (2015)
- Kurian, S.P., Vishnu S.S.,: Distributed digital artifacts on the semantic web. International Journal of Computer Applications Technology and Research pp. 99–103 (2015)
- IPFS and Multihash
- Klein, M., Van de Sompel, H., Sanderson, R., Shankar, H., Balakireva, L., Zhou, K., Tobin, R.: Scholarly context not found: one in five articles suffers from reference rot. PLoS One 9(12), e115,253 (2014)
--Mohamed Aturban
Comments
Post a Comment