2011-06-23: How Much of the Web is Archived?
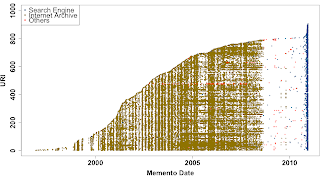
There are many questions to ask about web archiving and digital preservation - why is archiving important? what should be archived? what is currently being archived? how often should pages be archived? The short paper "How Much of the Web is Archived?" (Scott G. Ainsworth, Ahmed AlSum, Hany SalahEldeen, Michele C. Weigle, and Michael L. Nelson), published at JCDL 2011, is our first step at determining to what extent the web is being archived and by which archives. To address this question, we sampled URIs from four sources to estimate the percentage of archived URIs and the number and frequency of archived versions. We chose 1000 URIs from each of the following sources: Open Directory Project (DMOZ) - sampled from all URIs (July 2000 - Oct 2010) Delicious - random URIs from the Recent Bookmarks list Bitly - random hash values generated and dereferenced search engine caches ( Google , Bing , Yahoo! ) - random sample of URIs from queries of 5-grams (using Google...