2025-05-21: Paper Summary: "AccessMenu: Enhancing Usability of Online Restaurant Menus for Screen Reader Users"


The ACM Web4All Conference (W4A) is the premier venue for research focused on web accessibility. It brings together a diverse community committed to making the web inclusive for users of all abilities and backgrounds. This year, the 22nd International Web for All Conference (W4A 2025) was held at the ICC Sydney: International Convention & Exhibition Centre in Sydney, Australia, from April 28–29, 2025. In this blog post, I highlight my work titled “AccessMenu: Enhancing Usability of Online Restaurant Menus for Screen Reader Users,” which addresses the accessibility challenges faced by blind and visually impaired (BVI) users when navigating image-based restaurant menus online.

Motivation:
Ordering food online has become a routine part of modern life, offering speed, convenience, and variety. Yet for BVI individuals, accessing restaurant menus on the web remains a significant barrier. Many restaurants present their menus as images or PDFs, formats that are largely incompatible with screen readers. As a result, tasks such as browsing dishes, identifying ingredients, or comparing prices become laborious and error-prone. While OCR tools and AI-powered assistants attempt to help, they often misinterpret layout structures, skip context, or generate misleading information. These limitations impact users' ability to make informed choices and reduce confidence in digital interactions. To address this, we introduce AccessMenu, a browser extension that converts visual menus into screen reader-friendly interfaces and supports natural language queries for efficient menu navigation.
Background and Related Work:
Prior research in screen reader accessibility has led to the development of tools aimed at simplifying web interaction for BVI users. These include screen reader enhancements, AI-based captioning systems, web automation tools, and voice assistants that allow for more efficient navigation of digital content. Many of these tools focus on improving interaction with standard web elements such as text, forms, or images with alt-text. Recent advances in multimodal models have also enabled basic question-answering over documents and forms, and models like LayoutLM and Donut have demonstrated success in parsing structured data from visually rich documents.
However, these solutions fall short when applied to restaurant menus, which often lack structured HTML markup and rely heavily on spatial cues, icons, and dense visual formatting. OCR-based tools frequently produce disjointed outputs that confuse screen readers and users alike. General-purpose AI assistants may hallucinate or misclassify menu content due to a lack of domain-specific grounding. AccessMenu builds on this foundation by tailoring its design specifically for restaurant menus. It leverages multimodal large language models with customized prompts to extract menu content, interpret layout-dependent information, and present it in a linear, queryable format optimized for screen reader navigation.
Uncovering Usability Issues with Menu Navigation:
To better understand the challenges BVI users face with online restaurant menus, we conducted a semi-structured interview study with 12 blind participants, all proficient in screen reader use. Participants shared their food ordering habits, menu navigation strategies, and frustrations with existing assistive tools. Interviews were conducted remotely and recorded with consent, followed by qualitative analysis using open and axial coding to identify recurring themes and insights that shaped our design approach.
Participants consistently described the limitations of OCR-based tools, citing difficulty in mentally reconstructing menu layouts from screen reader outputs, confusion caused by inconsistent text order, and a reliance on external help to make decisions. Several noted that current AI assistants often generated misleading or incorrect responses due to lack of contextual awareness. Key design insights included the need for a linear presentation of menu items, centralized item information, and support for natural language queries to filter or search menus. These findings directly informed the structure and features of AccessMenu.
AccessMenu Design
Key Features
AccessMenu introduces two core features that address the barriers identified in our user study: linear menu rendering and natural language query support.
Linear Menu Rendering: Recognizing that fragmented OCR outputs hinder screen reader navigation, AccessMenu presents extracted menu items in a clean, linear layout. Each item is structured with its name, description, price, and any applicable dietary indicators in one place, making it easier for users to follow and understand. The layout supports intuitive keyboard navigation, allowing users to move through items sequentially with minimal effort.
Natural Language Query Support: To reduce the burden of manually scanning the entire menu, AccessMenu includes a query interface where users can type or speak natural language questions. For example, users can ask for "gluten-free desserts under $10" or "spicy vegetarian appetizers." The system processes these queries using a multimodal language model, returning only the relevant subset of items while preserving accessibility within the interface.
Architecture
The architecture of AccessMenu is organized into two main stages: information extraction and query processing. These are supported by a lightweight front-end browser extension and a back-end server that hosts the multimodal language model pipeline.
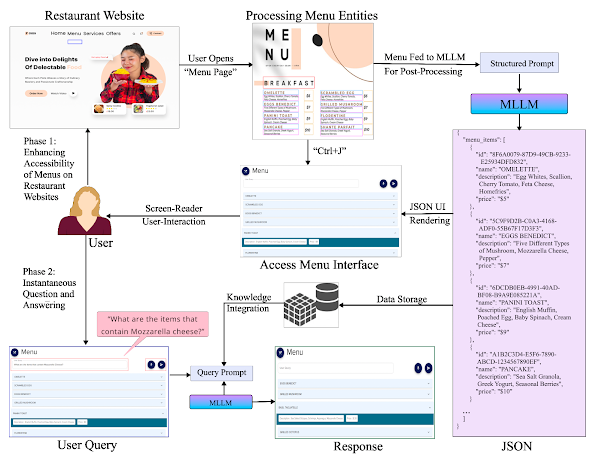
Figure 2 Venkatraman et al.: System architecture of AccessMenu comprising two key phases: (a) Information Extraction Phase, where the system captures visual menu images and uses a multimodal language model to generate a structured JSON representation of the menu content; and (b) Question Answering Phase, where user-issued natural language queries are processed against the structured data to return accessible, filtered results rendered in a screen-reader-friendly format.
Information Extraction Phase: When a user activates AccessMenu on a restaurant website, the extension captures menu images from the page. These are sent to a back-end server, where a multimodal language model is prompted with a custom-designed Chain-of-Thought (CoT) prompt. This prompt instructs the model to parse the image for key content such as dish names, prices, descriptions, and icons, and then structure this content as a JSON menu model. The model is guided to handle icons, legends, and visual layout cues that are often overlooked by conventional OCR methods.

To evaluate the extraction quality, we curated a dataset of 50 diverse restaurant menus and manually annotated their ground truth structure. We then compared the output of three leading models: GPT-4o-mini, Claude 3.5 Sonnet, and LLaMA 3 Vision. GPT-4o-mini achieved the highest performance across entity recognition (F1 = 0.80), relationship modeling (F1 = 0.73), and structural organization (F1 = 0.84), and was thus integrated into the system.
Query Processing Phase: Once the JSON menu model is generated, it serves as the knowledge base for user queries. The user can issue a natural language query via text or voice, which is again sent to the model using a second CoT prompt. This prompt provides reasoning steps and few-shot examples to ensure the model grounds its responses strictly in the extracted menu data. The system returns a filtered JSON list of relevant items, which is dynamically rendered on the screen in an accessible format.
Query evaluation was conducted by collecting freeform questions from users across five sample menus. Each menu session allowed users to explore and query for 10 minutes. The resulting responses were compared to annotated answers, yielding an overall F1 score of 0.83. Most errors were due to vague query wording or voice transcription issues with complex item names.
User Interface: The AccessMenu interface features a structured layout designed to support seamless screen reader interaction. At the top, users find a query field for typing natural language questions, a voice-input button for spoken queries, and a submit button. Below this, menu items are displayed in a collapsible accordion format, with each item acting as a header that can be expanded using the Enter key to reveal full details, including descriptions, prices, and dietary indicators. The interface supports intuitive navigation using TAB, SHIFT+TAB, and ARROW keys. It incorporates ARIA attributes and tab-indexing to preserve logical focus order and ensure compatibility with common screen readers. The design is optimized for accessibility and ease of use, enabling even novice screen reader users to explore and interact with menus independently.
Modularity in Implementation: The back-end is built using Django and containerized with Docker for consistent deployment. The language model pipeline is managed via LangChain, enabling modular integration of different LLMs. While GPT-4o-mini was used for our evaluations, AccessMenu is designed to accommodate future models with improved reasoning and latency characteristics.
Evaluation
To assess the effectiveness of AccessMenu, we conducted a comprehensive user study comparing it with an existing screen reader-based OCR tool. This evaluation aimed to measure both the functional improvements and subjective experiences offered by AccessMenu across realistic food ordering scenarios.
Participants and Study Design: We conducted a comparative evaluation study with 10 blind screen reader users to assess the usability of AccessMenu in real-world browsing scenarios. Participants were recruited through accessibility mailing lists and community forums and represented a diverse range of ages and screen reader proficiency levels. The study followed a within-subjects design, comparing AccessMenu against a baseline method using JAWS Convenient OCR.
Procedure: Data Collection and Analysis: Participants completed two food ordering tasks on randomly assigned restaurant websites using each interface. They were asked to locate specific menu items, compare prices, and answer a set of guided comprehension questions. Interaction logs, task completion times, and user errors were recorded. After each condition, participants filled out the System Usability Scale (SUS) and NASA-TLX questionnaires, followed by a semi-structured interview. Quantitative data was analyzed using paired t-tests, while interviews were thematically coded.
Quantitative Results: AccessMenu significantly outperformed the baseline across all usability metrics. SUS scores improved from a mean of 52.5 (JAWS OCR) to 75.1 (AccessMenu). NASA-TLX scores indicated reduced cognitive load, dropping from 68.2 to 47.5. Task success rates improved from 58% to 89%, and average task completion time decreased by 36%. Error rates also declined, especially for multi-attribute queries.
Qualitative Feedback: Participants described AccessMenu as easier to follow, less frustrating, and more empowering. They appreciated the structured layout and the ability to filter menus using natural language. Several noted that it was the first time they felt fully in control when browsing visual menus independently. Some suggestions included improving the clarity of voice input feedback and adding shortcuts for faster navigation.
Discussion
The evaluation findings point to concrete directions for future enhancement. The effectiveness of the structured layout and natural language queries highlights the potential for expanding AccessMenu to platform-wide filtering i.e allowing users to issue global dietary or preference-based queries across multiple restaurants. This would align with participants’ interest in scaling the system beyond single menus to support comparison shopping or broader food discovery.
The request for improved voice feedback and faster navigation interfaces directly informs the development of personalized filtering preferences. Customizable query shortcuts, auditory confirmations, and persistent user profiles could reduce repetitive input and support more efficient interactions. Together, these enhancements can strengthen AccessMenu’s role not just as a menu reader but as a personalized decision-making assistant for food ordering.
However, the study also surfaced areas for improvement. Voice input, while appreciated, occasionally caused confusion due to ambiguous transcription feedback. Users expressed interest in additional keyboard shortcuts and auditory cues to streamline interactions further. These insights suggest that even well-designed accessible systems benefit from iterative refinements based on lived user experience. The positive reception and feedback underscore the potential of AccessMenu to support broader deployment and inspire similar domain-specific assistive tools.
Limitations
AccessMenu currently supports only English-language menus and is limited to desktop web environments.
The evaluation was conducted with a small sample size; broader studies are needed to capture variability in user needs.
The system relies on cloud-based LLMs, which may introduce latency and are dependent on stable internet access.
Voice input, while useful, can suffer from transcription inaccuracies, particularly with uncommon item names.
Current design assumes menus are presented as single high-quality images; performance may degrade with low-resolution or cluttered layouts.
Menu legends and icons are interpreted heuristically and may not generalize well across diverse visual styles.
Conclusion
AccessMenu demonstrates how domain-specific applications of multimodal language models can meaningfully advance web accessibility. By transforming complex visual menus into accessible, structured, and interactive formats, the system enables BVI users to navigate restaurant menus with greater ease and independence. The evaluation highlights clear usability improvements over conventional tools, and user feedback reinforces the importance of adaptive, personalized features. While limitations remain, particularly around language support and real-world variability, the foundation laid by AccessMenu offers a promising path forward. Future developments focused on personalization, multilingual access, and broader integration into food ordering platforms can further amplify its impact. Ultimately, AccessMenu represents a step toward more inclusive digital environments, where accessibility is not an afterthought but a core design principle.
References
Venkatraman, N., Nayak, A. K., Dahal, S., Prakash, Y., Lee, H.-N., & Ashok, V. (2025, April). AccessMenu: Enhancing Usability of Online Restaurant Menus for Screen Reader Users. In Proceedings of the 22nd International Web for All Conference (W4A 2025). ACM. Preprint
- AKSHAY KOLGAR NAYAK @AkshayKNayak7
Comments
Post a Comment