2013-07-09: Archive.is Supports Memento

There's a lot to like about Archive.is, a recent entry in the page-at-a-time personal web archiving space: the simple search/upload interface, the bookmarklet for easily pushing pages into the archive while reading, the thumbnails (and full-sized images) of captured pages, how it handles Javascript, etc. But now there is an additional reason: Archive.is natively supports Memento and is now included in the Memento aggregators at LANL and ODU.
Archive.is is similar to WebCite in that it archives a single page when a user requests that it be archived. This is different from crawlers at, for example, the Internet Archive and Archive-It, which crawl the web all the time, archiving pages as they go along. These archives represent different, complementary strategies for crawling the web:
- Archive.is, WebCite: single page, on demand archiving, won't crawl the entire site, but you control when and what gets archived
- Internet Archive, Archive-It: repeatedly crawls entire sites, but harder to influence what is archived and when it is archived
http://archive.is/{URI-R}
Where URI-R is an "original resource" in Memento terms. For example:
http://archive.is/http://www.cs.odu.edu/~mln/
Produces a listing of thumbnails for each memento (archived web page):

Clicking on the 2nd thumbnail produces the memento with a well-instrumented archival banner with the Memento-Datetime (i.e., the archival capture time), links to sharing utilities, backlinks, pre-built searches for related pages in Archive.is, etc.:
http://archive.is/20130621194047/http://www.cs.odu.edu/~mln/
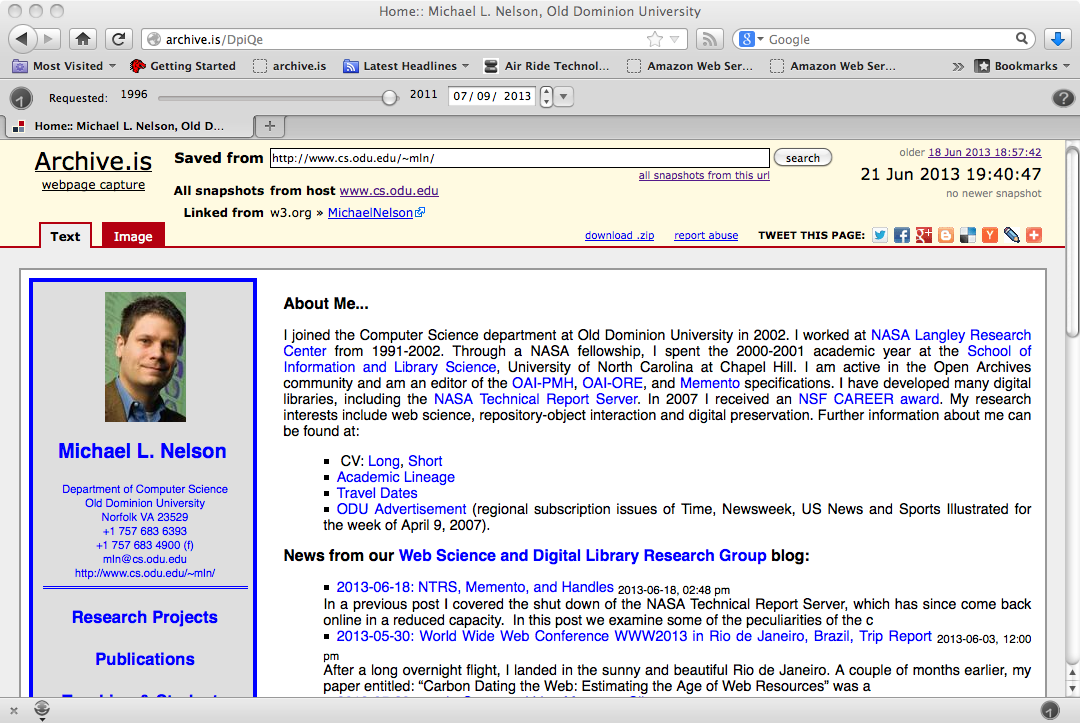
Scrolling down in the same page shows another feature that Archive.Is does well: capturing the Javascript and keeping from reaching out to the live web (see Justin's post "Zombies in the Archives" for a good discussion of this problem). In my web page I have the Twitter widget that shows my last 20 tweets; the picture below shows that the widget does not reach out to the live web and grab current tweets -- the last tweet in this memento will forever be June 19, 2013.

And just in case there is question about rendering old pages in new browsers, Archive.is renders a 1024X768 png of the page at the time of capture (where http://archive.is/DpiQe/ is a shortened form of http://archive.is/20130621194047/http://www.cs.odu.edu/~mln/):
http://archive.is/DpiQe/image

The search interface works well for showing pages from the same site too, using "*" as a wild card. Here's screen shot for:
http://archive.is/http://www.cs.odu.edu/*

Notice how it suppresses some of the thumbnails for the scalability of the UI.
I mentioned above that Archive.is natively supports Memento. The service points for the TimeGate and TimeMap functionality are:
http://archive.is/timegate/{URI-R}
http://archive.is/timemap/{URI-R}
And since there can never be enough raw HTTP in this blog, here's a curl request to the TimeGate for http://www.bbc.co.uk/:
And here's a curl request for a TimeMap for my home page:
And the Memento headers returned from a single memento:
Also as mentioned above, Archive.is has been included in the Memento aggregators. Here's an aggregate TimeMap for Hany's home page, showing results from the Internet Archive and Archive.is:
One restriction Archive.is has is that Memento functionality is only available for top-level URIs and not embedded URIs. This means that although Archive.is has a memento for:
http://www.cs.odu.edu/~mln/images/mln-ad-100x130.jpg
{kind=link}
stored at:
http://img.archive.is/DpiQe/7e9dcf3bab7c72c6516ef26d431a7b48d562599a.jpg
{kind=link}
It does not store a mapping from the former to the latter, so these URIs will not produce the expected results:
http://archive.is/http://www.cs.odu.edu/~mln/images/mln-ad-100x130.jpg
{kind=link}
http://archive.is/timegate/http://www.cs.odu.edu/~mln/images/mln-ad-100x130.jpg
{kind=link}
http://archive.is/timemap/http://www.cs.odu.edu/~mln/images/mln-ad-100x130.jpg
{kind=link}
This means that Archive.is can't be used to supplement top-level mementos from other archives that are missing embedded images, stylesheets, etc.
Regardless, there is a tremendous amount to like about how Archive.is, especially its ease of use. We also appreciate how quickly the staff there implemented Memento for their archive when asked. Use their bookmarklet, download MementoFox (or the Android & iOS client, or mcurl, or use the BL interface, or...), and you'll have easy access to over a dozen public web archives, now including Archive.is.
--Michael
Comments
Post a Comment